




 本文详细介绍了Kafka中的两种协调器——消费者协调器与组协调器的作用与职责,包括消费者入组过程、消费偏移量管理等内容,并探讨了偏移量提交的最佳实践。
本文详细介绍了Kafka中的两种协调器——消费者协调器与组协调器的作用与职责,包括消费者入组过程、消费偏移量管理等内容,并探讨了偏移量提交的最佳实践。
一、协调器是什么:
协调器负责协调工作。简单点说,就是消费者启动后,到可以正常消费前,这个阶段的初始化工作。消费者能够正常运转起来,全有赖于协调器。
主要的协调器有如下两个:
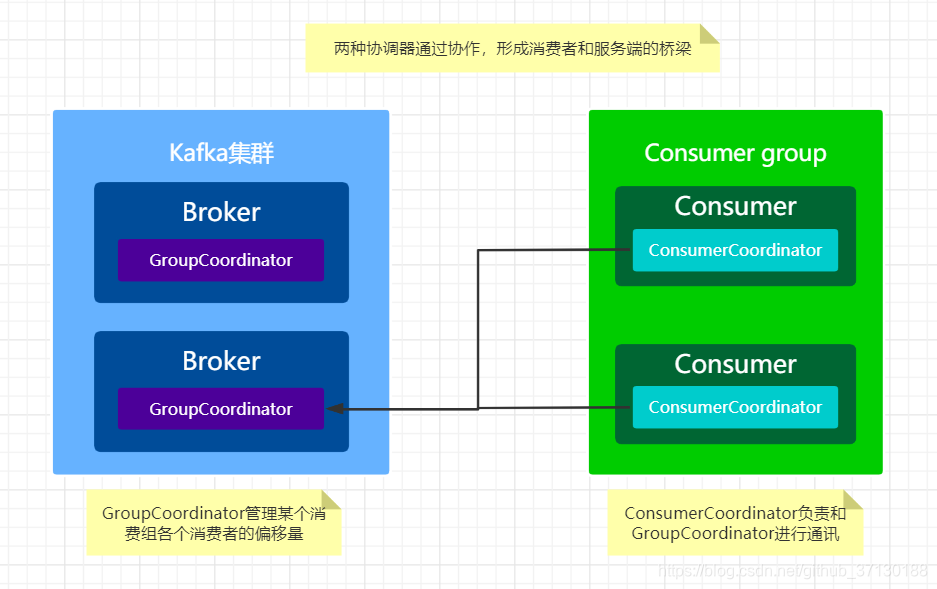
1、消费者协调器(ConsumerCoordinator):可以看作是消费者做操作的代理类(其实并不是),消费者很多操作通过消费者协调器进行处理。
每个consumer实例化时,同时实例化一个ConsumerCoordinator对象,负责同一个消费组下各个消费者和服务端组协调器之前的通信。
2、组协调器(GroupCoordinator):组协调器负责处理消费者协调器发过来的各种请求。
每个broker启动的时候,都会创建GroupCoordinator实例,管理部分消费组(集群负载均衡)和组下每个消费者消费的偏移量(offset)。
二、每个协调器分别处理什么
1.消费者协调器主要负责如下工作:
(1)更新消费者缓存的MetaData
(2)向组协调器申请加入组
(3)消费者加入组后的相应处理
(4)请求离开消费组
(5)向组协调器提交偏移量
(6)通过心跳,保持组协调器的连接感知。
