




 本文深入讲解了限流的重要性和常见的限流策略,包括单机限流和集群限流。介绍了如何使用Java的RateLimiter、Nginx限流模块、Lua+Redis实现令牌桶算法等多种限流手段。
本文深入讲解了限流的重要性和常见的限流策略,包括单机限流和集群限流。介绍了如何使用Java的RateLimiter、Nginx限流模块、Lua+Redis实现令牌桶算法等多种限流手段。
前言:
在大量并发的环境下,为了防止由于请求暴涨,导致系统崩溃从而引起雪崩,一般会对流量做一定的限制操作。比如等待、排队、降级、拒绝服务、限流等。
我们这节主要讲的是限流,限流的措施有很多,我这里分为单机限流和集群限流。
(1)单机限流:在java中我们可以使用AtomicInteger,RateLimiter或Semaphore来实现,但是上述方案都不支持集群限流。
(2)集群限流:集群限流的应用场景有两个。
一个是网关限流:常用的方案有Nginx限流和Lua+Redis(如:Spring Cloud Gateway),
另一个场景是接口限流:与外部或者下游服务接口的交互,因为接口限制必须进行限流。
一、单机限流
1、java后台代码限流
Java单机限流可以使用AtomicInteger,RateLimiter或Semaphore都可以用来限流。我们说一下RateLimiter限流例子:
引入guava包:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.2-jre</version>
</dependency>
Guava 实现限流示例:
public class RateLimiterExample {
public static void main(String[] args) {
// 每秒产生 10 个令牌(每 100 ms 产生一个)
RateLimiter rt = RateLimiter.create(10);
for (int i = 0; i < 11; i++) {
new Thread(() -> {
// 获取 1 个令牌
rt.acquire();
System.out.println("正常执行方法,ts:" + Instant.now());
}).start();
}
}
}
二、集群限流(网关限流)
1、Nginx限流
Nginx限流可以使用其自带的2个模块:连接数限流模块(ngx_http_limit_conn_module)和漏桶算法实现的请求限流模块(ngx_http_limit_req_module)。
我们通过修改Nginx的配置文件可以实现。
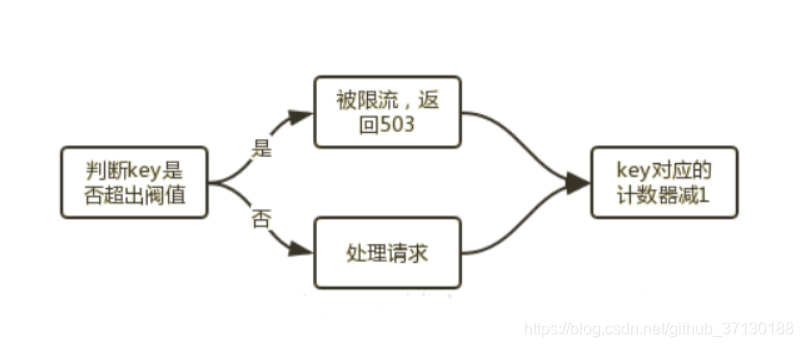
(1)ngx_http_limit_conn_module
limit_conn是用来对某个key对应的总的网络连接数进行限流。可以按照IP、host维度进行限流。不是每个请求都会被计数器统计,只有被Nginx处理并且已经读取了整个请求头的连接才会被计数。
//IP维度限流:
http {
# 用来配置限流key及存放key对应信息的内存区域大小。此处的key是“$binary_remote_addr”,表示IP地址。也可以使用$server_name作为key
limit_conn_zone $binary_remote_addr zone=addr:10m;
# 被限流后的日志级别
limit_conn_log_level error;
# 被限流后返回的状态码
limit_conn_status 503;
...
server {
...
location /limit {
# 要配置存放key和计数器的共享内存区域和指定key的最大连接数。此处表示Nginx最多同时并发处理1个连接
limit_conn addr 1;
}
...
//host维度:
http {
limit_conn_zone $server_name zone zone=hostname:10m;
# 被限流后的日志级别
limit_conn_log_level error;
# 被限流后返回的状态码
limit_conn_status 503;
...
server {
...
location /limit {
limit_conn hostname 1;
}
...
