




 本文深入讲解线性回归算法原理及实现过程,包括误差衡量、最小二乘法求解及封闭形式解等内容,并探讨线性回归在二元分类中的应用。
本文深入讲解线性回归算法原理及实现过程,包括误差衡量、最小二乘法求解及封闭形式解等内容,并探讨线性回归在二元分类中的应用。
这节课开始介绍一些常见算法,这次Lecture介绍了最常见的Linear Regression线性回归算法。

Linear Regression Problem
在Linear Regression模型下的hypothesis为,特征集为d维,加上常数项后就为d + 1维(所以注意i从0开始)。在线性回归中,误差的衡量常采用平方误差(squared error):
,相关的记号已经在上一节课解释过啦~
而Linear Regression的目标就是找到一条直线(平面)来使得残差(residuals)最小,根据之前的知识我们很容易知道,在机器学习中这分为in-sample和out-of-sample两部分,根据之前关于VC Bound延伸的证明,只要研究就可以了。

我们将从一个以
为变量的函数,转化为了一个以
为变量的函数,从而我们只要寻找
的最小值就可以得到最优的结果。要注意的是这里的输入集
中x和y都是可能带noise的,但是这并不影响。
根据红色石头的笔记,这是采用最小二乘法的方法来测量错误,但有以下注意点——
这里提一点,最小二乘法可以解决线性问题和非线性问题。线性最小二乘法的解是closed-form,即X=(ATA)−1ATyX=(ATA)−1ATy,而非线性最小二乘法没有closed-form,通常用迭代法求解。本节课的解就是closed-form的。关于最小二乘法的一些介绍,请参见我的另一篇博文:
主要就是在使用最小二乘法在线性与非线性时对应解法的区别。
Linear Regression Algorithm
现在的问题就转化为了如何求?
(利用向量内积可交换让式子美观些)
(连加一串的
平方可以写成整个向量长度的平方)
(
为N * (d + 1),
为(d + 1) * 1,
为N * 1)
从而我们得到,是一个以
为变量的函数,连续(continuous)、处处可微(differentiable)的凸函数(convex)。
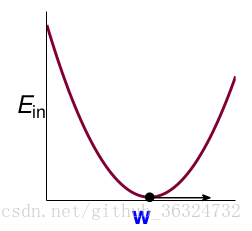
对于求这类函数的极值,只要让其一阶导数 = 0,对于多元函数,只要各方向偏导数 = 0,函数在某点梯度 = 0。
,找到这样的
就可以。
将式子展开——
从一维向高维来推广

所以有:
于是,我们就得到了关于最优解时关于的方程
可逆,也就是上文提到的closed-form解,就有
,其中
是伪逆矩阵(pseudo-inverse)
用以为参数的线性方程对原始数据做预测,可以得到拟合值
,其中
称为帽子矩阵(Hat Matrix)。
于是Linear Regression Algorithm的流程如下——

Generalization Issue
现在的问题是,是否是一个机器学习算法?
- 这不属于机器学习范畴。因为这种closed-form解的形式跟一般的机器学习算法不一样,而且在计算最小化误差的过程中没有用到迭代。
- 这属于机器学习范畴。因为从结果上看,和都实现了最小化,而且实际上在计算逆矩阵的过程中,也用到了迭代。
我们先看一下Hat Matrix 的几何含义
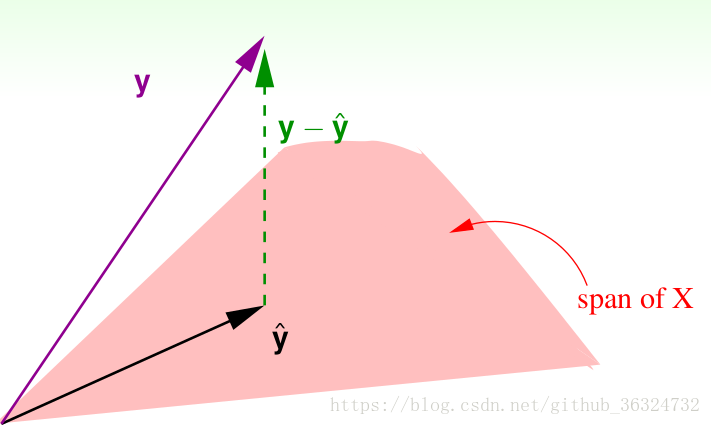
在N维实数空间中,
是N * (d + 1)的
是
的一个线性组合,
下的一个向量,共有d + 1个向量,
在这d + 1个向量所构成的平面
上;
- 所以我们就是要在这个平面
最短。那么只要
在平面上的投影,也就是
时,
- 之前的Hat Matrix
就是进行投影的矩阵。有
,
(
是单位矩阵)
接下来探究一下的性质——
- 对称性(symetric),即
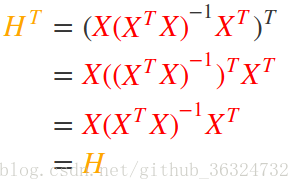
- 幂等性(idempotent),即
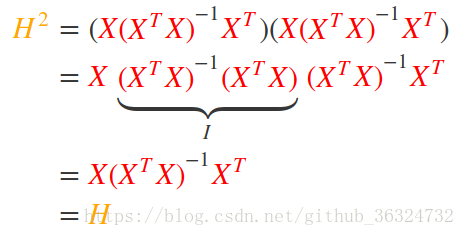
- 半正定(positive semi-definite),即所有特征值为非负数:(以下
为特征值,
为对应的特征向量)
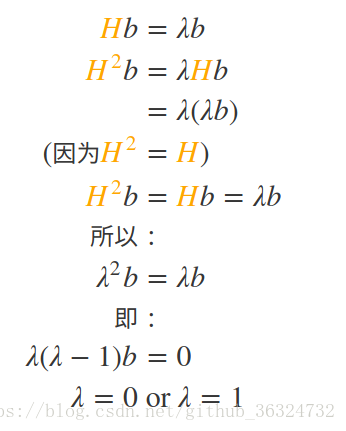
,trace是矩阵的迹。用物理意义来解释这个式子——
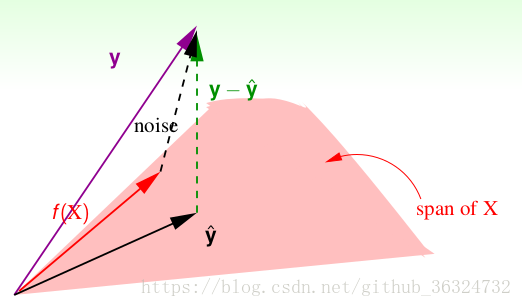
假设,之前已经讲了
作用于向量是得到向量在
上的投影,而
作用于向量得到与
垂直的向量,于是
。
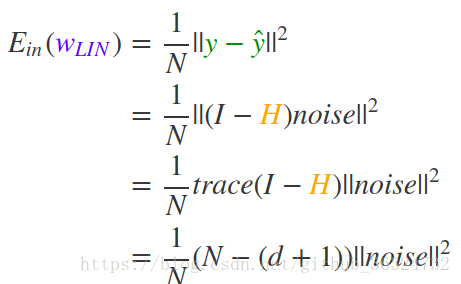
因此就平均而言,有:
这个式子的推导就比较复杂了...
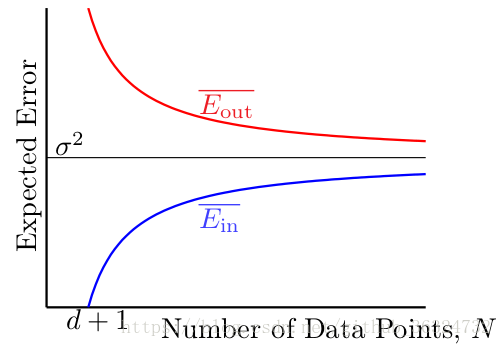
我们就发现与
都收敛于
(noise level),并且他们之间的差被
限制住。
虽然与VC Bound不同,VC Bound是通过最差错误概率来推导与
接近,这里是从平均的角度,仍然能证明LinReg算法能够学习!
Linear Regression for Binary Classification
现在有一个问题就是能不能让线性回归来作线性分类问题呢?
我们看到有下面的差异——

