




 本文介绍了一种使用C语言快速处理大型字典文件的方法,对比脚本语言,C语言在处理大量数据时表现出更高的效率,尤其适用于无线密码破解中字典的优化。
本文介绍了一种使用C语言快速处理大型字典文件的方法,对比脚本语言,C语言在处理大量数据时表现出更高的效率,尤其适用于无线密码破解中字典的优化。
前阵子在研究暴力破解,在使用kali linux的aircrack-ng 无线攻击攻击wifi抓取到握手包时,需要使用字典进行暴力破解,能否破解成功除了一定的运气之外还需要一款强大的字典。我在百度上以及github上下载了两个字典。
大小分别为1.07GB(jikefeng.txt) 和 8.84M(top10W.txt),在使用这两个字典时发现里面的密码长度都各有不同,但是wifi密码都是要求大于等于8个字符的。为了破解效率我决定把这两个字典中不合符wifi密码长度的密码都给剔除掉。
手动处理显然不切实际,接下来我打算编写一个简单的程序来解决这个问题:把这两个文件当中的大于等于8个字符的密码提取出来,重新生成我需要的字典。考虑到代码越简单越好,我决定使用shell完成,代码如下:
getStringN.sh
#--------------------------------------------
#该脚本用于从制定文本中分离出制定长度字符串
#@: $1 要分离的原始文本
#@: $2 保存分离出来的字符串
#@:$3 指定字符串长度
#--------------------------------------------
if [ $# -ne 3 ];then
echo "Usage: $0 [src] [dest] [count] "
exit 1
fi
if [ ! -f $1 ];then
echo "The $1 file does not exist!"
exit 1
fi
if [ -f $2 ];then
