ImageBind革命性突破:多模态融合的新范式,一文读懂核心原理
 项目地址: https://gitcode.com/gh_mirrors/im/ImageBind
项目地址: https://gitcode.com/gh_mirrors/im/ImageBind 你是否曾想象过,让计算机像人类一样同时理解图像、声音、文字甚至温度和运动信息?Meta AI的ImageBind项目正在实现这一目标。ImageBind通过构建统一的嵌入空间(Embedding Space),首次实现了六种模态数据的深度融合,开创了人工智能感知世界的新范式。本文将带你深入了解这项突破性技术的核心原理、实现方式和应用前景。
什么是ImageBind?
ImageBind是由Meta AI(原Facebook AI Research)开发的多模态联合嵌入模型,能够将图像/视频、文本、音频、深度、IMU(惯性测量单元)和热成像六种模态的数据映射到同一个高维向量空间中。这意味着计算机第一次可以像人类一样"跨感官"理解世界——例如将一张狗的图片、狗叫声的音频片段和"一只狗"的文字描述识别为具有高度相似性的概念。
项目核心代码结构集中在imagebind/models/目录下,包含了模态预处理、Transformer网络和跨模态映射等关键组件。官方完整说明可参考README.md。
核心技术原理:一个空间,六种模态
统一嵌入空间的构建
ImageBind的革命性在于其"One Embedding Space To Bind Them All"的设计理念。不同于传统多模态模型需要两两配对训练(如图像-文本、音频-文本),ImageBind创新性地以图像作为"中枢模态",通过图像与其他各模态的配对数据,将所有模态统一到同一个嵌入空间。
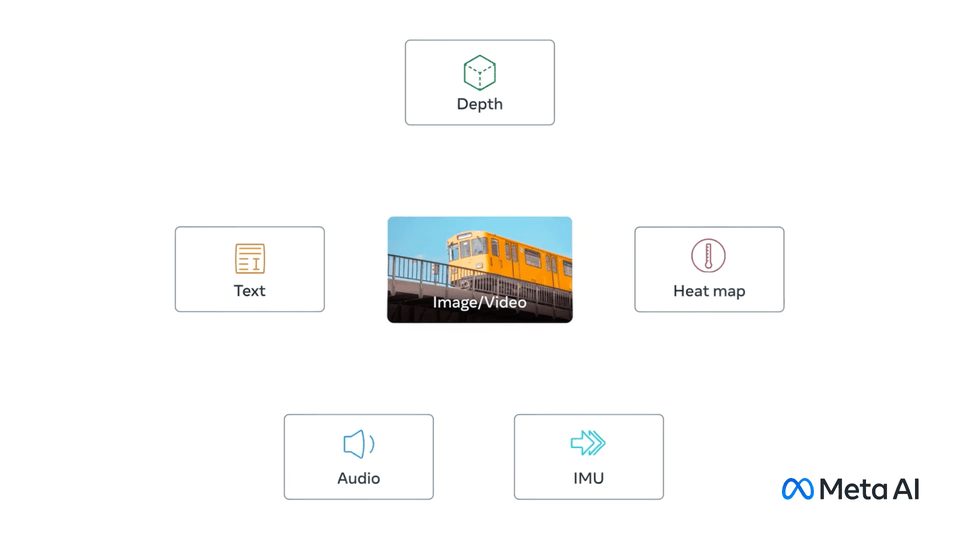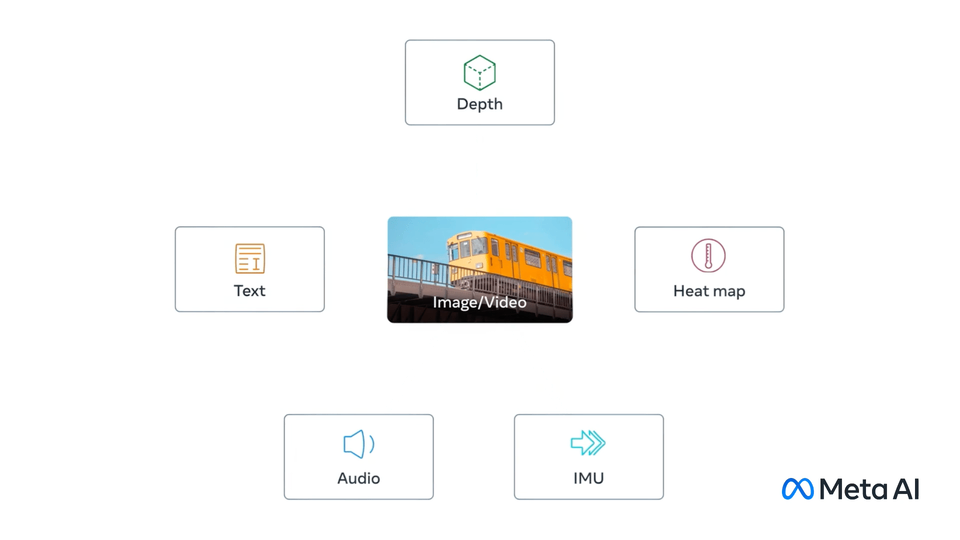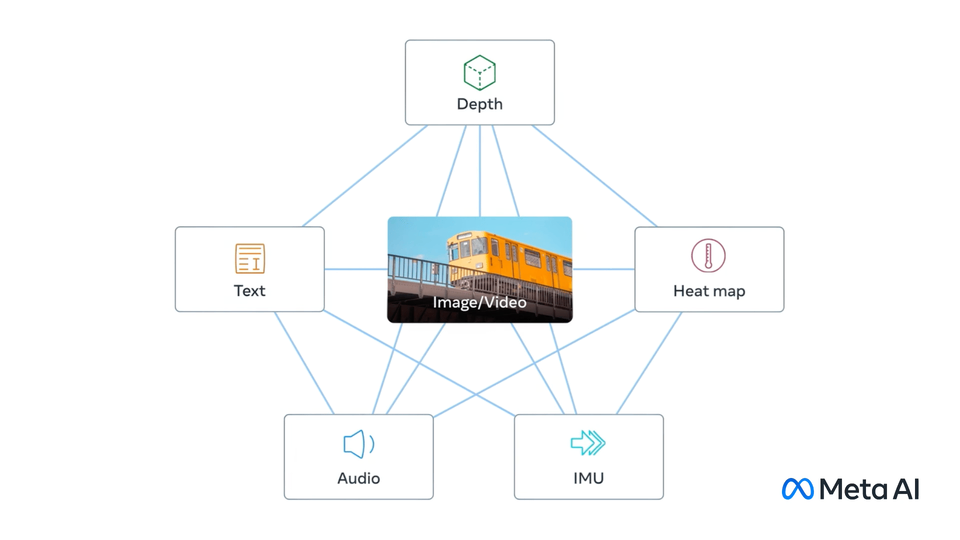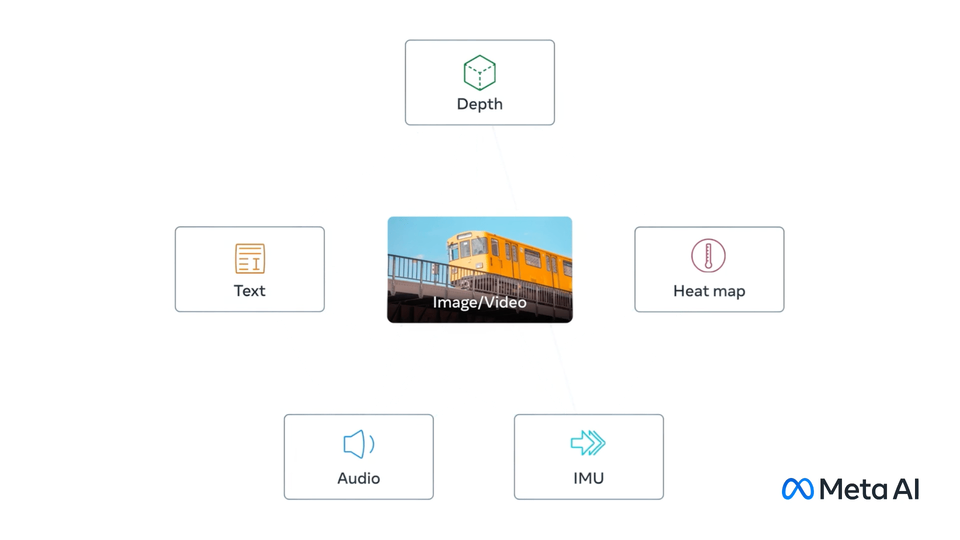
