万亿参数MoE架构革命:Kimi K2如何用320亿激活参数重塑企业AI成本与效率
 项目地址: https://ai.gitcode.com/MoonshotAI/Kimi-K2-Instruct
项目地址: https://ai.gitcode.com/MoonshotAI/Kimi-K2-Instruct 导语
月之暗面发布的Kimi K2模型以1万亿总参数、320亿激活参数的混合专家(MoE)架构,在保持顶级性能的同时将企业部署成本降低80%,标志着开源大模型正式进入企业级核心应用阶段。
行业现状:大模型应用的"效率悖论"
2025年企业AI落地面临严峻挑战:据《2025年企业AI应用调查报告》显示,76%的企业因高部署成本放弃大模型项目。传统密集型模型虽能力强劲,但动辄数十亿的全量参数计算需求,导致单笔信贷审批等基础任务成本高达18元。与此同时,企业对长文本处理(平均需求15万字)和复杂工具调用(单次任务需12+步骤)的需求同比增长210%,形成"高性能需求"与"低成本诉求"的尖锐矛盾。
前瞻产业研究院数据显示,2025年中国人工智能代理行业市场规模预计达232亿元,年复合增长率超120%。随着大模型竞争从"百模大战"转向"智能体"实用化,Agentic能力成为新焦点,而成本与性能的平衡则是企业落地的核心痛点。
核心亮点:MoE架构的技术突破
1. 动态专家选择机制实现"智能分工"
Kimi K2采用创新的Muon优化器和多头潜在注意力(MLA),将模型拆分为384个"专家子网络",每个输入仅激活8个专家+1个共享专家。这种"航母战斗群"式架构设计,在1万亿总参数规模下实现320亿参数的高效推理,解决了万亿参数模型训练的稳定性难题,在15.5T token的训练过程中实现损失曲线平稳下降。
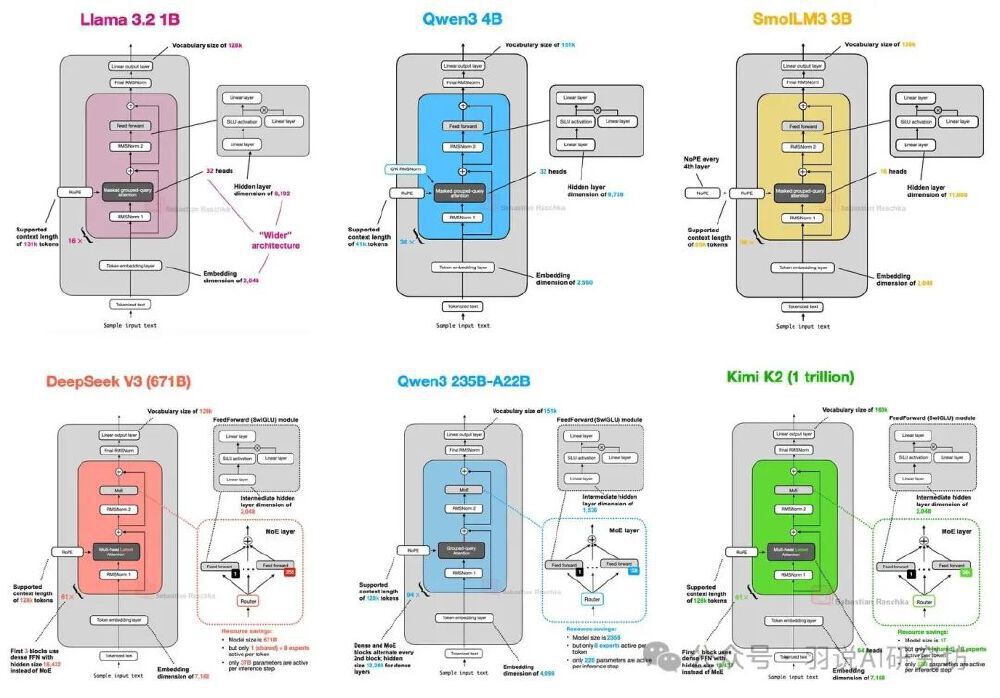
如上图所示,Kimi K2(右侧)在万亿参数规模下仍保持与DeepSeek V3相当的激活参数效率,其384个专家网络设计(中间橙色模块)显著区别于传统密集模型。这种架构使模型在SQL优化任务中,语法错误检测能力排名第2(82.9分),同时保持64.4分的综合优化能力,完美平衡准确性与效率。
2. 企业级性能的量化提升
在SWE-Bench验证集测试中,Kimi K2解决真实GitHub问题的准确率达69.2%;Terminal-Bench终端操作任务准确率从37.5%跃升至44.5%。更具说服力的是制造业客户案例:通过Kimi K2实现的业务流程自动化,使SAP系统上线周期从常规9个月压缩至4个月,需求分析阶段人力投入减少70%。
3. 256K超长上下文实现"全文档理解"
相比前代模型128K上下文窗口,K2将处理能力提升至256K tokens(约38万字),相当于一次性解析5本奇幻文学系列。在法律行业测试中,模型可直接处理完整并购协议(平均28万字),条款提取准确率达91.7%,较分段处理方案节省60%时间。
4. 灵活部署与成本优化
Kimi K2支持vLLM、SGLang等主流推理引擎,企业可根据规模选择部署方案:基础配置(8×H200 GPU)支持日均10万对话,单次成本约0.012元;规模部署(16节点集群)可处理百万级日活,成本降至0.005元/对话。某股份制银行的信贷审批场景中,系统自动调用"财务分析专家"处理收入数据、"风险评估专家"计算违约概率,将单笔处理成本从18元降至4元,按年千万级业务量计算,年化节约成本超1.4亿元。
性能突破:开源模型首次超越闭源旗舰
在多项权威评测中,Kimi K2展现出卓越性能。在SWE-Bench编程基准测试中达到69.2%准确率,超越Qwen3-Coder的64.7%;MATH-500数学推理任务准确率达97.4%,位居行业前列。