}
流程如下:
(2)ngx_http_limit_req_module
limit_req是漏桶算法,对于指定key对应的请求进行限流。
http {
# 配置限流key、存放key对应信息的共享内存区域大小、固定请求速率。此处的key是“$binary_remote_addr”(IP地址)。固定请求速率使用rate配置,支持10r/s和60r/m。
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
limit_conn_log_level error;
limit_conn_status 503;
...
server {
...
location /limit {
# 配置限流区域、桶容量(突发容量,默认为0)、是否延迟模式(默认延迟)
limit_req zone=one burst=5 nodelay;
}
...
}
}
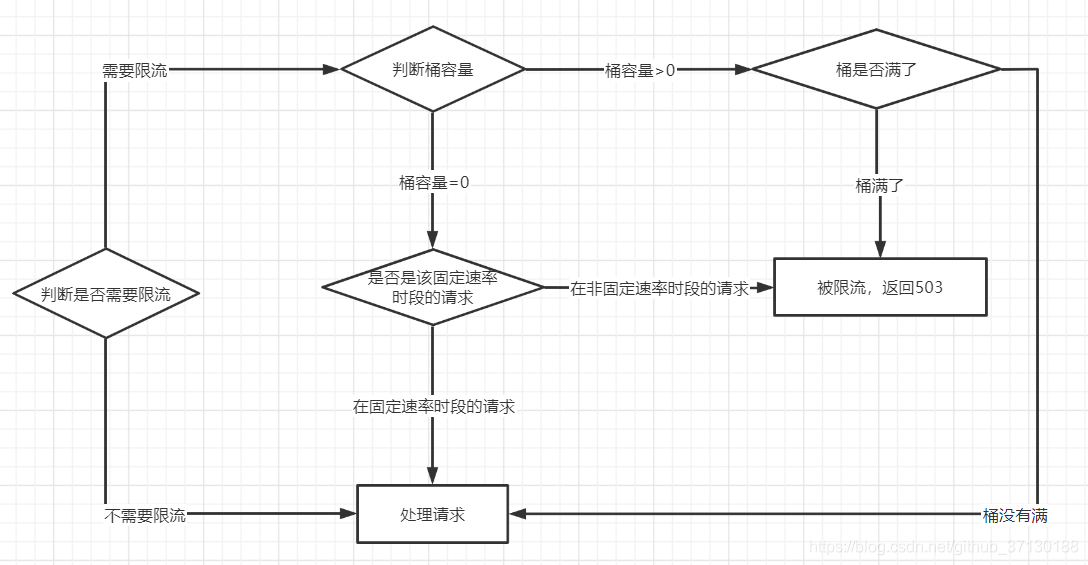
limit_req的主要执行过程如下:
-
请求进入后首先判断上一次请求时间相对于当前时间是否需要限流,如果需要则执行步骤2,否则执行步骤3.
-
如果没有配置桶容量(burst=0),按照固定速率处理请求。如果请求被限流了,直接返回503;
如果配置了桶容量(burst>0),及延迟模式(没有配置nodelay)。如果桶满了,则新进入的请求被限流。如果没有满,则会以固定速率被处理;
如果配置了桶容量(burst>0),及非延迟模式(配置了nodelay)。则不会按照固定速率处理请求,而是允许突发处理请求。如果桶满了,直接返回503. -
如果没有被限流,则正常处理请求。
-
Nginx会在响应时间选择一些(3个节点)限流key进行过期处理,进行内存回收。
2、Lua+Redis限流(SpringCloud Gateway)
Redis执行Lua脚本会以原子性方式进行,单线程的方式执行脚本,在执行脚本时不会再执行其他脚本或命令。并且,Redis只要开始执行Lua脚本,就会一直执行完该脚本再进行其他操作,所以Lua脚本中不能进行耗时操作。使用Lua脚本,还可以减少与Redis的交互,减少网络请求的次数。
SpringCloud中的网关组件Gateway它是基于Redis和Lua实现了令牌桶算法的限流功能,我们可以通过他的原理和细节来了解一下lua+Redis的实现。
Gateway基于Filter模式,提供了限流过滤器 RequestRateLimiterGatewayFilterFactory,我们来看一下该类中的处理Filter的方法。
@SuppressWarnings("unchecked")
@Override
public GatewayFilter apply(Config config) {
KeyResolver resolver = getOrDefault(config.keyResolver, defaultKeyResolver);
RateLimiter<Object> limiter = getOrDefault(config.rateLimiter, defaultRateLimiter);
boolean denyEmpty = getOrDefault(config.denyEmptyKey, this.denyEmptyKey);
HttpStatusHolder emptyKeyStatus = HttpStatusHolder
.parse(getOrDefault(config.emptyKeyStatus, this.emptyKeyStatusCode));
return (exchange, chain) -> resolver.resolve(exchange).defaultIfEmpty(EMPTY_KEY).flatMap(key -> {
if (EMPTY_KEY.equals(key)) {