这一架构的关键在于:
- 图像编码器采用预训练的ViT-H模型作为基础
- 其他模态通过与图像的关联学习,将特征映射到共享嵌入空间
- 所有模态最终输出维度相同的向量表示(Embedding)
模态处理流程
ImageBind对每种模态设计了专门的预处理和编码流程:
-
视觉模态:通过imagebind/models/multimodal_preprocessors.py中的
VisionPreprocessor类处理图像输入,提取空间特征并添加位置编码 -
文本模态:使用基于BPE(Byte-Pair Encoding)的分词器(imagebind/models/multimodal_preprocessors.py中的
Tokenizer类)将文本转换为token序列,再通过文本编码器生成嵌入向量 -
音频模态:先将音频波形转换为梅尔频谱图,然后通过专门设计的音频stem网络处理时间序列特征
-
深度、热成像和IMU模态:各自通过特定的预处理管道和编码器,最终都映射到同一嵌入空间
各模态的预处理逻辑集中在multimodal_preprocessors.py,而跨模态注意力机制则在transformer.py中实现。
模型架构详解
ImageBind的整体架构包含三个核心部分:
- 模态预处理模块:负责将不同类型的原始数据转换为模型可处理的特征表示
- 模态主干网络:基于Transformer架构的深度神经网络,提取各模态的高级特征
- 嵌入投影头:将不同模态的特征向量标准化并映射到统一维度的嵌入空间
模型初始化和前向传播逻辑在imagebind_model.py中实现,关键类imagebind_huge定义了完整的模型结构。
# 模型实例化核心代码
model = imagebind_model.imagebind_huge(pretrained=True)
model.eval()
