






👉 这是一个或许对你有用的社群
🐱 一对一交流/面试小册/简历优化/求职解惑,欢迎加入「芋道快速开发平台」知识星球。下面是星球提供的部分资料:
《项目实战(视频)》:从书中学,往事上“练”
《互联网高频面试题》:面朝简历学习,春暖花开
《架构 x 系统设计》:摧枯拉朽,掌控面试高频场景题
《精进 Java 学习指南》:系统学习,互联网主流技术栈
《必读 Java 源码专栏》:知其然,知其所以然
👉这是一个或许对你有用的开源项目
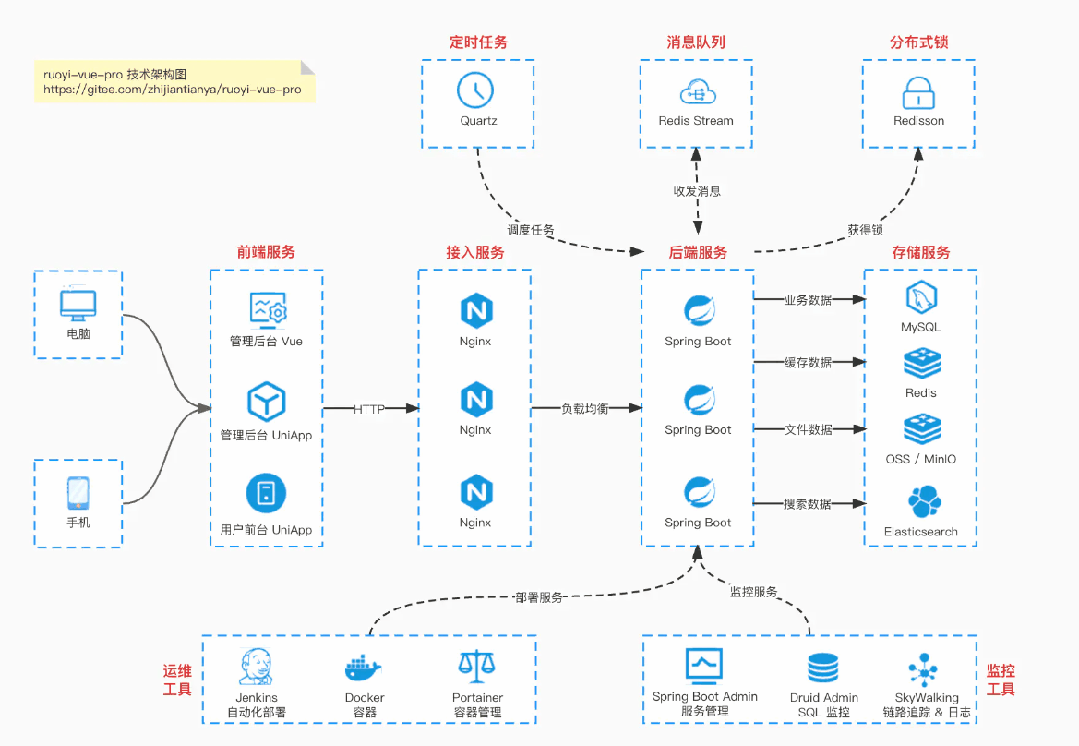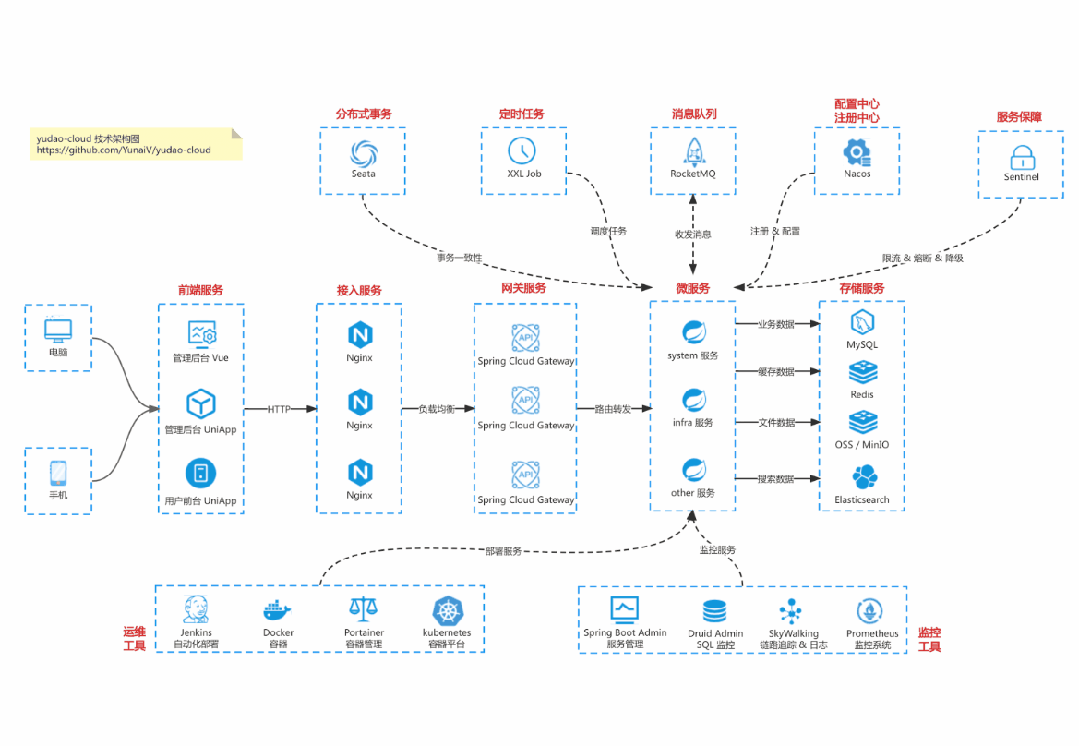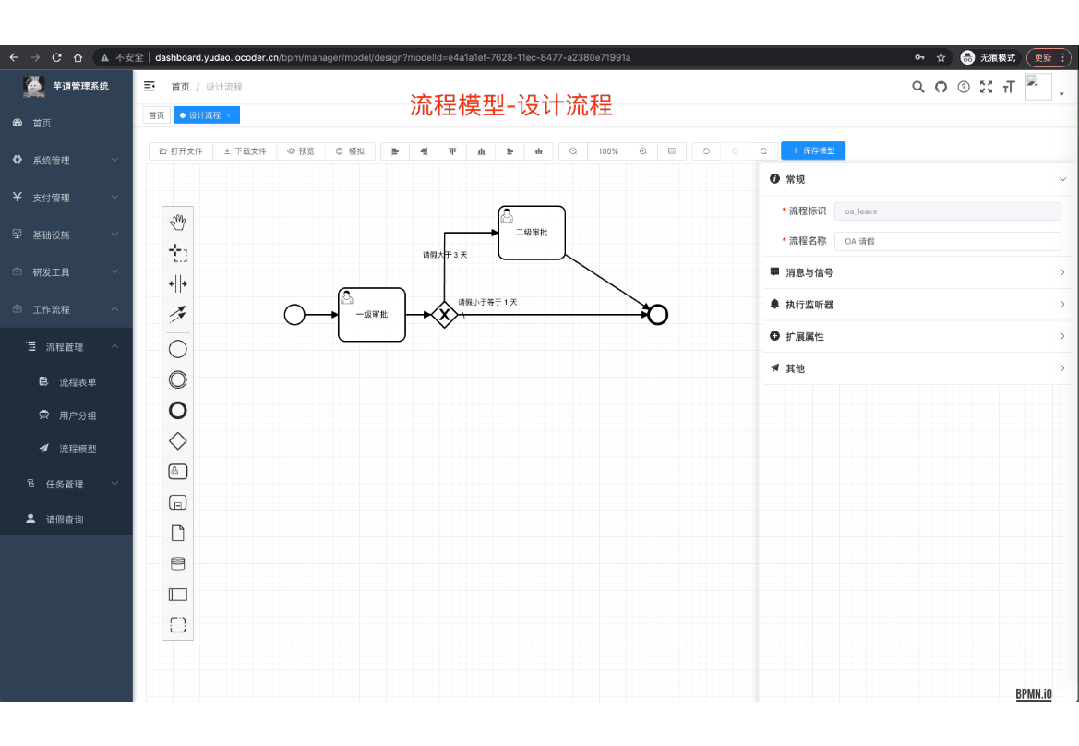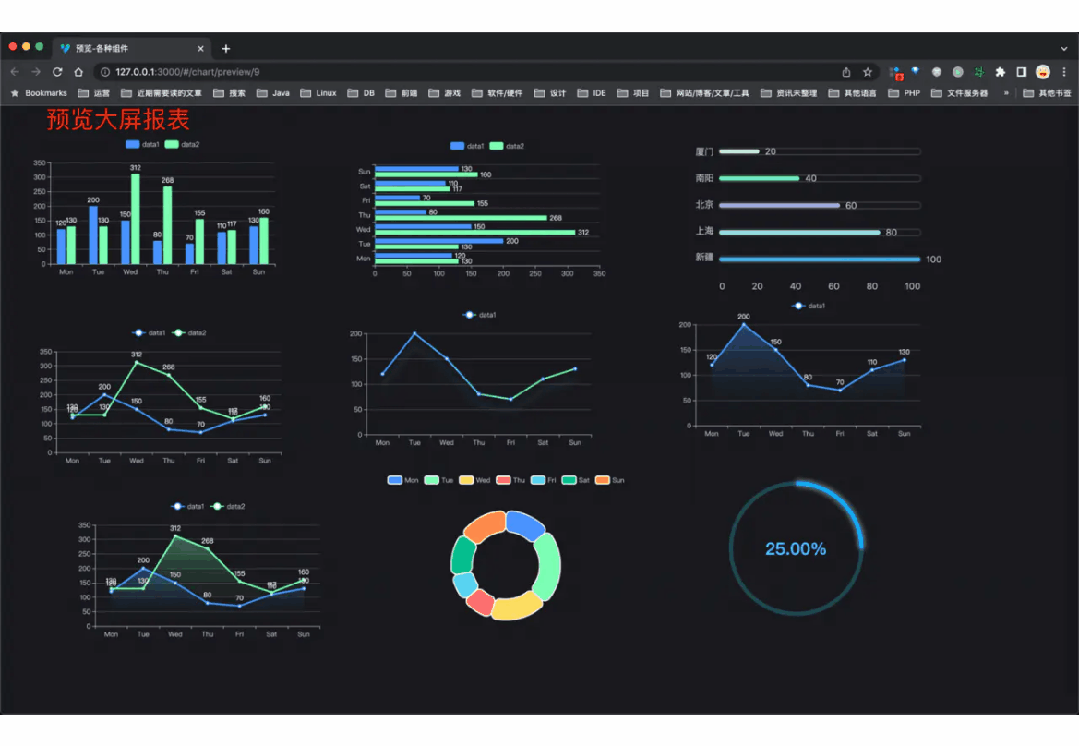
国产 Star 破 10w+ 的开源项目,前端包括管理后台 + 微信小程序,后端支持单体和微服务架构。
功能涵盖 RBAC 权限、SaaS 多租户、数据权限、商城、支付、工作流、大屏报表、微信公众号、ERP、CRM、AI 大模型等等功能:
Boot 多模块架构:https://gitee.com/zhijiantianya/ruoyi-vue-pro
Cloud 微服务架构:https://gitee.com/zhijiantianya/yudao-cloud
视频教程:https://doc.iocoder.cn
【国内首批】支持 JDK 17/21 + SpringBoot 3.3、JDK 8/11 + Spring Boot 2.7 双版本
分库分表是解决单库单表性能瓶颈的有效手段,但也会引入新的复杂性和技术挑战。
这篇文章跟大家一起聊聊,分库分表后带来的7个问题,以及相关的解决方案,希望对你会有所帮助。
1. 全局唯一 ID 问题
问题描述
在分库分表后,每张表的自增 ID 只在本表范围内唯一,但无法保证全局唯一。
例如:
订单表_1的主键从 1 开始,订单表_2的主键也从 1 开始。在需要全局唯一 ID 的场景(如订单号、用户 ID)中会发生冲突。
解决方案
1.1 使用分布式 ID 生成器
推荐工具:
Snowflake :Twitter 开源的分布式 ID 算法。
百度 UidGenerator :基于 Snowflake 的改进版。
Leaf :美团开源,号段模式和 Snowflake 双支持。
代码示例:Snowflake 算法
public class SnowflakeIdGenerator {
private final long epoch = 1622476800000L; // 自定义时间戳
private final long workerIdBits = 5L; // 机器ID
private final long datacenterIdBits = 5L; // 数据中心ID
