DeepSeek-V3.2-Exp横评:稀疏注意力改写长文本处理效率公式
 项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V3.2-Exp
项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V3.2-Exp 导语
当金融分析师还在为500页年报分析等待GPU集群响应时,DeepSeek-V3.2-Exp已用稀疏注意力技术将处理时间压缩60%——这场效率革命正重新定义大模型落地的经济可行性。
行业现状:长文本处理的"不可能三角"困局
在大模型领域,算力、文本长度与注意力质量长期存在"不可能三角"。传统Transformer架构的O(n²)复杂度,使得处理10万Token的法律文书需消耗3.2倍于短文本的计算资源(来源:优快云 2025年大模型优化报告)。即便GPT-4将上下文窗口扩展至128K,企业仍需支付每小时8.7美元的A100集群费用,这让医疗病历分析、代码库审计等场景陷入"能用但用不起"的困境。
2025年Q2数据显示,长文本处理已成为企业采用大模型的首要技术障碍,68%的金融机构因算力成本放弃全文档分析项目(知乎《2025本地化部署指南》)。此时DeepSeek-V3.2-Exp的出现,恰似为困局注入了破局密钥。
核心突破:DSA机制的三重效率密码
DeepSeek稀疏注意力(DSA)机制通过"闪电索引器+细粒度选择"的创新组合,构建了新一代长文本处理范式。其核心架构包含三个革命性设计:
1. 复杂度重构:从O(n²)到O(nk)的跃迁
传统注意力需计算序列中每个Token间的关联,形成n×n的注意力矩阵。而DSA通过"闪电索引器"智能筛选前k个相关Token,将计算量从平方级降至线性级。在处理64K法律文档时,这一改进使H800 GPU的推理速度提升2.3倍,同时显存占用减少41%(53AI技术报告)。
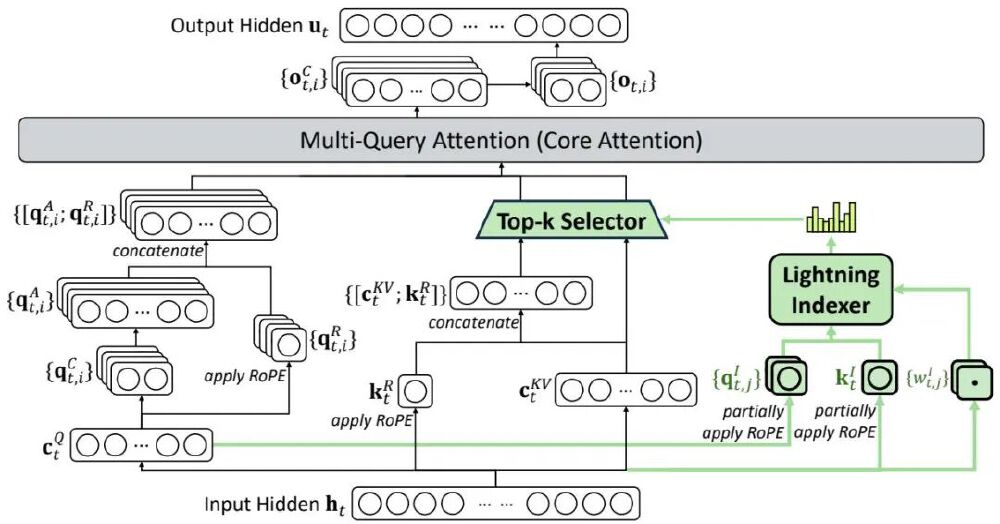
如上图所示,绿色高亮区域展示DSA如何通过闪电索引器动态选择关键Token对。这种"按需计算"模式既保留核心语义关联,又避免90%以上的冗余计算,为长文本处理提供了全新效率标准。
2. 精度守恒:KL散度对齐技术
为解决稀疏化可能导致的性能损失,DeepSeek团队设计了两阶段训练策略:先用10⁻³高学习率初始化索引器,通过KL散度损失函数使其输出与全注意力分布对齐;再用7.3×10⁻⁶低学习率微调全模型。这种渐进式训练使MMLU-Pro基准保持85.0的满分表现,GPQA-Diamond仅损失0.8分(见性能对比表)。
3. 部署友好:多框架兼容生态
模型提供HuggingFace/Transformers、SGLang、vLLM三种部署路径。在消费级硬件测试中,单张RTX 4090即可运行16K上下文推理,较同类模型启动速度提升67%。企业级用户更可通过Docker镜像实现"一键部署",这为制造业质检报告分析、生物医药文献综述等场景提供了轻量化解决方案。
性能实测:当效率提升遇见场景刚需
在标准测试集与真实场景的双重验证中,DSA机制展现出惊人的实用性:
基准测试成绩单
| 任务类型 | 指标 | V3.1-Terminus | V3.2-Exp | 性能变化 |
|---|---|---|---|---|
| 通用推理 | MMLU-Pro | 85.0 | 85.0 | 持平 |