if (denyEmpty) {
setResponseStatus(exchange, emptyKeyStatus);
return exchange.getResponse().setComplete();
}
return chain.filter(exchange);
}
String routeId = config.getRouteId();
if (routeId == null) {
Route route = exchange.getAttribute(ServerWebExchangeUtils.GATEWAY_ROUTE_ATTR);
routeId = route.getId();
}
return limiter.isAllowed(routeId, key).flatMap(response -> {
for (Map.Entry<String, String> header : response.getHeaders().entrySet()) {
exchange.getResponse().getHeaders().add(header.getKey(), header.getValue());
}
if (response.isAllowed()) {
return chain.filter(exchange);
}
setResponseStatus(exchange, config.getStatusCode());
return exchange.getResponse().setComplete();
});
});
}
我们可以看到,允不允许过,主要是通过limiter.isAllowed(routeId, key)这个方法过滤,limiter的默认实现类是RedisRateLimiter。我们看一下RedisRateLimiter中的isAllowed方法。
public Mono<Response> isAllowed(String routeId, String id) {
//routeId是ip地址,id是使用KeyResolver获取的限流维度id,比如说基于uri,IP或者用户等等。
Config routeConfig = loadConfiguration(routeId);
// 每秒能够通过的请求数
int replenishRate = routeConfig.getReplenishRate();
// 最大流量
int burstCapacity = routeConfig.getBurstCapacity();
try {
// 组装Lua脚本的KEY
List<String> keys = getKeys(id);
// 组装Lua脚本需要的参数,1是指一次获取一个令牌
List<String> scriptArgs = Arrays.asList(replenishRate + "", burstCapacity + "",Instant.now().getEpochSecond() + "", "1");
// 调用Redis,tokens_left = redis.eval(SCRIPT, keys, args)
Flux<List<Long>> flux = this.redisTemplate.execute(this.script, keys, scriptArgs);
.....// 省略
}
static List<String> getKeys(String id) {
String prefix = "request_rate_limiter.{" + id;
String tokenKey = prefix + "}.tokens";
String timestampKey = prefix + "}.timestamp";
return Arrays.asList(tokenKey, timestampKey);