echo "The $2 file exist,please specify a new file."
exit 1
fi
expr $3 + 0 &>/dev/null
if [ $? != 0 ];then
echo "$3 is not a num."
exit 1
fi
echo "-----begin-----"
while read line
do
if [ ${#line} -ge $3 ];then
echo ${line} >> $2
fi
done < $1
echo "------end------"
关键代码就只有begin 到 end之间的6行,其他都是说明以及错误判断等。
接下来运行脚本:
sh getStringN.sh top10W.txt top10W_for_wifi.txt 8
参数说明:运行getStringN.sh脚本,top10W.txt作为输入,密码长度大于等于8字符的输出到top10W_for_wifi.txt中,运行如下动图:
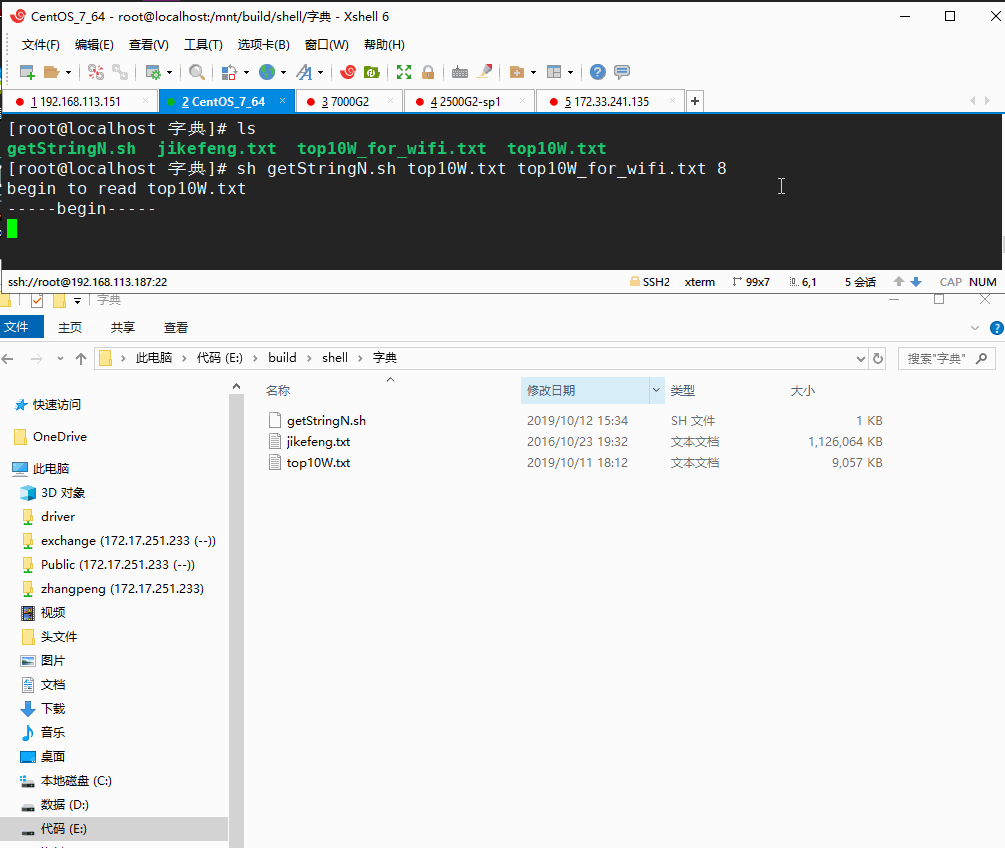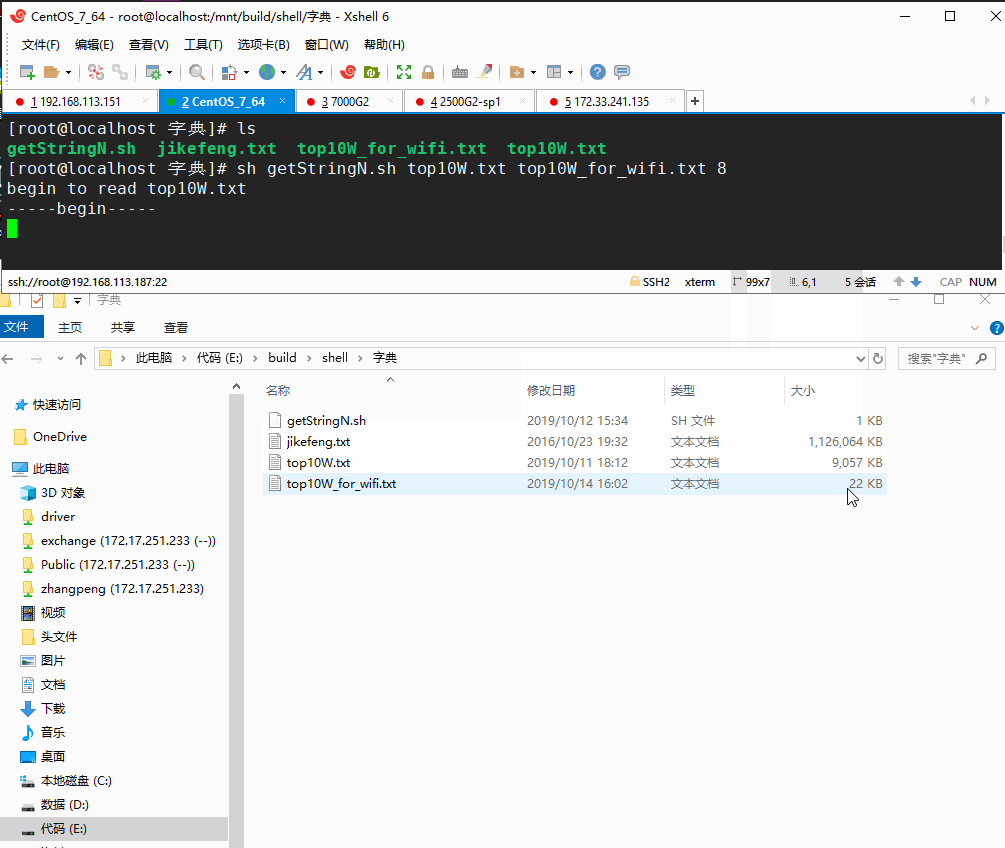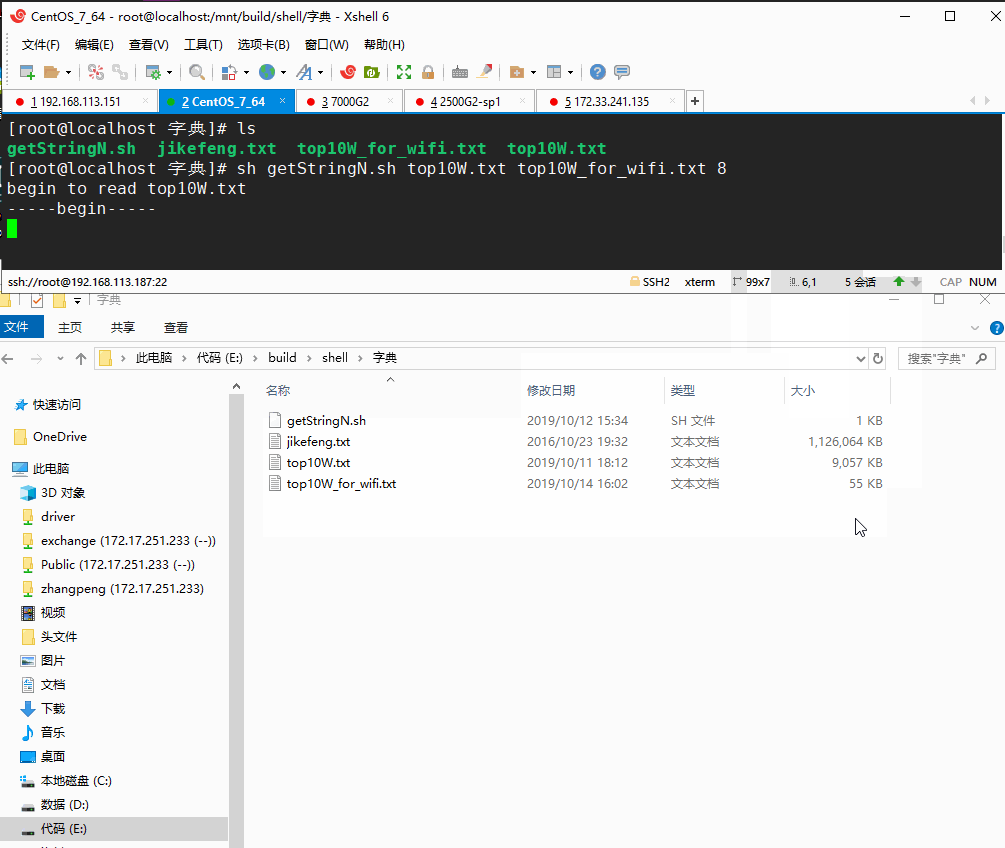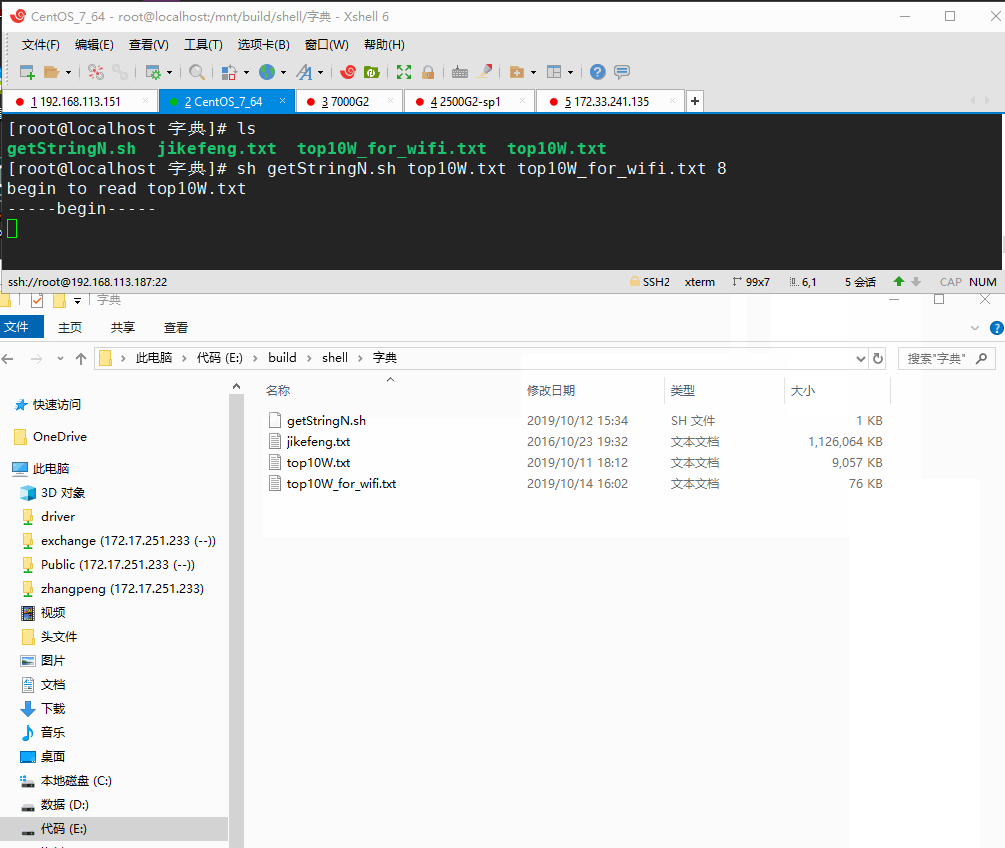
确实可行,只是速度很慢,处理速度大概只有几KB每秒,用于处理很小的文本尚可,稍微大一点的就很耗时,初步估算我处理top10W.txt(8MB左右)的花了一个多小时,简直不能忍!那么如果处理大于1GB的jikefeng.txt 文本简直不敢想象。
慢是脚本语言的主要缺点之一,换成Python也好不到哪里去。为了提高效率,我打算还是用C 语言实现一遍,代码如下:
#include<stdio.h>
#include<stdlib.h>
int str_len(char* buff)
{
char *p = buff;