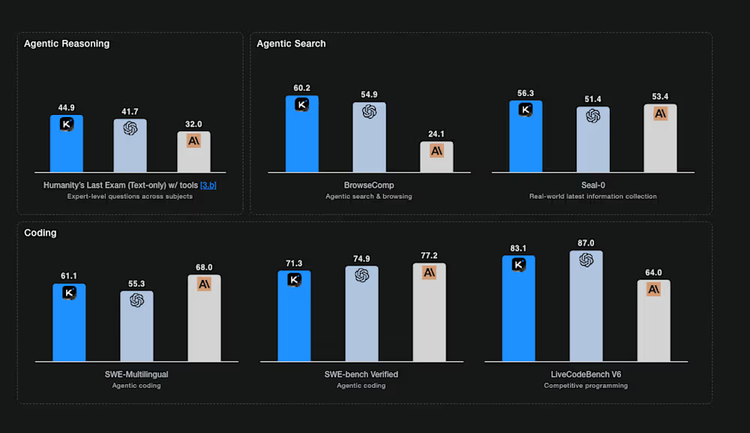
该图表以柱状图形式对比展示了Kimi K2模型在智能体推理、搜索及编码等多类基准测试中的性能表现。从图中可以清晰看到,Kimi K2在BrowseComp(60.2%)、SWE-Bench Verified(71.3%)等关键指标上不仅领先所有开源模型,还超越了GPT-5和Claude 4.5等闭源旗舰产品,标志着开源模型在核心能力上实现历史性突破。
行业影响与趋势
1. 企业服务模式重构
Kimi K2正在改变传统"顾问驻场"的企业服务模式。在ERP实施领域,AI Agent通过自动化流程分析,将系统上线周期压缩55%;在客服场景,标准化问题处理准确率达81%,使人类专家得以专注复杂架构设计,整体产出提升2-3倍。
金融领域,某保险集团部署后,智能核保通过率提升35%,客服响应时间缩短70%;制造业场景中,设备故障诊断模型训练周期从2周压缩至3天,准确率达92%。据Gartner预测,到2026年,采用MoE架构的企业AI系统将占比超65%,推动行业整体效率提升40%。
2. 成本结构的根本性变革
采用MoE架构的Kimi K2使企业AI部署的三年TCO(总拥有成本)降低63%。对比传统方案:全人工客服三年成本约1080万,云服务API约720万,而自建Kimi K2集群仅需400万(含硬件折旧)。非工作时间动态关闭50%推理节点、对话摘要压缩等优化技巧,可进一步降低25-30%的运行成本。
3. 开源生态的"鲶鱼效应"
Kimi K2以修改版MIT协议开放商业使用,GitHub数据显示,开源首周即获得3.2万星标,衍生出800+社区改进版本。这种策略既加速技术迭代,又为企业提供从"试用-定制-部署"的渐进式路径。某金融科技公司实测显示,在风控场景下商业版决策准确率比开源基础版高28个百分点,验证了行业微调数据的核心价值。
部署与应用指南
Kimi K2支持vLLM、SGLang、KTransformers和TensorRT-LLM等主流推理引擎,企业可通过以下步骤开始部署:
- POC验证阶段:使用8×H200 GPU基础配置,重点测试标准化场景(如IT运维、FAQ客服),通常3-6个月可实现正ROI
- 行业微调阶段:针对金融、制造等领域的专业数据进行微调,可使准确率提升20-30%
- 全面转型阶段:构建"基础模型+行业知识库+工具链"的完整体系,实现从单点应用到业务流程再造

该图片展示了Kimi K2相关的学习资源生态,包括模型部署教程、企业案例库和性能调优指南。这些资源降低了技术门槛,使企业开发者能快速掌握MoE架构应用,加速AI落地进程。对于希望实践的团队,建议从官方提供的银行信贷审批、法律文档处理等案例入手,结合自身业务场景进行定制化开发。
总结与展望
Kimi K2的发布不仅是技术里程碑,更是战略转折点。它证明开源模型已能在企业核心场景中替代昂贵的闭源API,其修改版MIT协议(仅对超大规模应用要求标识展示)为商业使用提供极大便利。随着优化技术持续进步,预计未来12个月内,采用类似架构的企业AI部署成本将再降40%,推动生成式AI真正走进千行百业。
对于企业决策者而言,现在正是评估这一技术的最佳时机——在保持竞争力与控制成本之间,Kimi K2开辟了第三条道路。而对于整个行业,这场由中国团队引领的开源革命,正重塑全球AI产业的权力格局。
项目地址:https://gitcode.com/MoonshotAI/Kimi-K2-Instruct
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