}
备注:
getKeys函数的prefix包含了"{id}",这是为了解决Redis集群键值映射问题。
Redis的KeySlot算法中,如果key包含{},就会使用第一个{}内部的字符串作为hash key,这样就可以保证拥有同样{}内部字符串的key就会拥有相同slot。Redis要求单个Lua脚本操作的key必须在同一个节点上,但是Cluster会将数据自动分布到不同的节点,使用这种方法就解决了上述的问题。
然后我们来看一下Lua脚本的实现,该脚本就在Gateway项目的resource文件夹下。它就是如同 Guava的 RateLimiter一样,实现了令牌桶算法,只不过不在需要进行线程休眠,而是直接返回是否能够获取。
local tokens_key = KEYS[1]
-- request_rate_limiter.${id}.tokens 令牌桶剩余令牌数的KEY值
local timestamp_key = KEYS[2]
-- 令牌桶最后填充令牌时间的KEY值
local rate = tonumber(ARGV[1])
-- replenishRate 令令牌桶填充平均速率
local capacity = tonumber(ARGV[2])
-- burstCapacity 令牌桶上限
local now = tonumber(ARGV[3])
-- 得到从 1970-01-01 00:00:00 开始的秒数
local requested = tonumber(ARGV[4])
-- 消耗令牌数量,默认 1
local fill_time = capacity/rate
-- 计算令牌桶填充满令牌需要多久时间
local ttl = math.floor(fill_time*2)
-- *2 保证时间充足
local last_tokens = tonumber(redis.call("get", tokens_key))
-- 获得令牌桶剩余令牌数
if last_tokens == nil then
-- 第一次时,没有数值,所以桶时满的
last_tokens = capacity
end
local last_refreshed = tonumber(redis.call("get", timestamp_key))
-- 令牌桶最后填充令牌时间
if last_refreshed == nil then
last_refreshed = 0
end
local delta = math.max(0, now-last_refreshed)
-- 获取距离上一次刷新的时间间隔
local filled_tokens = math.min(capacity, last_tokens+(delta*rate))
-- 填充令牌,计算新的令牌桶剩余令牌数 填充不超过令牌桶令牌上限。
local allowed = filled_tokens >= requested
local new_tokens = filled_tokenslocal allowed_num = 0
if allowed then
-- 若成功,令牌桶剩余令牌数(new_tokens) 减消耗令牌数( requested ),
-- 并设置获取成功( allowed_num = 1 ) 。
new_tokens = filled_tokens - requested
allowed_num = 1
end
-- 设置令牌桶剩余令牌数( new_tokens ) ,令牌桶最后填充令牌时间(now)
-- ttl是超时时间
redis.call("setex", tokens_key, ttl, new_tokens)
redis.call("setex", timestamp_key, ttl, now)
-- 返回数组结果
return { allowed_num, new_tokens }
