






👉 这是一个或许对你有用的社群
🐱 一对一交流/面试小册/简历优化/求职解惑,欢迎加入「芋道快速开发平台」知识星球。下面是星球提供的部分资料:
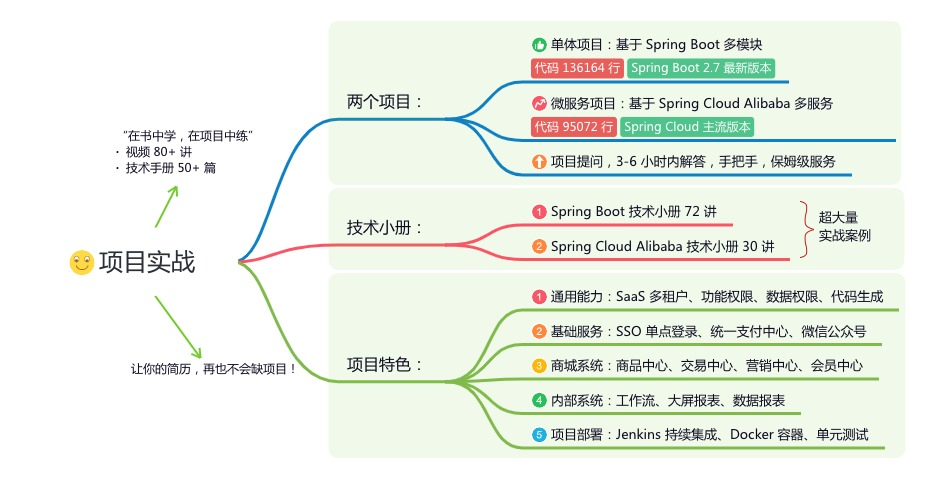
《项目实战(视频)》:从书中学,往事上“练”
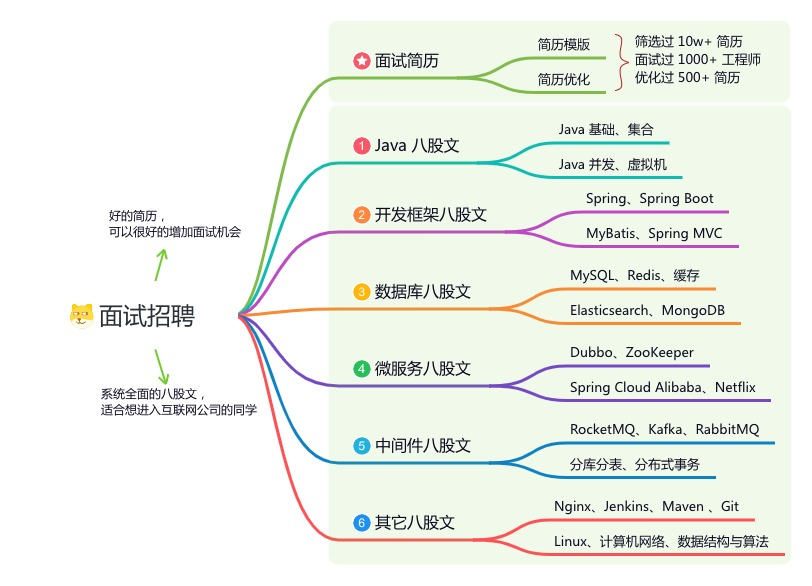
《互联网高频面试题》:面朝简历学习,春暖花开
《架构 x 系统设计》:摧枯拉朽,掌控面试高频场景题
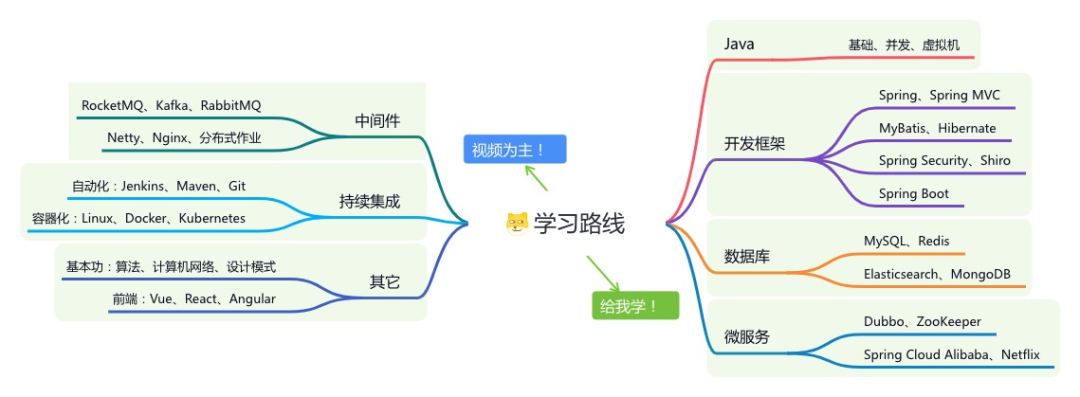
《精进 Java 学习指南》:系统学习,互联网主流技术栈
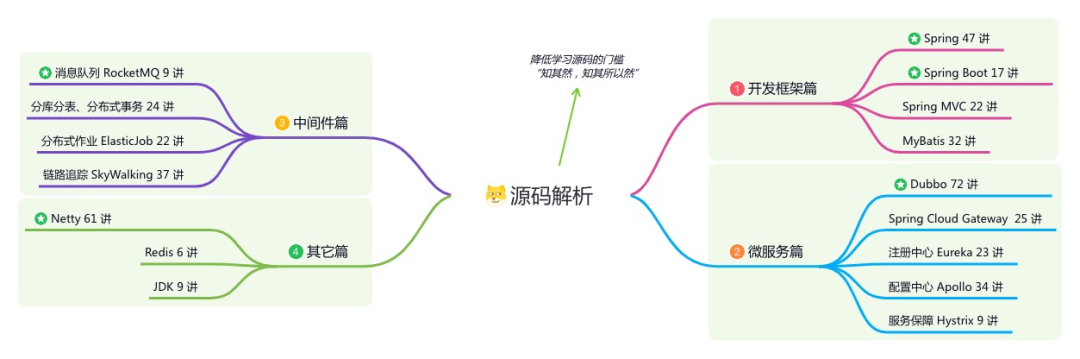
《必读 Java 源码专栏》:知其然,知其所以然