model.to(device)
# 多模态输入处理
inputs = {
ModalityType.TEXT: data.load_and_transform_text(text_list, device),
ModalityType.VISION: data.load_and_transform_vision_data(image_paths, device),
ModalityType.AUDIO: data.load_and_transform_audio_data(audio_paths, device),
# 其他模态输入...
}
# 特征提取
with torch.no_grad():
embeddings = model(inputs)
性能表现与评估
ImageBind在多个基准测试中展现出卓越的跨模态理解能力。根据官方公布的数据,imagebind_huge模型在各项任务上达到了以下性能:
| 模型 | IN1k(图像分类) | K400(视频动作) | NYU-D(深度估计) | ESC(音频分类) | LLVIP(热成像) | Ego4D(IMU) |
|---|---|---|---|---|---|---|
| imagebind_huge | 77.7 | 50.0 | 54.0 | 66.9 | 63.4 | 25.0 |
特别值得注意的是,ImageBind在没有见过特定模态对的情况下,仍能通过嵌入空间的传递性实现跨模态检索。例如,训练时只见过图像-文本和音频-文本的配对,模型却能自动学会图像与音频之间的相似性判断。
完整的模型性能评估指标和测试方法可参考model_card.md。
快速上手:使用ImageBind进行多模态特征提取
环境准备
使用ImageBind非常简单,首先需要安装必要的依赖:
conda create --name imagebind python=3.10 -y
conda activate imagebind
pip install .