private final long sequenceBits = 12L; // 序列号
private final long maxWorkerId = ~(-1L << workerIdBits);
private final long maxDatacenterId = ~(-1L << datacenterIdBits);
private final long sequenceMask = ~(-1L << sequenceBits);
private long workerId;
private long datacenterId;
private long sequence = 0L;
private long lastTimestamp = -1L;
public SnowflakeIdGenerator(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) throw new IllegalArgumentException("Worker ID out of range");
if (datacenterId > maxDatacenterId || datacenterId < 0) throw new IllegalArgumentException("Datacenter ID out of range");
this.workerId = workerId;
this.datacenterId = datacenterId;
}
public synchronized long nextId() {
long timestamp = System.currentTimeMillis();
if (timestamp < lastTimestamp) throw new RuntimeException("Clock moved backwards");
if (timestamp == lastTimestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) timestamp = waitNextMillis(lastTimestamp);
} else sequence = 0L;
lastTimestamp = timestamp;
return ((timestamp - epoch) << (workerIdBits + datacenterIdBits + sequenceBits))
| (datacenterId << (workerIdBits + sequenceBits))
| (workerId << sequenceBits)
| sequence;
}
private long waitNextMillis(long lastTimestamp) {
long timestamp = System.currentTimeMillis();
while (timestamp <= lastTimestamp) timestamp = System.currentTimeMillis();
return timestamp;
}
}1.2 数据库号段分配
原理 :维护一个独立的
global_id表,分库按步长分配 ID:库 1:ID 步长为 2,从 1 开始(1, 3, 5...)。
库 2:ID 步长为 2,从 2 开始(2, 4, 6...)。
示例
CREATE TABLE global_id (
id INT PRIMARY KEY AUTO_INCREMENT,
stub CHAR(1) NOT NULL UNIQUE
);
-- 步长设置:
SET @@auto_increment_increment = 2;
SET @@auto_increment_offset = 1;基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/ruoyi-vue-pro
视频教程:https://doc.iocoder.cn/video/
2. 跨库跨表查询复杂性
问题描述
分库分表后,聚合查询(如总数统计、分页查询)需要跨多个分片表执行,增加了查询复杂度。
例如:
查询所有订单总数,需要跨 10 个订单表聚合。
按创建时间分页查询所有订单。
解决方案
2.1 使用中间件(推荐)
ShardingSphere 或 MyCAT :支持 SQL 分片执行和结果合并。
优点:业务代码无需修改,中间件完成分库分表逻辑。
2.2 手动分片查询
按分片逐一查询数据,在业务层合并结果。
示例代码:聚合查询
public int countAllOrders() {
int total = 0;
for (String db : List.of("db1", "db2", "db3")) {
String sql = "SELECT COUNT(*) FROM " + db + ".orders";
total += jdbcTemplate.queryForObject(sql, Integer.class);
}
return total;
}示例代码:跨分片分页查询
public List<Order> paginateOrders(int page, int size) {
List<Order> allOrders = new ArrayList<>();
for (String table : List.of("orders_1", "orders_2")) {
String sql = "SELECT * FROM " + table + " LIMIT 100";