(7)被组协调器选为leader的消费者的协调器,负责消费者分区分配。分配结果发送给组协调器。
(8)非leader的消费者,通过消费者协调器和组协调器同步分配结果。
2.组协调器主要负责如下工作:
(1)在与之连接的消费者中选举出消费者leader
(2)下发leader消费者返回的消费者分区分配结果给所有的消费者
(3)管理消费者的消费偏移量提交,保存在kafka的内部主题中
(4)和消费者心跳保持,知道哪些消费者已经死掉,组中存活的消费者是哪些。
备注:
1.消费者入组:
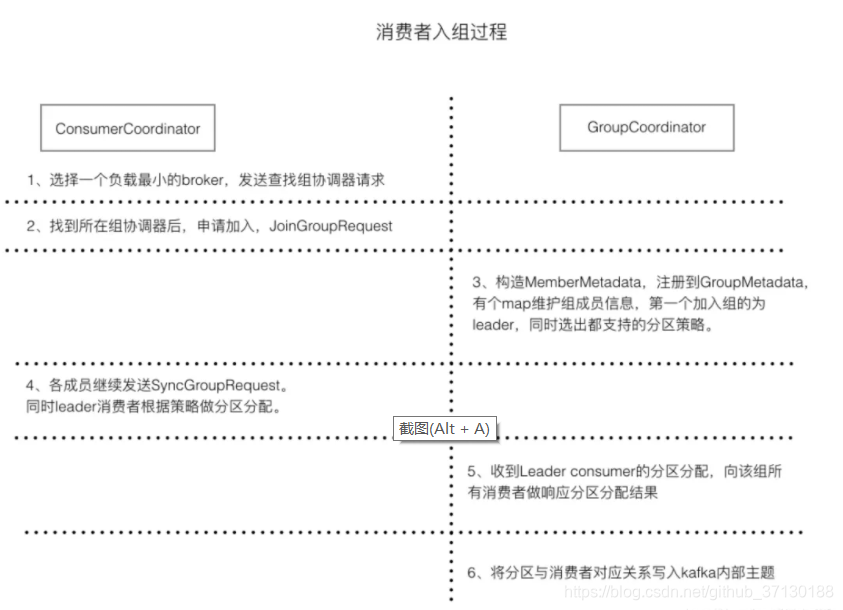
消费者入组的过程,很好的展示了消费者协调器和组协调器之间是如何配合工作的。leader consumer会承担分区分配的工作,这样kafka集群的压力会小很多。同组的consumer通过组协调器保持同步。消费者和分区的对应关系持久化在kafka内部主题。
2.消费偏移量管理:
消费者消费时,会在本地维护消费到的位置(offset),就是偏移量,这样下次消费才知道从哪里开始消费。如果整个环境没有变化,这样做就足够了。
但一旦消费者平衡操作或者分区变化后,消费者不再对应原来的分区,而每个消费者的offset也没有同步到服务器,这样就无法接着前任的工作继续进行了。
因此只有把消费偏移量定期发送到服务器,由GroupCoordinator集中式管理,分区重分配后,各个消费者从GroupCoordinator读取自己对应分区的offset,在新的分区上继续前任的工作。
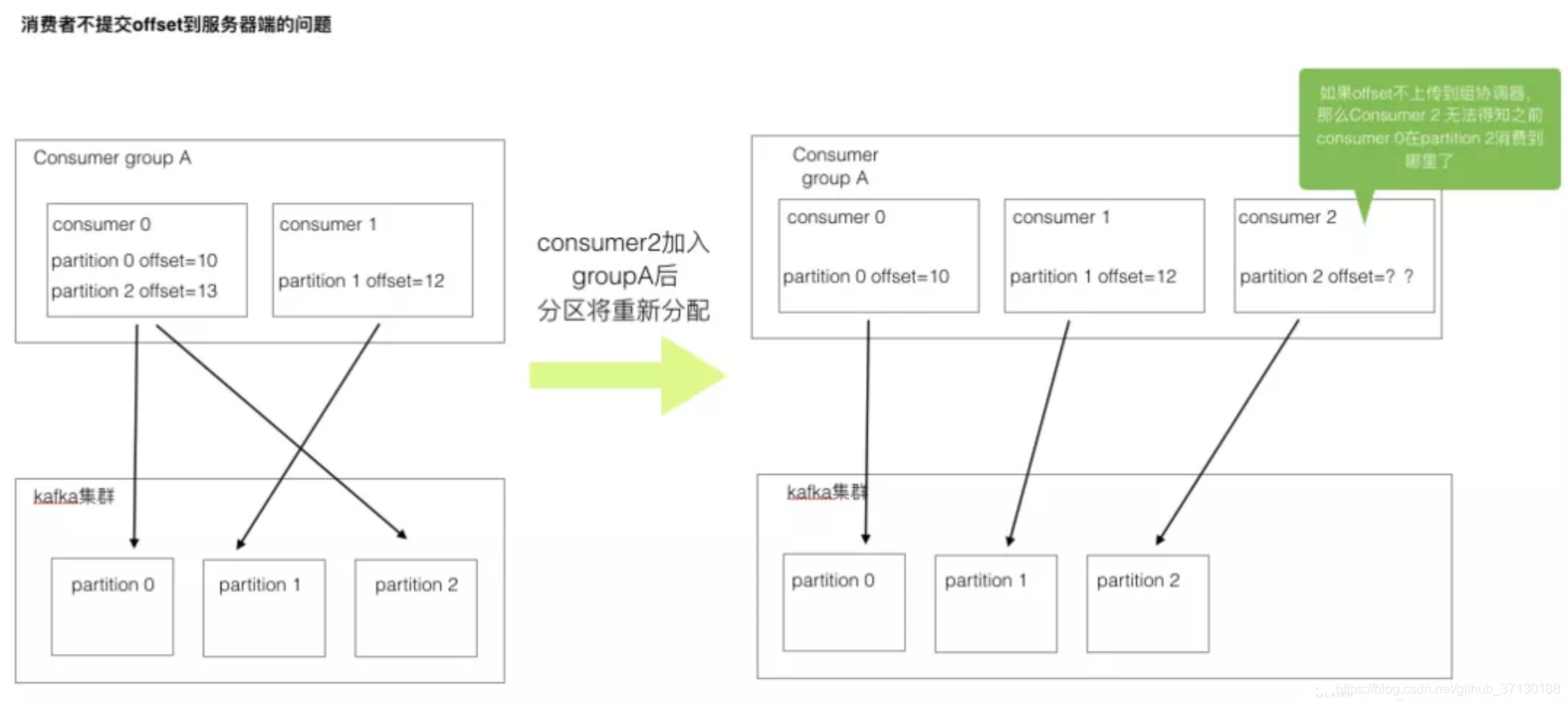