int i = 0;
while ((*p != '\n') && (*p != '\r') && (*p != ' ') && (*p != '\0') )
{
p++;
i++;
}
return i;
}
int main(int argc, char **argv)
{
char *file_name;
char *save_name;
int count;
char buff[128];
int string_len=0;
int i = 0 , j = 0;
FILE *fp, *fp_save;
if(argc != 4)
{
printf("Usage: %s [src] [dest] [count]\n",argv[0]);
return 0;
}
file_name=argv[1];
save_name=argv[2];
count=atoi(argv[3]);
if (count <= 0)
{
printf("The fourth argument must be an integer greater than 0\n");
return -1;
}
fp = fopen(file_name, "r");
if (fp == NULL )
{
printf("open file fail\n");
return -1;
}
fp_save = fopen(save_name, "w");
if(fp_save == NULL)
{
printf("File already exist, choose another\n");
return 1;
}
printf("-------begin---------\n");
while(!feof(fp) && !ferror(fp))
{
i++;
fgets(buff,sizeof(buff),fp);
string_len = str_len(buff);
if(string_len >= count)
{
j++;
fputs(buff,fp_save);
}
}
printf("total: %d\n",i);
printf("gether than %d: %d\n",count,j);
printf("---------end---------\n");
fclose(fp);
fclose(fp_save);
return 0;
}
由于功能很简单,代码也很简单,编译:
gcc getStringN.c -o getStringN
由于使用的是C标准io库,不仅可以在linux下编译运行,在Windows下也可以编译运行。
接下来看下处理速度: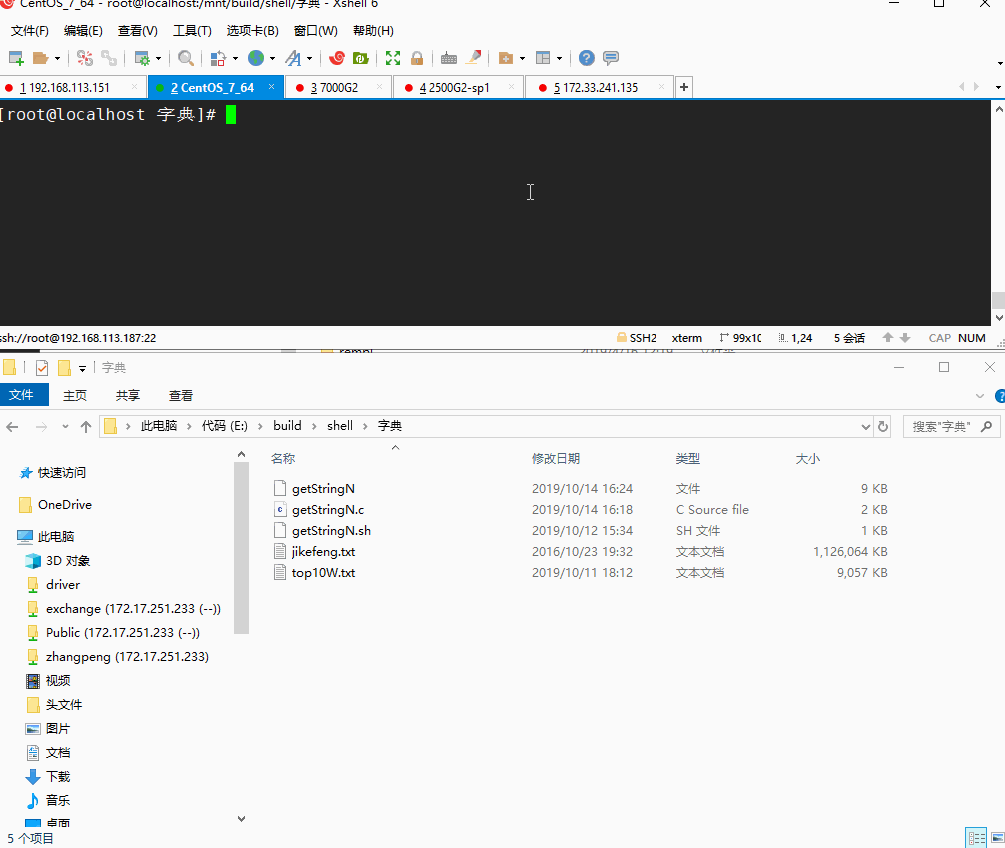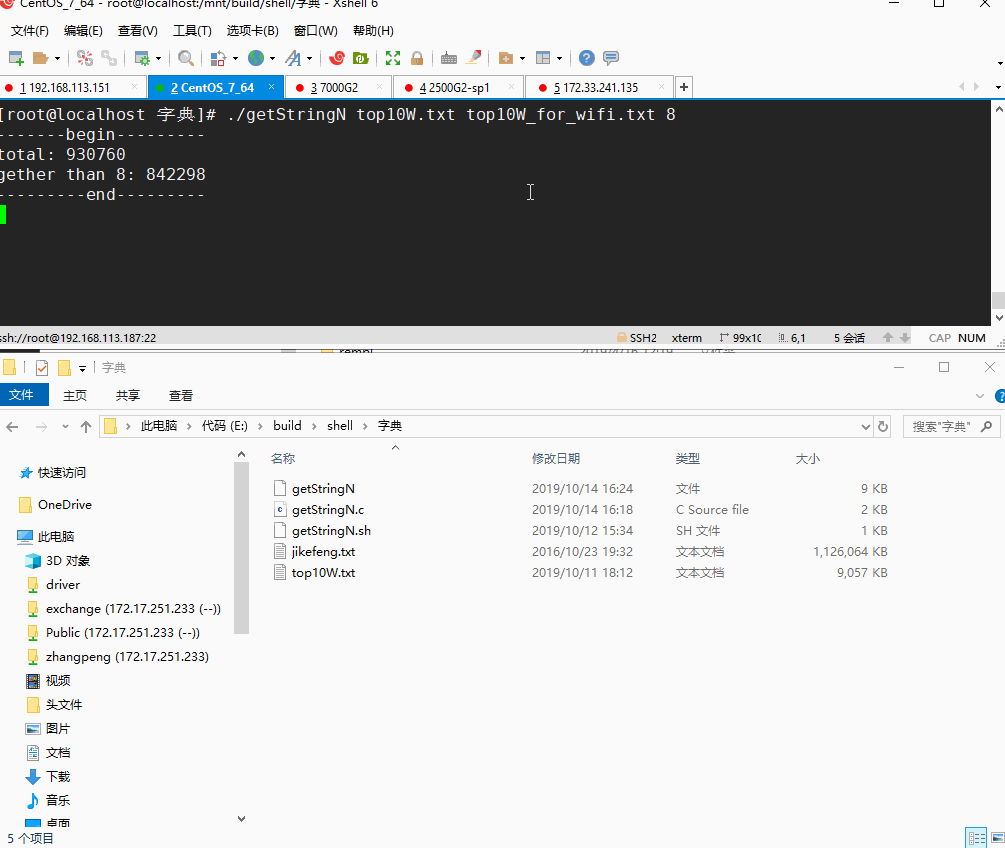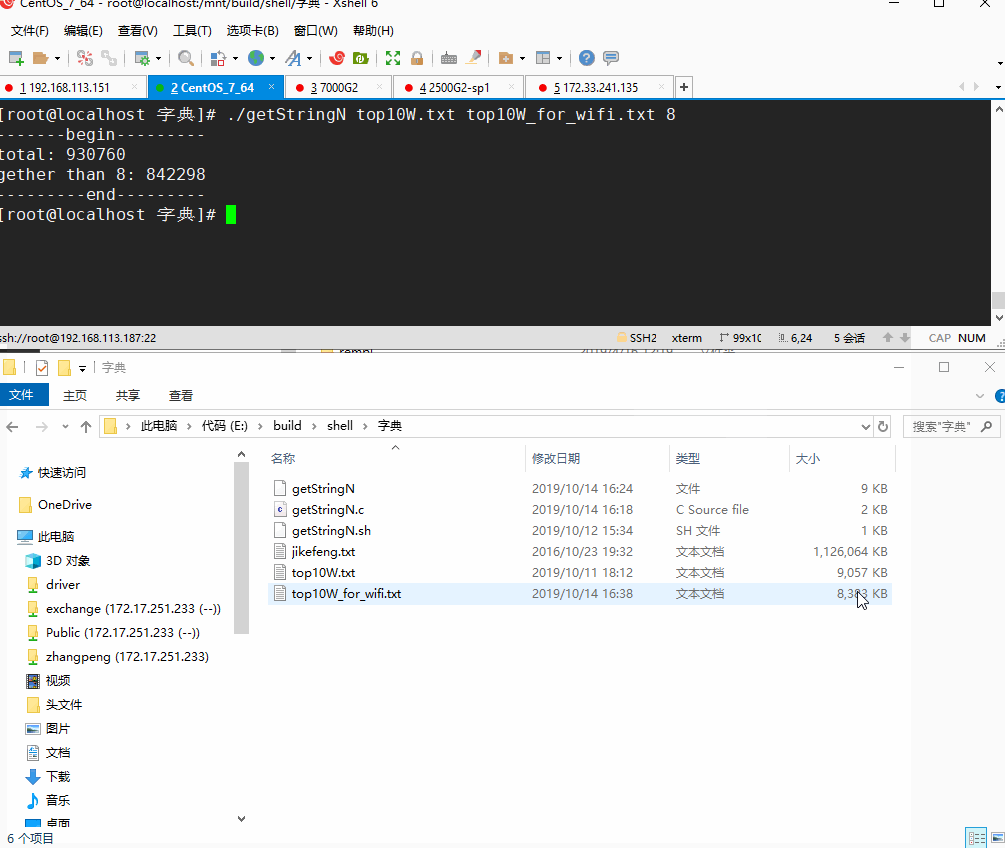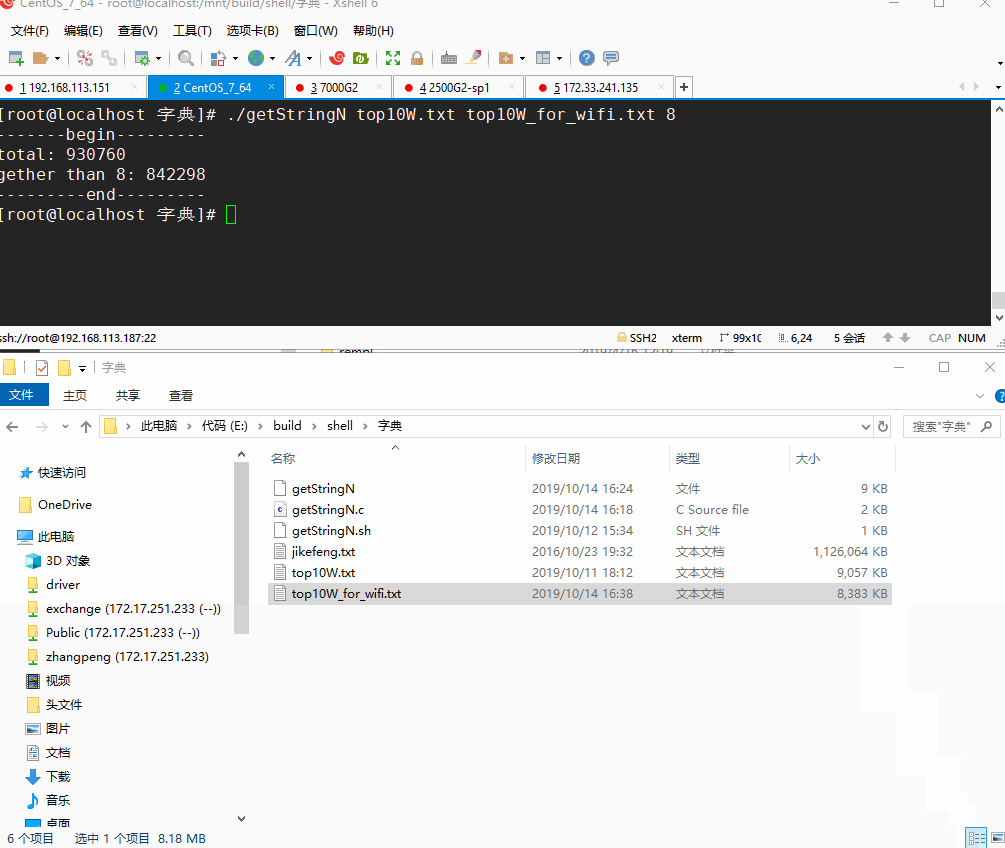