👉这是一个或许对你有用的开源项目
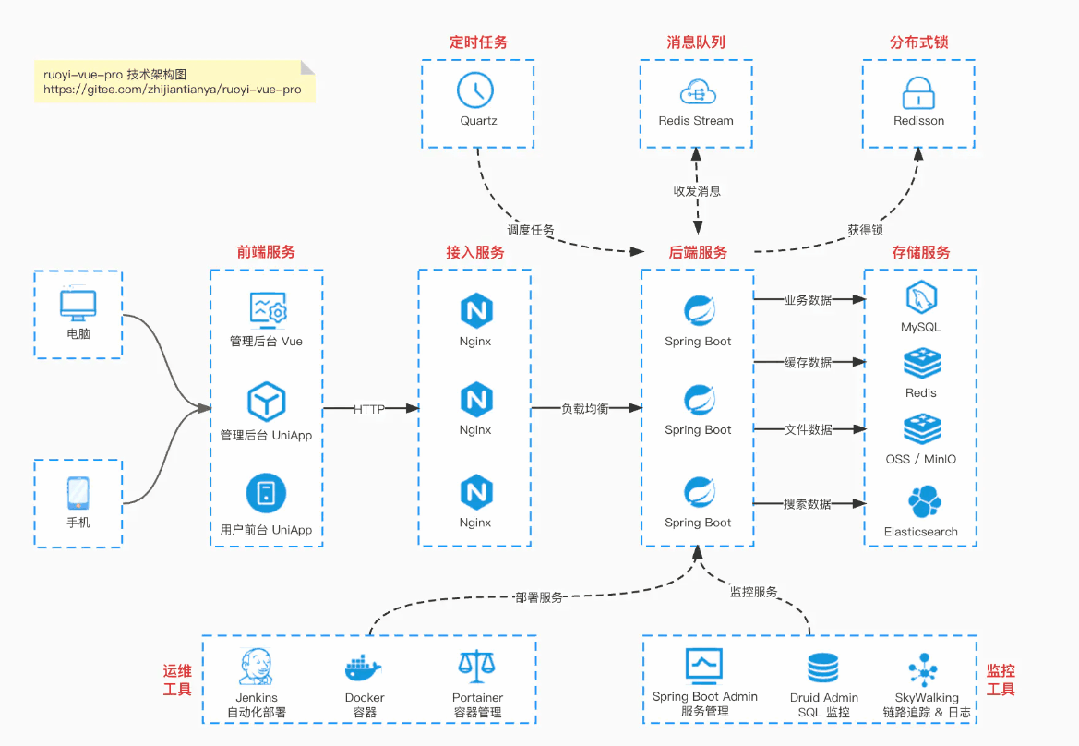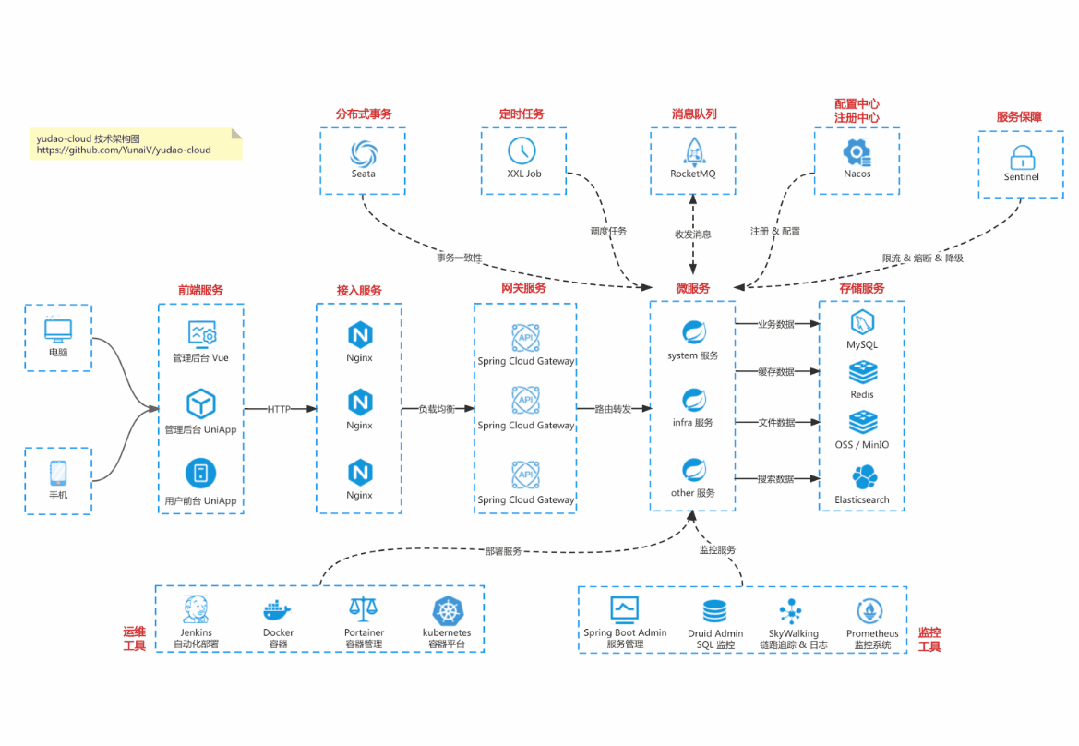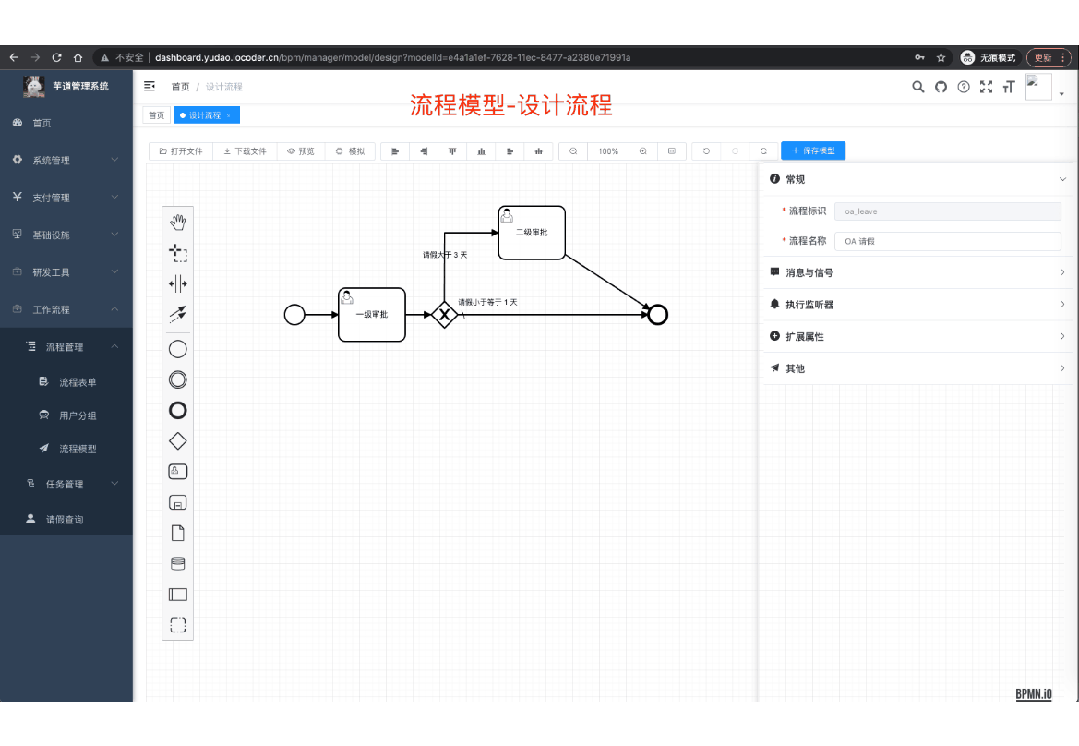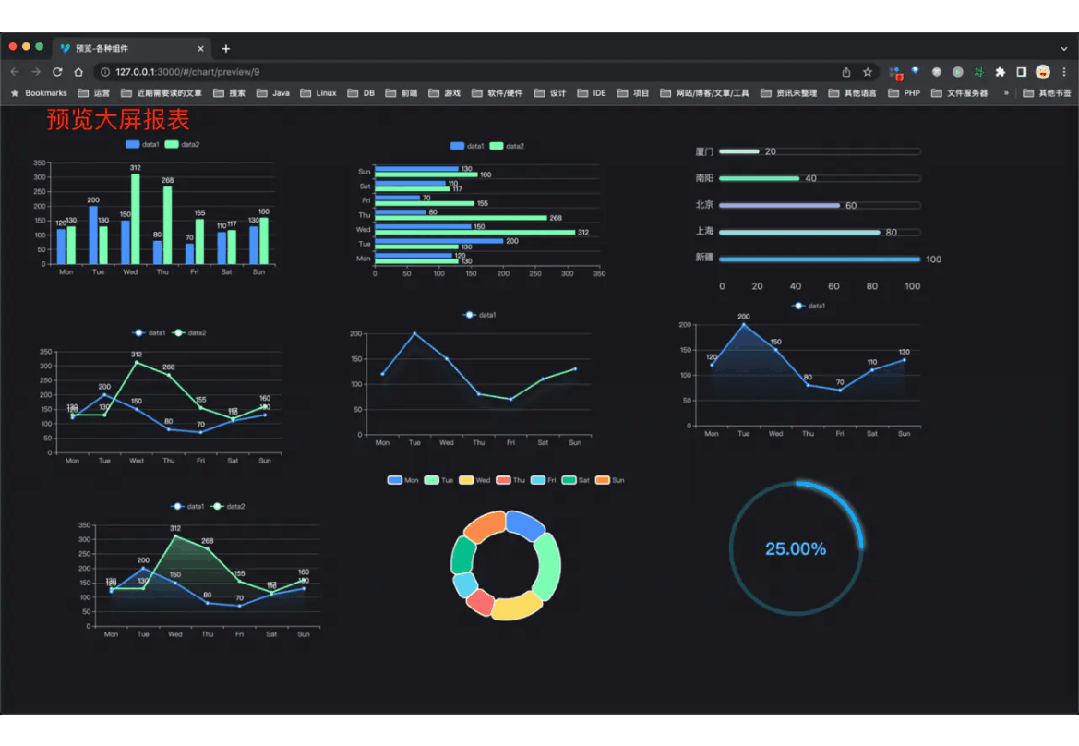
国产 Star 破 10w+ 的开源项目,前端包括管理后台 + 微信小程序,后端支持单体和微服务架构。
功能涵盖 RBAC 权限、SaaS 多租户、数据权限、商城、支付、工作流、大屏报表、微信公众号、ERP、CRM、AI 大模型等等功能:
Boot 多模块架构:https://gitee.com/zhijiantianya/ruoyi-vue-pro
