



 本文围绕Java线上机器CPU使用率逐步增高至100%致服务不可用的问题展开。先从5个方向排查,未直接定位问题。后通过重启部分机器、查看线程和堆数据等操作,定位到是代码中对BouncyCastleProvider对象处理不当,导致大量对象无法被GC回收,最后给出代码改进方案。
本文围绕Java线上机器CPU使用率逐步增高至100%致服务不可用的问题展开。先从5个方向排查,未直接定位问题。后通过重启部分机器、查看线程和堆数据等操作,定位到是代码中对BouncyCastleProvider对象处理不当,导致大量对象无法被GC回收,最后给出代码改进方案。
点击上方“芋道源码”,选择“设为星标”
管她前浪,还是后浪?
能浪的浪,才是好浪!
每天 8:55 更新文章,每天掉亿点点头发...
源码精品专栏
来源:cnblogs.com/kingszelda/
p/9034191.html

一、发现问题
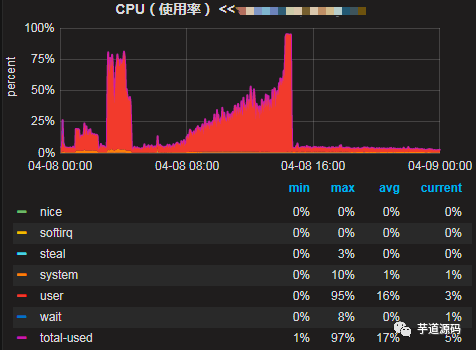
下面是线上机器的cpu使用率,可以看到从4月8日开始,随着时间cpu使用率在逐步增高,最终使用率达到100%导致线上服务不可用,后面重启了机器后恢复。
二、排查思路
简单分析下可能出问题的地方,分为5个方向:
1.系统本身代码问题
2.内部下游系统的问题导致的雪崩效应
3.上游系统调用量突增
4.http请求第三方的问题
5.机器本身的问题
三、开始排查