那么如果我们用来做线性分类呢?
- 直观来看,却是可以替代,只是少算了一个sign()的步骤,并且LinReg效率更高;
- 作图来看LinReg的曲线一直在LinClassfication的线之上,因此可以作为linear classification的宽松错误上界。
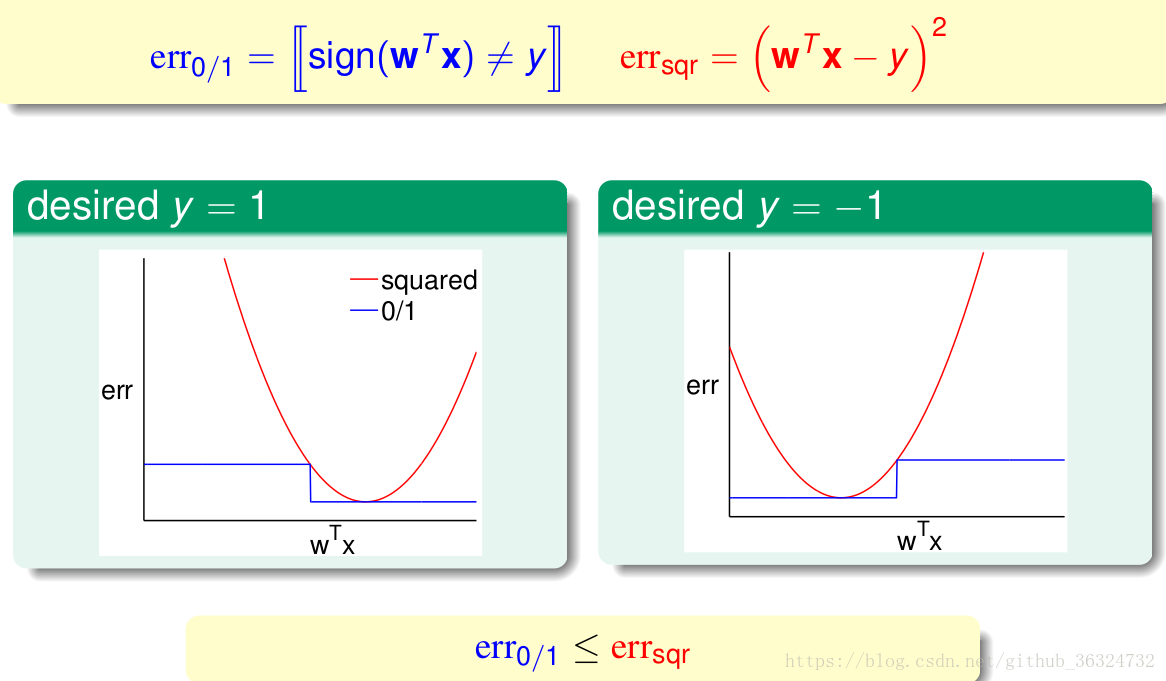
这里的trade-off的对象是算法的效率与error bound的紧密程度。
实际中甚至可以先做一个regression来求一个初始化参数值,然后再应用诸如PLA/Pocket这类的算法降低error。

















 6336
6336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