Cloud 微服务架构:https://gitee.com/zhijiantianya/yudao-cloud
视频教程:https://doc.iocoder.cn
【国内首批】支持 JDK 17/21 + SpringBoot 3.3、JDK 8/11 + Spring Boot 2.7 双版本
来源:JackCui
Manus 的全网邀请码真是一票难求,如果在小黄鱼卖个 10 万的价格算离谱的话,那么卖 1000 万的多少有点嘲讽的意思了。

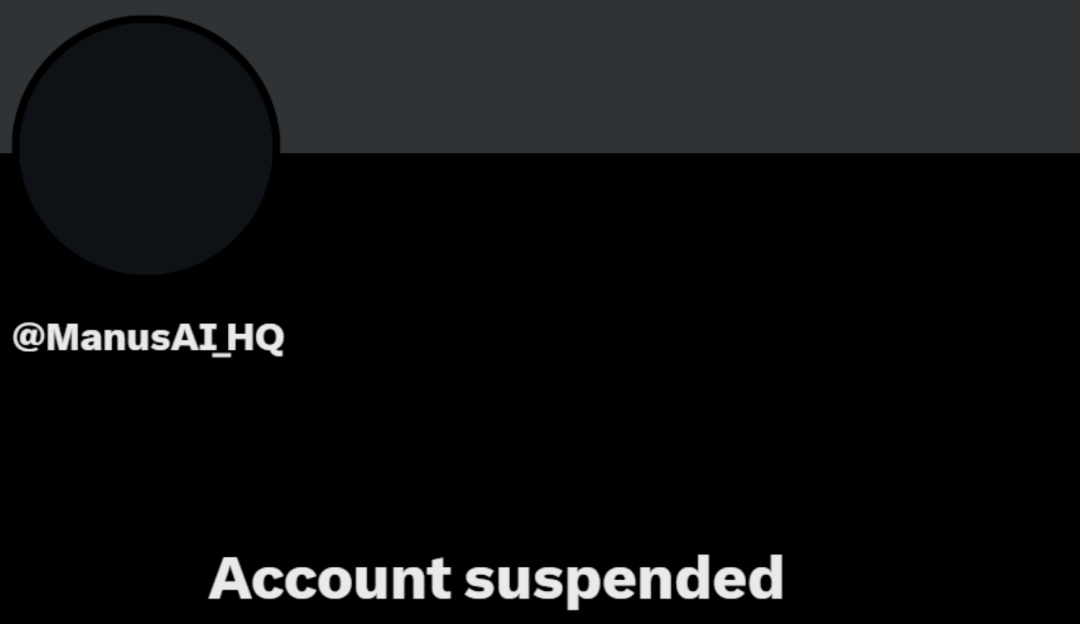
现在很多产品的宣传都是在 X 上发推,包装成“出海项目”拉融资,结果我去 X 上一看,Manus AI 的官方 X 账号竟然已被平台冻结。
不过就在这个时候,开源界的清流,又出现了,这才是真正的平地一声雷,仅耗时三个小时,就把 Manus 复刻了出来。