1.查看日志,没有发现集中的错误日志,初步排除代码逻辑处理错误。
2.首先联系了内部下游系统观察了他们的监控,发现一起正常。可以排除下游系统故障对我们的影响。
3.查看provider接口的调用量,对比7天没有突增,排除业务方调用量的问题。
4.查看tcp监控,TCP状态正常,可以排除是http请求第三方超时带来的问题。
5.查看机器监控,6台机器cpu都在上升,每个机器情况一样。排除机器故障问题。
即通过上述方法没有直接定位到问题。
四、解决方案
1.重启了6台中问题比较严重的5台机器,先恢复业务。保留一台现场,用来分析问题。
2.查看当前的tomcat线程pid

3.查看该pid下线程对应的系统占用情况。top -Hp 384
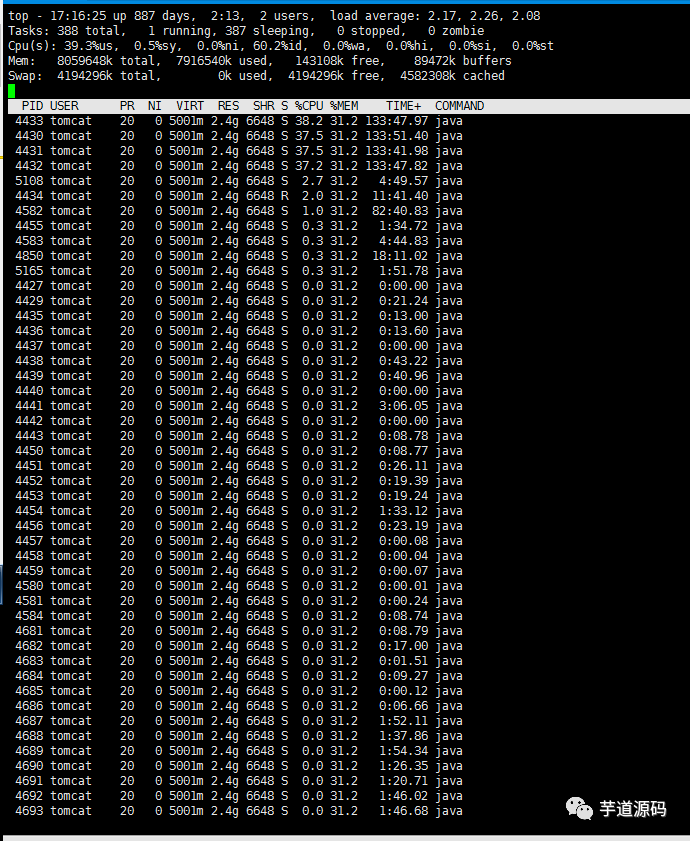
4.发现pid 4430 4431 4432 4433 线程分别占用了约40%的cpu
5.将这几个pid转为16进制,分别为114e 114f 1150 1151
6.下载当前的java线程栈 sudo -u tomcat jstack -l 384>/1.txt
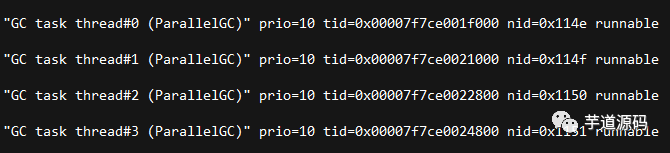
7.查询5中对应的线程情况,发现都是gc线程导致的
8.dump java堆数据
sudo -u tomcat jmap -dump:live,format=b,file=/dump201612271310.dat 384