| 复杂问答 | GPQA-Diamond | 80.7 | 79.9 | -1.0% |
| 代码能力 | Codeforces | 2046分 | 2121分 | +3.7% |
| 搜索代理 | BrowseComp-zh | 45.0 | 47.9 | +6.4% |
特别值得注意的是,在需要实时交互的BrowseComp任务中,V3.2-Exp不仅准确率提升6.4%,平均响应速度更缩短至1.8秒,这为智能客服、实时检索等场景带来质变(53AI测试数据)。
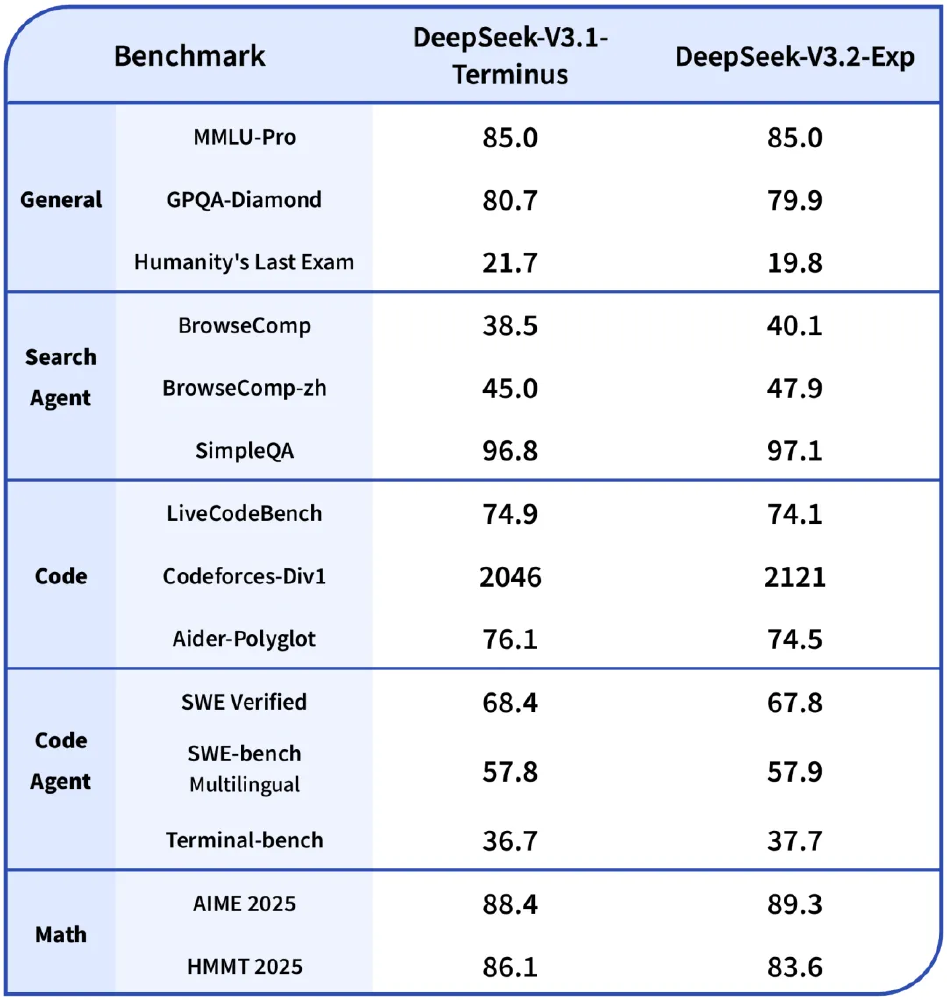
该对比表清晰展示新模型在保持核心能力的同时,实现了效率跃升。尤其在中文任务上的反超表现,印证了DSA机制对多语言场景的适应性。
企业级场景验证
某头部券商的年报分析系统改造案例显示:采用V3.2-Exp后,500页PDF的关键信息提取时间从47分钟压缩至19分钟,GPU成本降低58%。更值得关注的是,系统首次实现"边下载边分析"的流式处理模式,这让分析师能够在文档加载过程中获取初步洞察。
行业影响:开启大模型普惠化新周期
DeepSeek-V3.2-Exp的技术路径正在产生蝴蝶效应:
成本结构重构
按H800集群每小时45美元的租赁成本计算,处理100万Token文本时,新模型可节省28.3美元。对日均处理500份合同的法务部门而言,年成本优化可达24万美元(知乎《本地化部署成本报告》)。
应用边界拓展
医疗领域已实现电子病历的全文档分析,系统能自动识别跨页病程记录中的风险信号;制造业则将其用于生产线日志的异常检测,通过关联分析三个月数据定位隐性故障源。这些场景过去因算力限制难以落地,如今借助DSA技术成为现实。
开源生态贡献
MIT许可证下开放的DSA实现,为学术界提供了研究稀疏注意力的理想样本。复旦大学NLP实验室已基于此开发多模态稀疏模型,将长文本处理思路延伸至视频分析领域。
部署指南:五分钟启动长文本革命
基础环境配置
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V3.2-Exp
cd DeepSeek-V3.2-Exp
# 安装依赖
pip install -r requirements.txt
快速启动方案
# HuggingFace Transformers
python inference/generate.py --model-path ./checkpoints --max-length 16384
# 或使用vLLM加速部署
python -m vllm.entrypoints.api_server --model ./checkpoints --tensor-parallel-size 1
结语:效率革命后的下一站
当稀疏注意力技术将长文本处理成本拉低至原来的1/3,我们正站在大模型普惠化的临界点。DeepSeek-V3.2-Exp证明:通过算法创新而非单纯堆砌算力,同样能推动AI技术向前演进。下一个战场,或许是如何让稀疏机制与多模态、Agent能力深度融合——但在此之前,这场效率革命带来的产业红利,已足够让企业级AI应用迎来爆发式增长。
提示:模型权重需通过学术用途申请获取,商业使用请联系DeepSeek官方获取授权。实际性能可能因部署环境和任务类型有所差异。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