非常快,原始数据93万行,处理后共有84万行,不到一秒钟就处理完了。
看下两个文件的比较:左边是原始的文件,右边是处理后的文件。
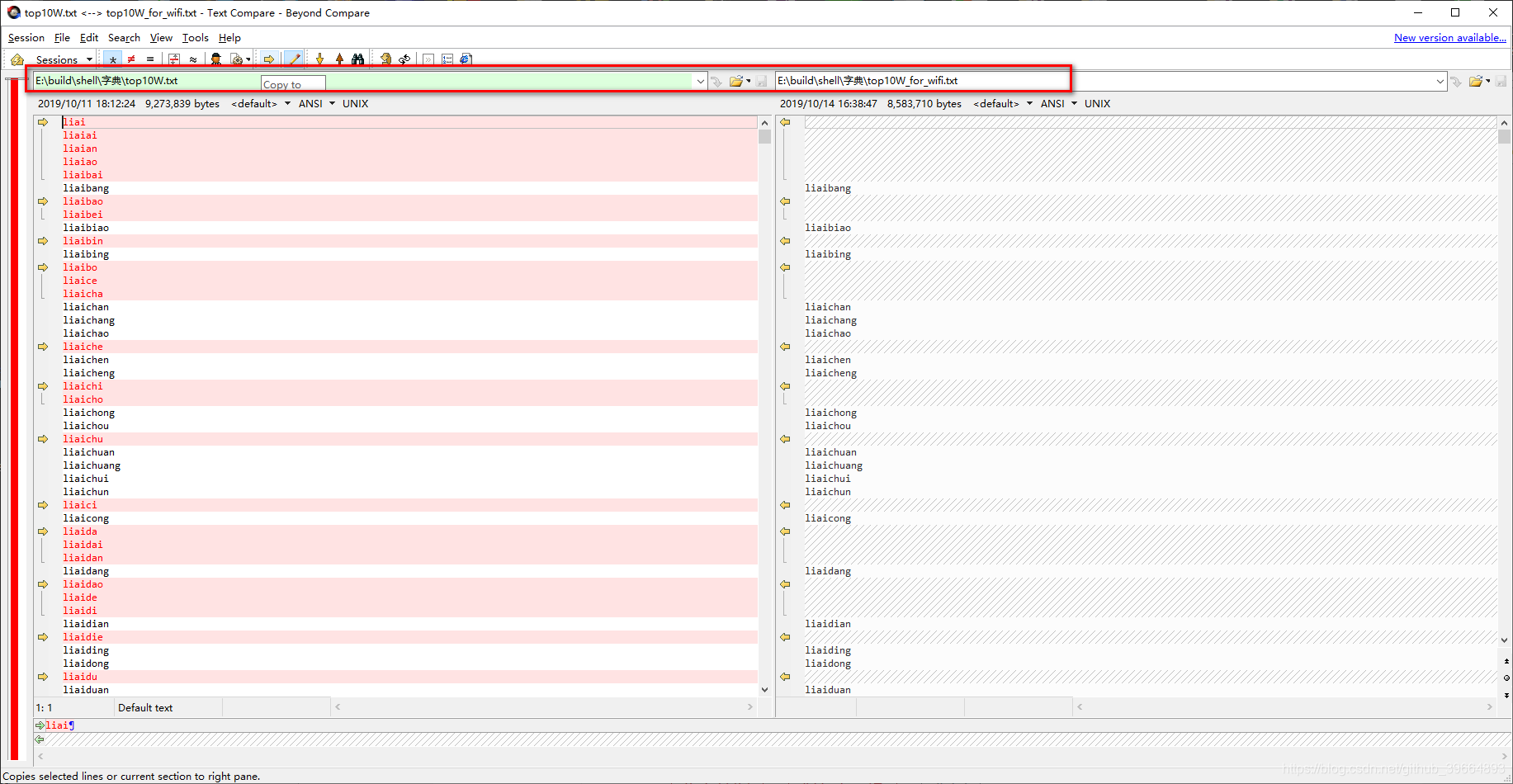
接下来处理一下另外那个1GB多的文件,发现这个主要是看cpu的速度以及磁盘的读写性能了,我用自己的笔记本测试(i7 4710mq + 三星750 的SSD)只需要五六秒钟,用公司的办公电脑(i3 7100 + 普通的机械硬盘)需要七八分钟,有时候还会因为磁盘占用100%卡死无响应。说明C语言的性能还是能充分挖掘计算机的硬件配置,相反脚本语言由于天生的边解释型边运行并不能完全把硬件水平发挥出来。


















 7691
7691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