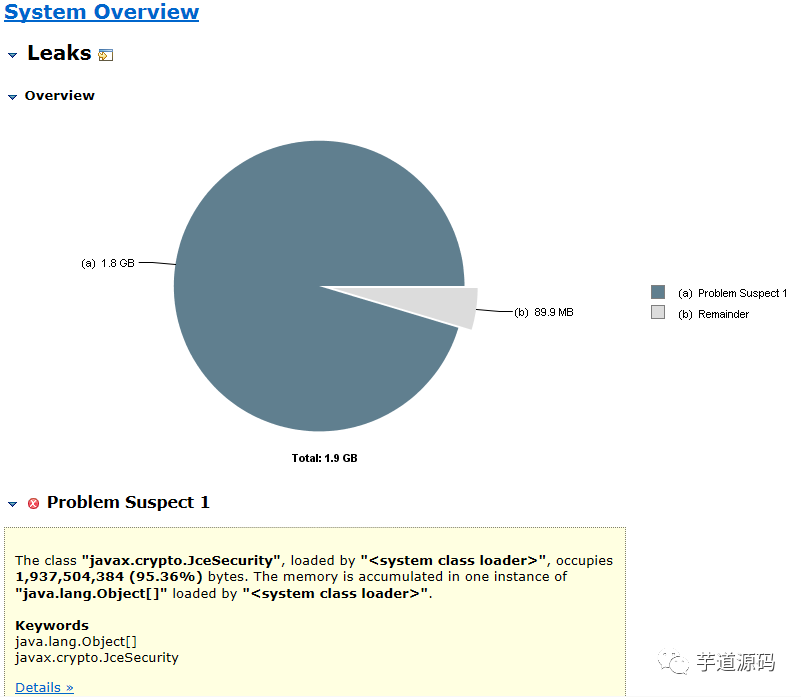
9.使用MAT加载堆文件,可以看到javax.crypto.JceSecurity对象占用了95%的内存空间,初步定位到问题。
MAT下载地址:http://www.eclipse.org/mat/
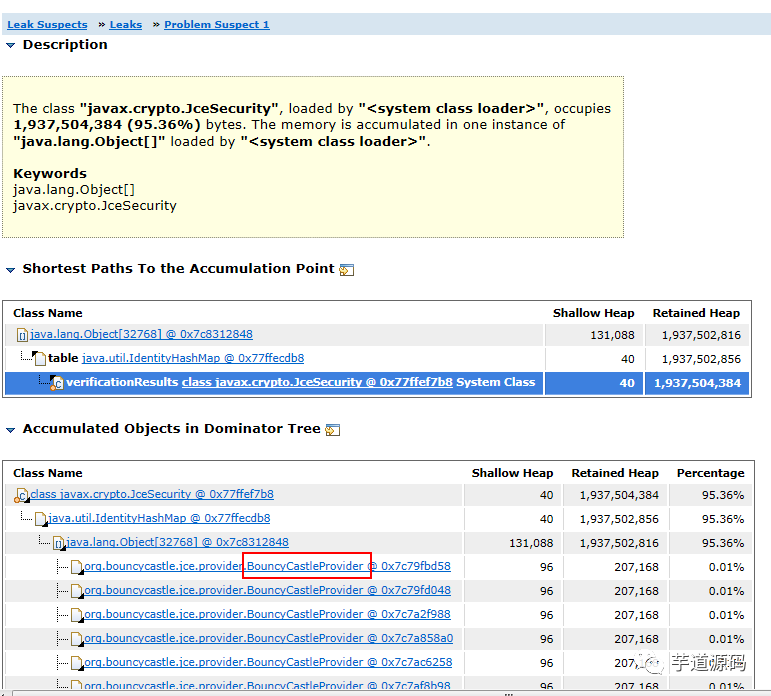
10.查看类的引用树,看到BouncyCastleProvider对象持有过多。即我们代码中对该对象的处理方式是错误的,定位到问题。
五、代码分析
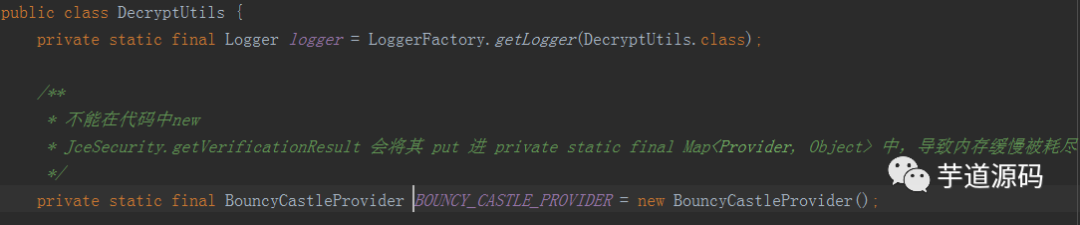
我们代码中有一块是这样写的
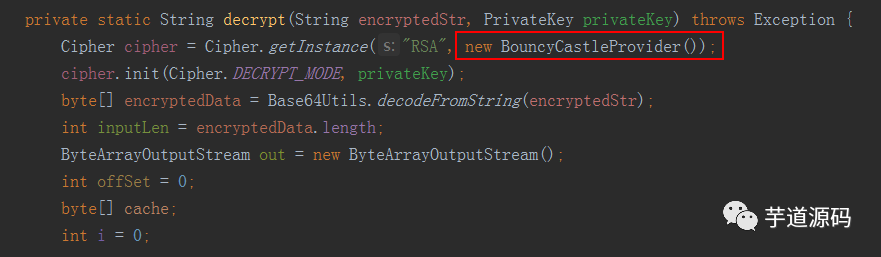
这是加解密的功能,每次运行加解密都会new一个BouncyCastleProvider对象,放倒Cipher.getInstance()方法中。
看下Cipher.getInstance()的实现,这是jdk的底层代码实现,追踪到JceSecurity类中
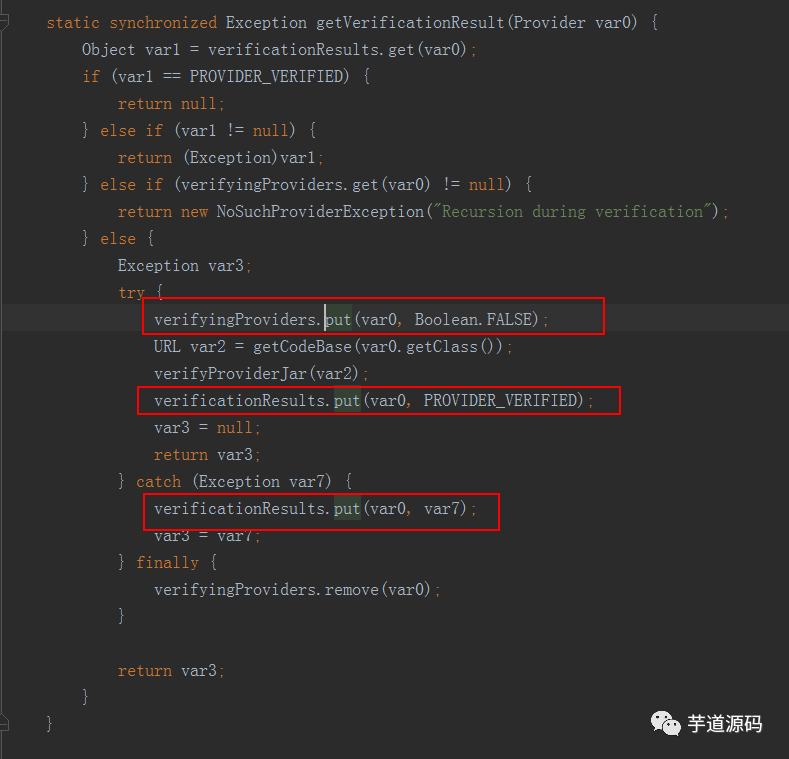
verifyingProviders每次put后都会remove,verificationResults只会put,不会remove.
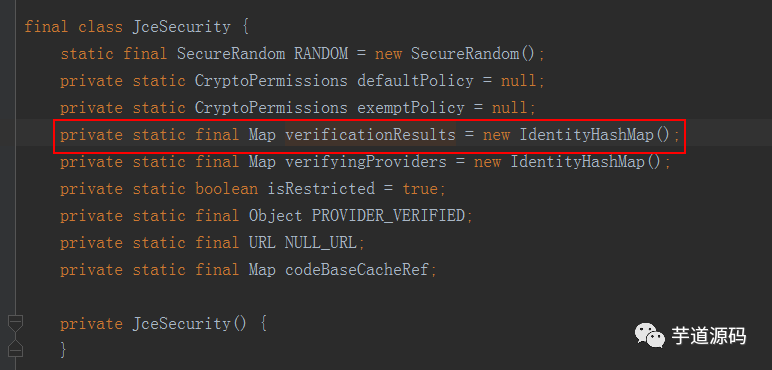
看到verificationResults是一个static的map,即属于JceSecurity类的。
所以每次运行到加解密都会向这个map put一个对象,而这个map属于类的维度,所以不会被GC回收。这就导致了大量的new的对象不被回收。
六、代码改进
将有问题的对象置为static,每个类持有一个,不会多次新建。
七、本文总结
遇到线上问题不要慌,首先确认排查问题的思路:
查看日志
查看CPU情况
查看TCP情况
查看java线程,jstack
查看java堆,jmap
通过MAT分析堆文件,寻找无法被回收的对象
欢迎加入我的知识星球,一起探讨架构,交流源码。加入方式,长按下方二维码噢:

已在知识星球更新源码解析如下:




最近更新《芋道 SpringBoot 2.X 入门》系列,已经 20 余篇,覆盖了 MyBatis、Redis、MongoDB、ES、分库分表、读写分离、SpringMVC、Webflux、权限、WebSocket、Dubbo、RabbitMQ、RocketMQ、Kafka、性能测试等等内容。
提供近 3W 行代码的 SpringBoot 示例,以及超 4W 行代码的电商微服务项目。
获取方式:点“在看”,关注公众号并回复 666 领取,更多内容陆续奉上。
兄弟,艿一口,点个赞!????

















 1288
1288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