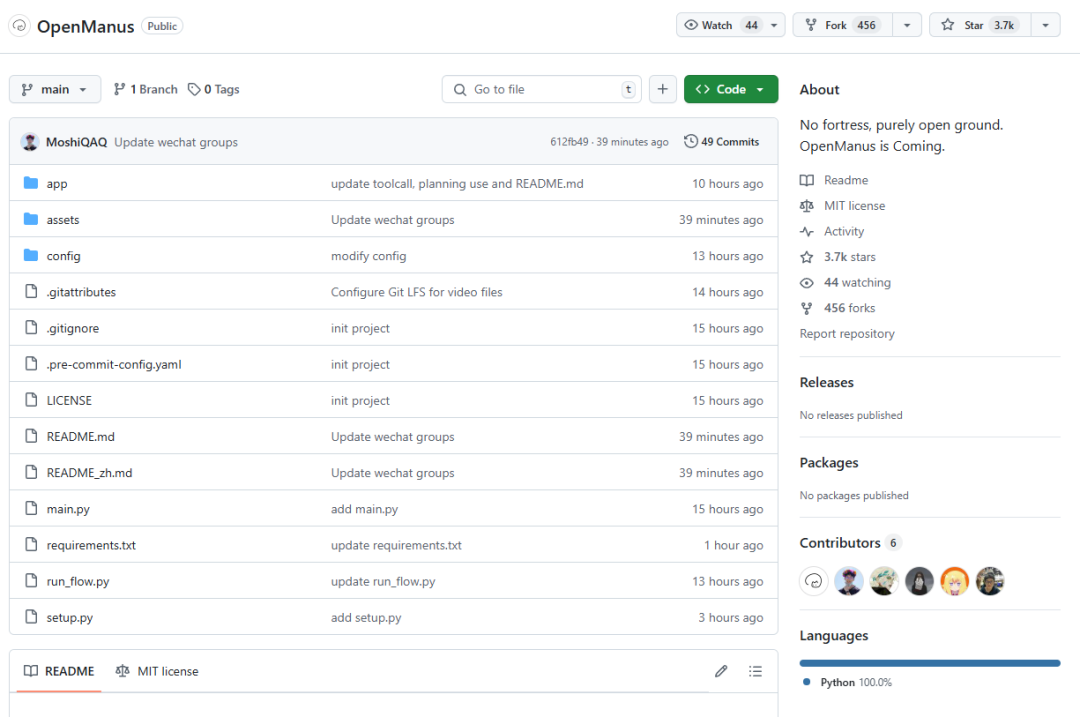
开源一天,已经斩获了 3.7K+ Star。
项目地址:
https://github.com/mannaandpoem/OpenManus
上篇文章里我就提到,Manus 其实就是一个“缝合怪”高手。
就是采用的爬虫 + 大模型 API。Manus 的核心能力 = Compute Use + 虚拟机 + Artifacts + 内置多个 Agent,更像是一个高度整合的 AI 工作流工具,而非真正的通用 AI Agent。
所以,它的技术壁垒并不高。
现在,所有开发者都可以来实测一下了,并且无需邀请码。
使用方法也非常简单,直接搭建开发环境。
步骤还是老三样,先创建虚拟环境:
conda create -n open_manus python=3.12
