



深入理解CNTK中的序列到序列网络实现
 项目地址: https://gitcode.com/gh_mirrors/cn/CNTK
项目地址: https://gitcode.com/gh_mirrors/cn/CNTK 序列到序列网络基础理论
序列到序列(Sequence-to-Sequence, Seq2Seq)网络是深度学习领域中处理变长输入输出序列的重要架构。在CNTK框架中,这种网络结构被广泛应用于机器翻译、语音合成、文本摘要等任务。
网络架构组成
Seq2Seq模型由两个核心组件构成:
- 编码器(Encoder):将输入序列编码为固定维度的上下文向量
- 解码器(Decoder):基于上下文向量生成输出序列
这两个组件通常都采用循环神经网络(RNN)实现,特别是LSTM或GRU单元,以更好地捕捉长距离依赖关系。
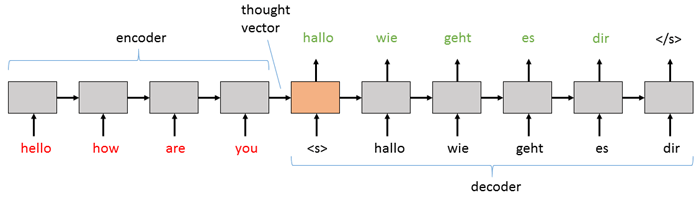
工作原理详解
- 编码阶段:输入序列的每个元素依次通过编码器,最终隐藏状态包含了整个输入序列的压缩表示
- 解码阶段:解码器以编码器的最终隐藏状态作为初始状态,逐步生成输出序列
- 序列生成:解码器使用"序列开始"标记(
)启动生成,每一步的输出作为下一步的输入,直到产生"序列结束"标记()
实战:字母到音素转换
任务定义
字母到音素(Grapheme-to-Phoneme)转换是将单词的拼写形式转换为发音表示的任务。例如:
输入序列(字母):| T | A | N | G | E | R |
输出序列(音素):| ~T | ~AE | ~NG | ~ER | null | null |
数据准备
我们使用CMUDict数据集,这是一个北美英语发音词典。数据已预处理为CNTK文本格式(CTF),包含:
- 训练数据:约34MB
- 验证数据:小于1KB
- 词汇表文件:包含69个音素符号
# 数据读取器实现
def create_reader(path, randomize, size=C.io.INFINITELY_REPEAT):
return C.io.MinibatchSource(C.io.CTFDeserializer(path, C.io.StreamDefs(
features = C.io.StreamDef(field='S0', shape=input_vocab_size, is_sparse=True),
labels = C.io.StreamDef(field='S1', shape=label_vocab_size, is_sparse=True)
), randomize=randomize, max_samples=size)
模型超参数设置
# 模型维度设置
input_vocab_dim = 69 # 输入词汇表大小
label_vocab_dim = 69 # 输出词汇表大小
hidden_dim = 128 # 隐藏层维度
num_layers = 1 # LSTM层数
模型实现关键步骤
1. 输入处理
CNTK使用动态轴(Dynamic Axes)处理变长序列,这是理解序列模型的关键概念:
# 定义输入变量
input_seq_axis = C.Axis('inputAxis')
input_dynamic_axes = [C.Axis.default_batch_axis(), input_seq_axis]
raw_input = C.sequence.input_variable(
shape=(input_vocab_dim),
sequence_axis=input_seq_axis,
name='raw_input'
)
2. LSTM编码器实现
# 创建LSTM编码器
def create_model():
with C.layers.default_options(initial_state=0.1):
# 编码器LSTM
encoder = C.layers.Recurrence(C.layers.LSTM(hidden_dim))
encoded_input = encoder(raw_input)
# 解码器LSTM
decoder = C.layers.Recurrence(C.layers.LSTM(hidden_dim))
decoded_output = decoder(encoded_input)
# 输出层
output = C.layers.Dense(label_vocab_dim)(decoded_output)
return output
3. 训练配置
# 定义损失函数和评估指标
def create_criterion_function(model):
labels = C.sequence.input_variable(label_vocab_dim)
loss = C.cross_entropy_with_softmax(model, labels)
error = C.classification_error(model, labels)
return loss, error
# 创建学习器
learner = C.fsadagrad(
parameters=model.parameters,
lr=C.learning_parameter_schedule_per_sample(0.007),
momentum=C.momentum_schedule_per_sample(0.9)
)
模型训练与评估
训练过程
# 创建训练器
trainer = C.Trainer(
model=model,
criterion=(loss, error),
parameter_learners=[learner],
progress_writers=[progress_writer]
)
# 训练循环
for i in range(max_epochs):
for batch in train_reader:
trainer.train_minibatch(batch)
评估方法
# 验证集评估
def evaluate(reader, model):
total_error = 0
num_batches = 0
for batch in reader:
error = trainer.test_minibatch(batch)
total_error += error
num_batches += 1
return total_error / num_batches
高级主题:注意力机制
基础Seq2Seq模型的局限在于编码器的最终隐藏状态需要捕获整个输入序列的信息。当序列较长时,这会成为瓶颈。注意力机制(Attention Mechanism)通过允许解码器在每一步"关注"输入序列的不同部分来解决这个问题。
# 注意力层实现示例
attention_model = C.layers.AttentionModel(
attention_dim=hidden_dim,
attention_span=20,
attention_axis=input_seq_axis
)(decoded_output, encoded_input)
总结与最佳实践
- 数据预处理:确保输入输出序列使用相同的词汇表和标记化方法
- 超参数调优:根据任务调整隐藏层维度和LSTM层数
- 正则化:使用dropout防止过拟合,特别是在深层网络中
- 批处理:合理设置批大小以平衡训练速度和内存使用
- 监控训练:定期在验证集上评估模型性能
通过CNTK框架实现的序列到序列网络,我们能够高效地处理各种序列转换任务。理解这些核心概念和实现细节,可以帮助开发者构建更强大的自然语言处理应用。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