下面两种情况分别会造成重复消费和丢消息:
- 如果提交的偏移量小于消费者最后一次消费的偏移量,那么再均衡后,两个offset之间的消息就会被重复消费
- 如果提交的偏移量大于消费者最后一次消费的偏移量,那么再均衡后,两个offset之间的消息就会丢失
偏移量有两种提交方式
1、自动提交偏移量
设置 enable.auto.commit为true,设定好周期,默认5s。消费者每次调用轮询消息的poll() 方法时,会检查是否超过了5s没有提交偏移量,如果是,提交上一次轮询返回的偏移量。
这样做很方便,但是会带来重复消费的问题。假如最近一次偏移量提交3s后,触发了再均衡,服务器端存储的还是上次提交的偏移量,那么再均衡结束后,新的消费者会从最后一次提交的偏移量开始拉取消息,此3s内消费的消息会被重复消费。
2、手动提交偏移量
设置 enable.auto.commit为false。程序中手动调用commitSync()提交偏移量,此时提交的是poll方法返回的最新的偏移量。
偏移量提交的最佳实践
因此我们采用同步和异步混合的方式提交偏移量。
- 正常消费消息时,消费结束提交偏移量,采用异步方式
- 如果程序报错,finally中,提交偏移量,采用同步方式,确保提交成功
- 再均衡前的回调方法中,提交偏移量,采用同步方式,确保提交成功
这样既保证了吞吐量,也保证了提交偏移量的安全性。另外由于再均衡前提交偏移量,降低了重复消费可能。
更多内容:


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











