



 本文解释了个税“前低后高、逐渐增加”的现象,源于2018年后的累计预扣法。当薪资增加,税率会跳档,导致个税显著增长。此外,文章还提到了年终奖的计税方式,从2022年起,年终奖需并入当年综合所得计算个税,影响员工的实际收入。
本文解释了个税“前低后高、逐渐增加”的现象,源于2018年后的累计预扣法。当薪资增加,税率会跳档,导致个税显著增长。此外,文章还提到了年终奖的计税方式,从2022年起,年终奖需并入当年综合所得计算个税,影响员工的实际收入。
点击上方“Github爱好者社区”,选择星标
回复“资料”,获取小编整理的一份资料来源丨互联网坊间八卦
这是前几天脉脉榜三的一则帖子。

原贴是这么说的:
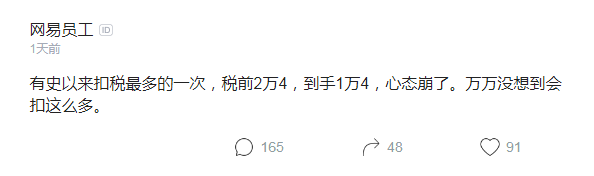
有史以来扣税最多的一次,税前2万4,到手1万4,心态崩了。万万没想到会扣这么多。
网帖发出后,引发了网友的围观、转载和评论。笔者把一些高赞的回答也搬出来给大家瞅瞅。
体制内优势出来了吧,房补26%,年金双边12%,一共38%,这部分不交税,省了太多的税了,实际收入不比互联网差到哪,性价比互联网远不如。
我25k税前,到手1.7,公积金12%。这还是在上半年有加班费早就触发更高税率的前提下。我不信你低1k,到手能少3k。
很多人想不明白,我公司就是低底薪高公积金高年终奖的国企,税后收入比底薪高的可强太多了。可惜结果就是大家找工作都看重月薪。
工资没变化,但个税突然多了很多,这是什么原因?难道是公司有问题?算错了?
回答下方除了骂的、断章取义的、混淆概念的,没有任何一点有价值的回答。
笔者就今天这个热榜话题,来给大家解答一下。
解答这个问题,笔者建议各位先去了解一下关于个税“前低后高、逐渐增加”这个说法。
为什么会有这个说法?
自2018年10月起,个人所得税改革进入过渡期,工资薪金所得的基本减除费用调整为5000元,并适用新的个人所得税税率表,将年度税率表按月换算,按照月应纳税所得额适用不同的税率。
“前低后高、逐渐增加”这个规律就是因为由原来的按月扣税改为累计预扣。
什么叫做累计预扣?
我们还是用白话来说,也就是随着我们职场人的薪资增加,相对应的税率从低到高。只要达到限定数额就会产生税率跳档,于是,个人扣税也就越来越高了。
具体是怎么算?笔者把国家税务总局的个税预扣预缴方法给你搬过来。
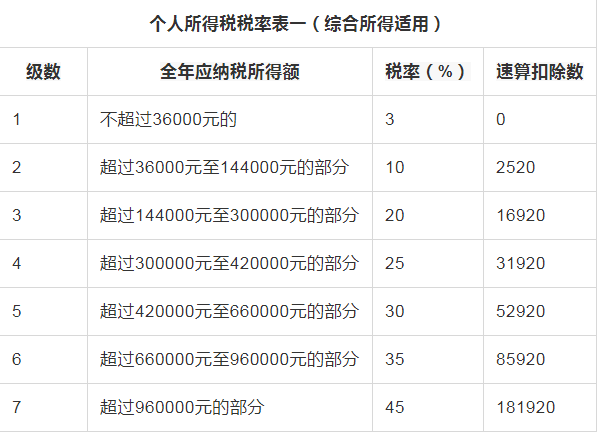
累计预扣法的计算公式为:
本期应预扣预缴税额=(累计预扣预缴应纳税所得额×预扣率-速算扣除数)-累计减免税额-累计已预扣预缴税额
累计预扣预缴应纳税所得额=累计收入-累计免税收入-累计减除费用-累计专项扣除-累计专项附加扣除-累计依法确定的其他扣除
可能很多人还是看不明白,那么,笔者就拿这位网易的网友例子,再给大家说白一点:
你刚跳槽进网易,你薪资为24000,从五险一金预算下来,一个月大概在3000-5000元,如果有房贷跟子女教育的话,可以申请“专项附加扣除”,按照本期应预扣预缴税额公式算下来,一个月个税也就是240-300之间。
按照2018年10月前的政策,一年下来缴税也就是3000-5000左右。
但我们用新的个人所得税税率累计预扣算下来,就是:
套用上面公式算下来,前几个月薪资少,累计预扣预缴应纳税所得额36000元以下是第一档,税率只有3%。半年后年薪进入第二档,税率就变成了10%,12g个月后,28万的年薪预扣税额就达到了税率20%这一档。
不知道各位看懂了吗?这就是很多职场人突然扣税增长几倍的原因。
按照累计预扣法,你月薪在不变的前提下,我们职场人多数在新入一家企业的前五个月个税都是按照3%扣缴,而高薪行业者多数在半年后就进入了“税率跳档”时期,所以,个税就会成倍增长。虽然看似税交得多,但也意味着他的收入更多。
当然,薪资累计预扣是导致个税增加的一方面,还有一个原因就是年终奖。
互联网公司,有些公司习惯年底发放年终奖,但也有很多企业喜欢在第二年的年中发放年终奖。
说到年终奖,笔者就再提醒各位一句了。自2022年1月1日起,全年一次性奖金就也要并入当年综合所得,也要计算缴纳个人所得税。

相关政策依据:财税[2018]164号
关于全年一次性奖金、中央企业负责人年度绩效薪金延期兑现收入和任期奖励的政策
(一)居民个人取得全年一次性奖金,符合《国家税务总局关于调整个人取得全年一次性奖金等计算征收个人所得税方法问题的通知》(国税发[2005]9号)规定的,在2021年12月31日前,不并入当年综合所得,以全年一次性奖金收入除以12个月得到的数额,按照本通知所附按月换算后的综合所得税率表(以下简称月度税率表),确定适用税率和速算扣除数,单独计算纳税。
计算公式为:
应纳税额=全年一次性奖金收入×适用税率-速算扣除数
居民个人取得全年一次性奖金,也可以选择并入当年综合所得计算纳税。
自2022年1月1日起,居民个人取得全年一次性奖金,应并入当年综合所得计算缴纳个人所得税。
应纳税额=全年一次性奖金收入×适用税率-速算扣除数

居民个人取得全年一次性奖金,也可以选择并入当年综合所得计算纳税。
自2022年1月1日起,居民个人取得全年一次性奖金,应并入当年综合所得计算缴纳个人所得税。
也就是说,今年年内取得的年终奖,缴纳个税有两种计税方式,即单独计税和合并计税。到了明年取得的收入,就只有合并计税一种方式了。
年终奖扣税方式1月1日起施行,打工人你还好吗?
好啦,今天的分享就到这儿啦,我们下次见啦~
GitHub原创推荐• 尼玛,Github上最邪恶的开源项目了!未满18或者女孩子勿进哦~• GitHub标星4K+,前字节跳动工程师开源的刷题笔记...• GitHub上这个仿京东电商项目强势开源,前端,后台,数据库等统统都有!• GitHub 开发者自制火星车,教程全面开源!网友:这才是大佬!关注「Github爱好者社区」加星标,每天带你逛Github好玩的项目
















 3641
3641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