至此,就完成了lua+redis中使用令牌桶解决IP限流问题。如果要自己写的话,其原理及结构也大同小异。
二、集群限流(接口限流)
接口限流也可以使用集群限流中的网关限流,其他接口限流针对不同场景(接口限流场景比较,多依据不同环境做使用不同方法),主要有以下几个方向:
(1)限制 总并发数(⽐比如 数据库连接池、线程池)
(2)限制 远程接⼝口 调⽤用速率
(3)限制 MQ 的消费速率
备注:补充一下漏桶算法和令牌桶算法。
(1)漏桶算法:漏桶(Leaky Bucket)算法思路很简单,水(请求)先进入到漏桶里,漏桶以一定的速度出水(接口有响应速率),当水流入速度过大会直接溢出(访问频率超过接口响应速率),然后就拒绝请求,可以看出漏桶算法能强行限制数据的传输速率。
它的主要目的是:控制数据注入到网络的速率,平滑网络上的突发流量。
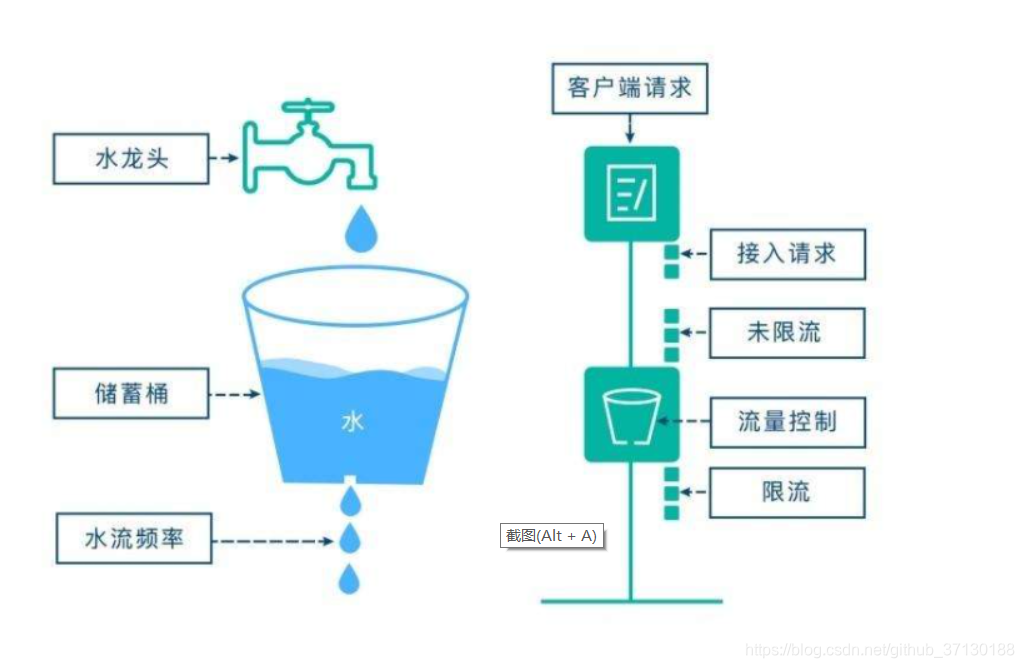
基本过程:
(1)到达的数据包(网络层的PDU)被放置在底部具有漏孔的桶中(数据包缓存)
(2)漏桶最多可以排队b个字节,漏桶的这个尺寸受限于有效的系统内存。如果数据包漏桶已经满了,那么数据包应被丢弃
(3)数据包从漏桶中漏出,以常量速率(r字节/秒)注入网络,因此平滑了突发流量
(4)漏桶算法强调的是在桶中缓存数据包,然后以一定的速率从桶中取出数据包,从而实现了限流,防止突发流量
使用场景:
这是用来保护他人,也就是保护他所调用的系统。
当调用的第三方系统本身没有保护机制,或者有流量限制的时候,我们的调用速度不能超过他的限制,由于我们不能更改第三方系统,所以只有在主调方控制。这个时候,即使流量突发,也必须舍弃。因为消费能力是第三方决定的。
例如保护数据库的限流,先把对数据库的访问加入到木桶中,worker再以db能够承受的qps从木桶中取出请求,去访问数据库。
(2)令牌桶算法:令牌桶算法和 漏桶算法效果一样但方向相反的算法,更加容易理解.随着时间流逝,系统会按恒定时间间隔往桶里加入令牌(想象和漏洞漏水相反,有个水龙头在不断的加水),如果桶已经满了就不再加了.新请求来临时,会各自拿走一个令牌,如果没有令牌可拿了就阻塞或者拒绝服务.
主要目的是:用来控制发送到网络上的数据的数目,并允许突发数据的发送。
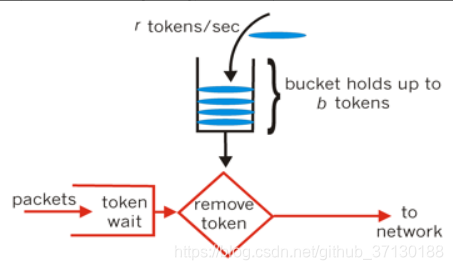
基本过程:
(1)假如用户配置的平均发送速率为r,则每隔1/r秒一个令牌被加入到桶中
(2)假设桶最多可以存发b个令牌。如果令牌到达时令牌桶已经满了,那么这个令牌会被丢弃
(3)当一个n个字节的数据包到达时,就从令牌桶中删除n个令牌,并且数据包被发送到网络
(4)如果令牌桶中少于n个令牌,那么不会删除令牌,并且认为这个数据包在流量限制之外
(5)算法允许最长b个字节的突发,但从长期运行结果看,数据包的速率被限制成常量r。对于在流量限制外的数据包可以以不同的方式处理
(6)它们可以被丢弃
(7)它们可以排放在队列中以便当令牌桶中累积了足够多的令牌时再传输
(8)它们可以继续发送,但需要做特殊标记,网络过载的时候将这些特殊标记的包丢弃
使用场景:
令牌桶可以用来保护自己,主要用来对调用者频率进行限流,为的是让自己不被打垮。
所以如果自己本身有处理能力的时候,如果流量突发(实际消费能力强于配置的流量限制),那么实际处理速率可以超过配置的限制。
适合电商抢购或者微博出现热点事件这种场景,因为在限流的同时可以应对一定的突发流量。如果采用漏桶那样的均匀速度处理请求的算法,在发生热点时间的时候,会造成大量的用户无法访问,对用户体验的损害比较大。
从原理上看,令牌桶算法和漏桶算法是相反的,一个“进水”,一个是“漏水”。
总结起来:如果要让自己的系统不被打垮,用令牌桶。如果保证被别人的系统不被打垮,用漏桶算法。


















 2759
2759




 到【灌水乐园】发言
到【灌水乐园】发言