Windows用户可能还需要安装soundfile库以处理音频文件:pip install soundfile
基本用法示例
以下代码展示了如何提取图像、文本和音频三种模态的嵌入向量并进行跨模态相似度比较:
from imagebind import data
import torch
from imagebind.models import imagebind_model
from imagebind.models.imagebind_model import ModalityType
# 输入数据
text_list = ["A dog.", "A car", "A bird"]
image_paths = [".assets/dog_image.jpg", ".assets/car_image.jpg", ".assets/bird_image.jpg"]
audio_paths = [".assets/dog_audio.wav", ".assets/car_audio.wav", ".assets/bird_audio.wav"]
# 设备配置
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# 加载模型
model = imagebind_model.imagebind_huge(pretrained=True)
model.eval()
model.to(device)
# 数据预处理
inputs = {
ModalityType.TEXT: data.load_and_transform_text(text_list, device),
ModalityType.VISION: data.load_and_transform_vision_data(image_paths, device),
ModalityType.AUDIO: data.load_and_transform_audio_data(audio_paths, device),
}
# 提取嵌入向量
with torch.no_grad():
embeddings = model(inputs)
# 计算跨模态相似度
print("Vision x Text:", torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.TEXT].T, dim=-1))
print("Audio x Text:", torch.softmax(embeddings[ModalityType.AUDIO] @ embeddings[ModalityType.TEXT].T, dim=-1))
print("Vision x Audio:", torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.AUDIO].T, dim=-1))
运行这段代码,你会看到类似以下的输出,显示不同模态间的相似度矩阵:
Vision x Text: tensor([[9.9761e-01, 2.3694e-03, 1.8612e-05],
[3.3836e-05, 9.9994e-01, 2.4118e-05],
[4.7997e-05, 1.3496e-02, 9.8646e-01]])
Audio x Text: tensor([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
Vision x Audio: tensor([[0.8070, 0.1088, 0.0842],
[0.1036, 0.7884, 0.1079],
[0.0018, 0.0022, 0.9960]])
这些结果表明,模型成功学习到了不同模态间的语义关联——狗的图片与狗叫声的音频相似度最高,汽车图片与汽车音频相似度最高,依此类推。
应用前景与局限性
潜在应用场景
ImageBind开创的多模态融合技术为AI应用打开了全新可能:
- 智能助手:能够同时理解语音指令、视觉场景和文本信息的下一代智能助手
- 自动驾驶:融合摄像头、激光雷达、热成像和声音数据,提升环境感知安全性
- 机器人感知:帮助机器人整合多种传感器数据,实现更自然的人机交互
- 无障碍技术:为视障人士提供多模态信息转换,如将视觉场景转换为音频描述
技术局限性
尽管取得重大突破,ImageBind仍存在一些局限性:
- 训练数据偏差:模型可能继承训练数据中的社会偏见,如model_card.md中所述
- 模态能力不均衡:部分模态(如IMU)的性能受限于训练数据规模
- 计算资源需求:模型较大,需要较强计算能力支持实时应用
总结与展望
ImageBind通过构建统一的多模态嵌入空间,彻底改变了AI处理不同类型数据的方式。这一技术不仅实现了六种模态的深度融合,更为未来人工智能系统提供了一种更接近人类感知世界的方式。
随着技术的不断发展,我们可以期待看到:
- 更多模态的整合(如嗅觉、触觉)
- 模型效率的提升,实现边缘设备部署
- 更精细的跨模态推理能力
ImageBind的源代码已开源,邀请开发者和研究人员共同探索多模态AI的无限可能。完整项目代码和文档可在imagebind/目录中找到。
参考资料
- 官方技术报告:README.md
- 模型卡片与安全说明:model_card.md
- 核心模型实现:imagebind/models/imagebind_model.py
- 模态预处理模块:imagebind/models/multimodal_preprocessors.py
- Transformer架构:imagebind/models/transformer.py
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