allOrders.addAll(jdbcTemplate.query(sql, new OrderRowMapper()));
}
allOrders.sort(Comparator.comparing(Order::getCreatedAt));
return allOrders.stream()
.skip((page - 1) * size)
.limit(size)
.collect(Collectors.toList());
}手动分片查询的方案,如果数据比较多,性能会比较差。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/yudao-cloud
视频教程:https://doc.iocoder.cn/video/
3. 分布式事务问题
问题描述
分布式事务(如订单表在库 A,库存表在库 B)无法使用单库事务,导致可能会出现数据的一致性问题。
解决方案
3.1 分布式事务框架
Seata :支持跨库的分布式事务。
示例代码 :
@GlobalTransactional
public void createOrder(Order order) {
orderService.saveOrder(order); // 写入库A
stockService.reduceStock(order.getProductId()); // 更新库B
}3.2 柔性事务
使用消息中间件实现最终一致性。
典型实现:RocketMQ 消息事务 。
4. 分片键设计问题
问题描述
分片键选择不当可能导致数据倾斜(热点问题)或查询路由效率低。
解决方案
4.1 分片键设计原则
数据分布均匀 :避免热点问题。
常用查询字段 :尽量选高频查询字段。
4.2 路由表
维护全局路由表,映射分片键到分表。
示例代码:路由表查询
public String getTargetTable(int userId) {
String sql = "SELECT table_name FROM routing_table WHERE user_id = ?";
return jdbcTemplate.queryForObject(sql, new Object[]{userId}, String.class);
}5. 数据迁移问题
问题描述
扩容(如从 4 个分片扩展到 8 个分片)时,旧数据需要迁移到新分片,迁移复杂且可能影响线上服务。
解决方案
5.1 双写策略
数据迁移期间,旧表和新表同时写入。
待迁移完成后,切换到新表。
5.2 增量同步
使用 Canal 监听 MySQL Binlog,将数据迁移到新分片。
示例:Canal 配置
canal.destinations:
example:
mysql:
hostname: localhost
port: 3306
username: root
password: password
kafka:
servers: localhost:9092
topic: example_topic6. 分页查询问题
问题描述
分页查询需要从多个分片表合并数据,再统一分页,逻辑复杂度增加。
解决方案
各分片分页后合并 :先按分片分页查询,业务层合并排序后分页。
中间件支持分页 :如 ShardingSphere。
示例代码:跨分片分页
public List<Order> queryPagedOrders(int page, int size) {
List<Order> results = new ArrayList<>();
for (String table : List.of("orders_1", "orders_2")) {
results.addAll(jdbcTemplate.query("SELECT * FROM " + table + " LIMIT 100", new OrderRowMapper()));
}
results.sort(Comparator.comparing(Order::getCreatedAt));
return results.stream().skip((page - 1) * size).limit(size).collect(Collectors.toList());
}但如果分的表太多,可能会有内存占用过多的问题,需要做好控制。
7. 运维复杂性
问题描述
分库分表后,运维难度增加:
数据库实例多,监控和备份复杂。
故障排查需要跨多个库。
解决方案
自动化运维平台 :如阿里云 DMS。
监控工具 :使用 Prometheus + Grafana 实现分片监控。
总结
分库分表本质上是“性能换复杂度”,它虽然能有效提升系统的性能和扩展性,但问题也随之而来。
分库分表后带来的问题总结如下:
| 问题 | 解决方案 |
|---|---|
| 全局唯一 ID | 雪花算法、号段分配、Leaf |
| 跨库跨表查询 | 中间件支持(如 ShardingSphere)或手动合并 |
| 分布式事务 | 分布式事务框架(Seata)、消息最终一致性 |
| 分片键设计问题 | 路由表或高效分片键 |
| 数据迁移问题 | 双写策略或增量同步(如 Canal) |
| 分页查询问题 | 分片查询后合并排序 |
| 运维复杂性 | 自动化工具(DMS)、监控工具(Prometheus + Grafana) |
应根据业务场景选择适合的分库分表策略,并通过工具和技术方案,解决由此带来的一些问题,最终实现系统的高性能与高可靠性。
欢迎加入我的知识星球,全面提升技术能力。
👉 加入方式,“长按”或“扫描”下方二维码噢:

星球的内容包括:项目实战、面试招聘、源码解析、学习路线。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