conda activate open_manus再克隆开发项目:
git clone https://github.com/mannaandpoem/OpenManus.git
cd OpenManus最后安装第三方依赖库:
pip install -r requirements.txt配置好环境之后,我们需要根据模板生成配置文件,可以直接复制一份:
cp config/config.example.toml config/config.tomlconfig/config.toml 有了,就可以在里面编辑 API 密钥了:
# 全局 LLM 配置
[llm]
model = "gpt-4o"
base_url = "https://api.openai.com/v1"
api_key = "sk-..." # 替换为真实 API 密钥
max_tokens = 4096
temperature = 0.0
# 可选特定 LLM 模型配置
[llm.vision]
model = "gpt-4o"
base_url = "https://api.openai.com/v1"
api_key = "sk-..." # 替换为真实 API 密钥这里调用的就是 openai 的 API,你也可以修改协议,配置 deepseek 的也行,就是一个接口的事情。目前已经集成了 Claude 3.5、Qwen VL Plus 等大模型。
这个开源的作者团队来自于 MetaGPT 的核心贡献者:
Jiayi Zhang 也上传了一段 OpenManus 的实测视频。
他的提问是这样的:
深度调研和Manus这个Agent有关的信息,自己整理信息,然后写一个新闻html页面介绍它,你写的html应该尽可能美观。
接着OpenManus就开始干活了。
它将这个任务分步进行,首先使用 Google Search 搜索 Manus Agent 的相关信息。
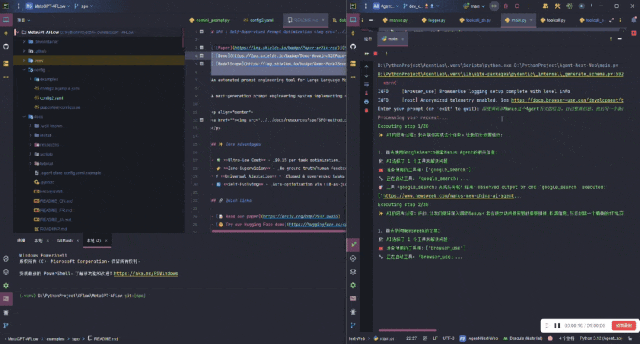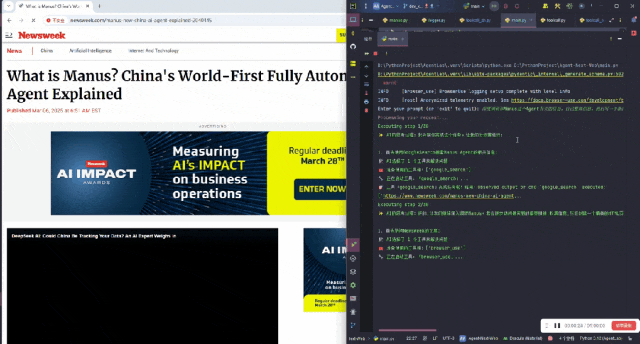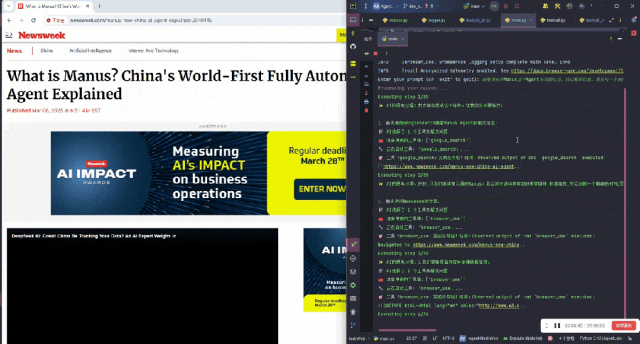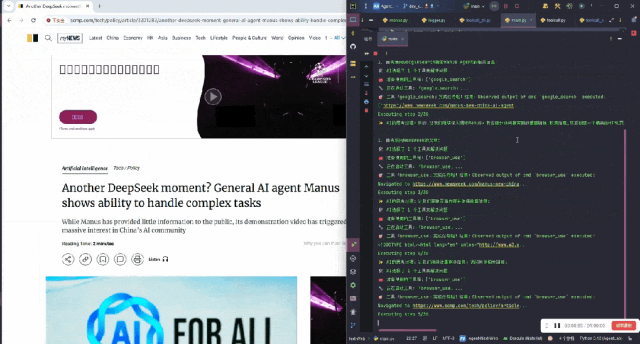
最后整理完信息,将所有内容汇总在一起:
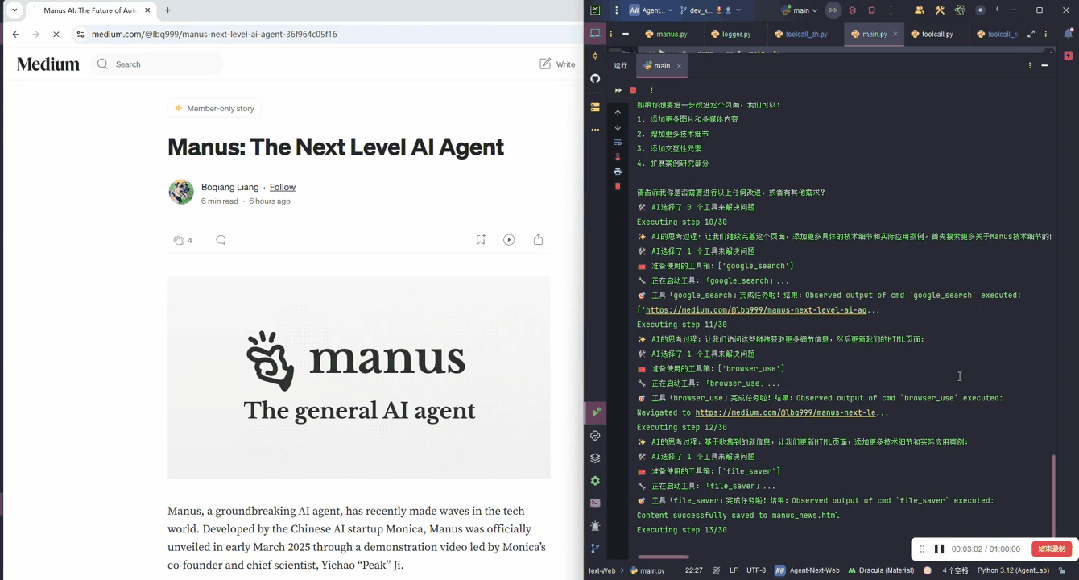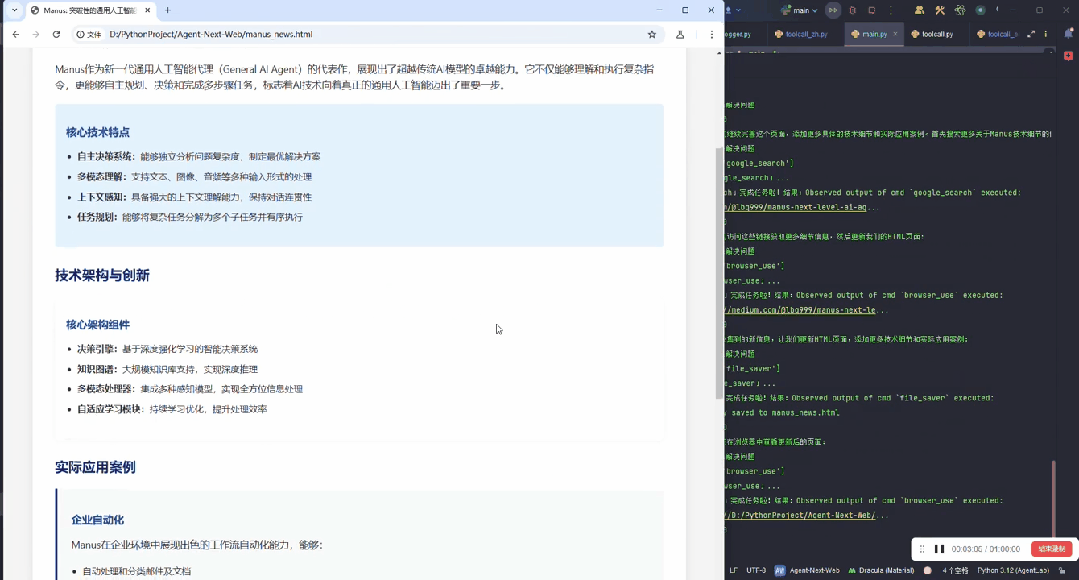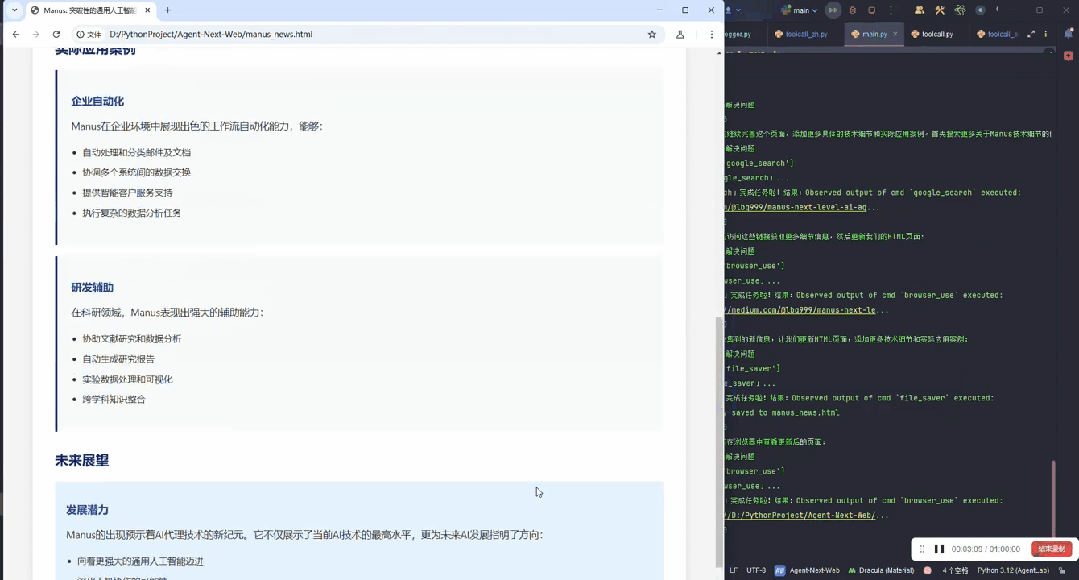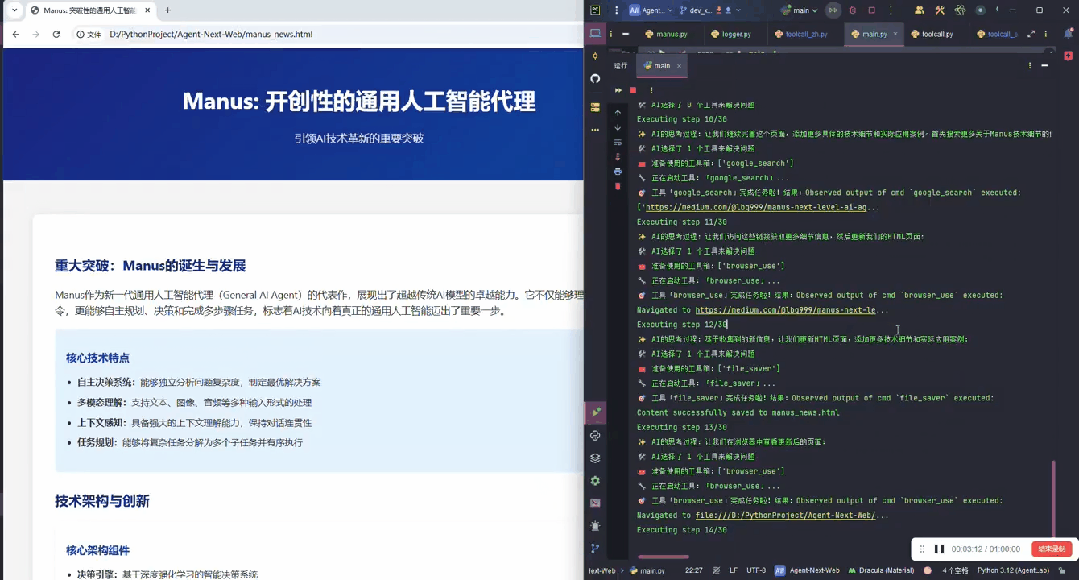
其实这个就是 Manus 的雏形。Manus 做得更好的一点是,针对不同任务,做了专门的优化。
固定好了每个任务的工作流程到底是怎么样执行的,会先定好 todo,然后按照这个流程去执行。

这里有一个明显的问题,我们知道大模型的输出结果是存在幻觉的。
这种多步骤的方法,反复调用大模型,用产生幻觉的数据当作输入,再调用大模型。
它最终生成的结果,可信度能有多少?这是要打一个问号的。
欢迎加入我的知识星球,全面提升技术能力。
👉 加入方式,“长按”或“扫描”下方二维码噢:

星球的内容包括:项目实战、面试招聘、源码解析、学习路线。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









