Qwen3-30B-A3B-Thinking-2507-FP8:新一代推理增强型大语言模型重磅发布
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-30B-A3B-Thinking-2507-FP8
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-30B-A3B-Thinking-2507-FP8 核心升级亮点
在过去三个月的技术攻坚中,研发团队持续深耕Qwen3-30B-A3B模型的推理能力强化,全面提升模型在复杂任务中的思考质量与深度。今日正式推出的Qwen3-30B-A3B-Thinking-2507-FP8版本,带来三大突破性升级:
- 推理性能跨越式提升:在逻辑推理、数学运算、科学分析、代码生成等专业领域的基准测试中表现显著优于前代,尤其在需要人类专家级思维的任务中展现出更强的问题拆解与解决能力。
- 通用能力全面增强:指令遵循精度、工具调用效率、文本生成流畅度及人类偏好对齐度均实现多维优化,日常对话与专业任务处理能力更均衡。
- 超长上下文理解再突破:原生支持256K上下文窗口,文档处理、多轮对话记忆保持能力得到进一步强化,满足企业级长文本分析需求。
特别提示:该版本显著延长了思考过程长度,强烈建议在高复杂度推理场景(如学术研究、工程设计、复杂数据分析)中优先选用。
 图片展示了Qwen3-30B-A3B-Thinking-2507模型的核心技术架构示意图,包含模型参数配置、推理流程与性能优化关键点。这一可视化呈现直观反映了模型在专家系统设计(128选8专家机制)与上下文处理能力上的技术突破,为开发者理解模型底层逻辑提供了重要参考。
图片展示了Qwen3-30B-A3B-Thinking-2507模型的核心技术架构示意图,包含模型参数配置、推理流程与性能优化关键点。这一可视化呈现直观反映了模型在专家系统设计(128选8专家机制)与上下文处理能力上的技术突破,为开发者理解模型底层逻辑提供了重要参考。
模型技术规格详解
本仓库发布的Qwen3-30B-A3B-Thinking-2507-FP8是基于FP8量化技术的优化版本,具备以下核心技术特征:
- 模型类型:因果语言模型(Causal Language Model)
- 训练阶段:预训练与多阶段精调结合
- 参数规模:总参数量305亿,激活参数量33亿
- 非嵌入层参数:299亿
- 网络结构:48层Transformer架构,采用GQA(Grouped Query Attention)注意力机制
- 注意力配置:查询头(Q)32个,键值头(KV)4个
- 专家系统:128个专家网络,每轮推理动态激活8个专家
- 上下文长度:原生支持262,144 tokens(约50万字中文文本)
重要更新:该模型默认启用思考模式,不再需要通过
enable_thinking=True参数手动开启。系统会自动在对话模板中植入思考标记</think>,因此模型输出中仅显示思考内容而无需显式开头标记属于正常现象。
更多技术细节,包括完整基准测试报告、硬件配置要求及推理性能数据,可查阅官方技术博客、代码仓库及开发者文档。
全方位性能评测
通过与业界主流大模型的横向对比,Qwen3-30B-A3B-Thinking-2507-FP8在知识掌握、逻辑推理、工具使用等六大核心维度展现出竞争力:
知识掌握能力
- MMLU-Pro:80.9分(↑2.4分 vs 前代30B模型),接近235B大模型水平
- MMLU-Redux:91.4分(↑1.9分),刷新同参数规模模型纪录
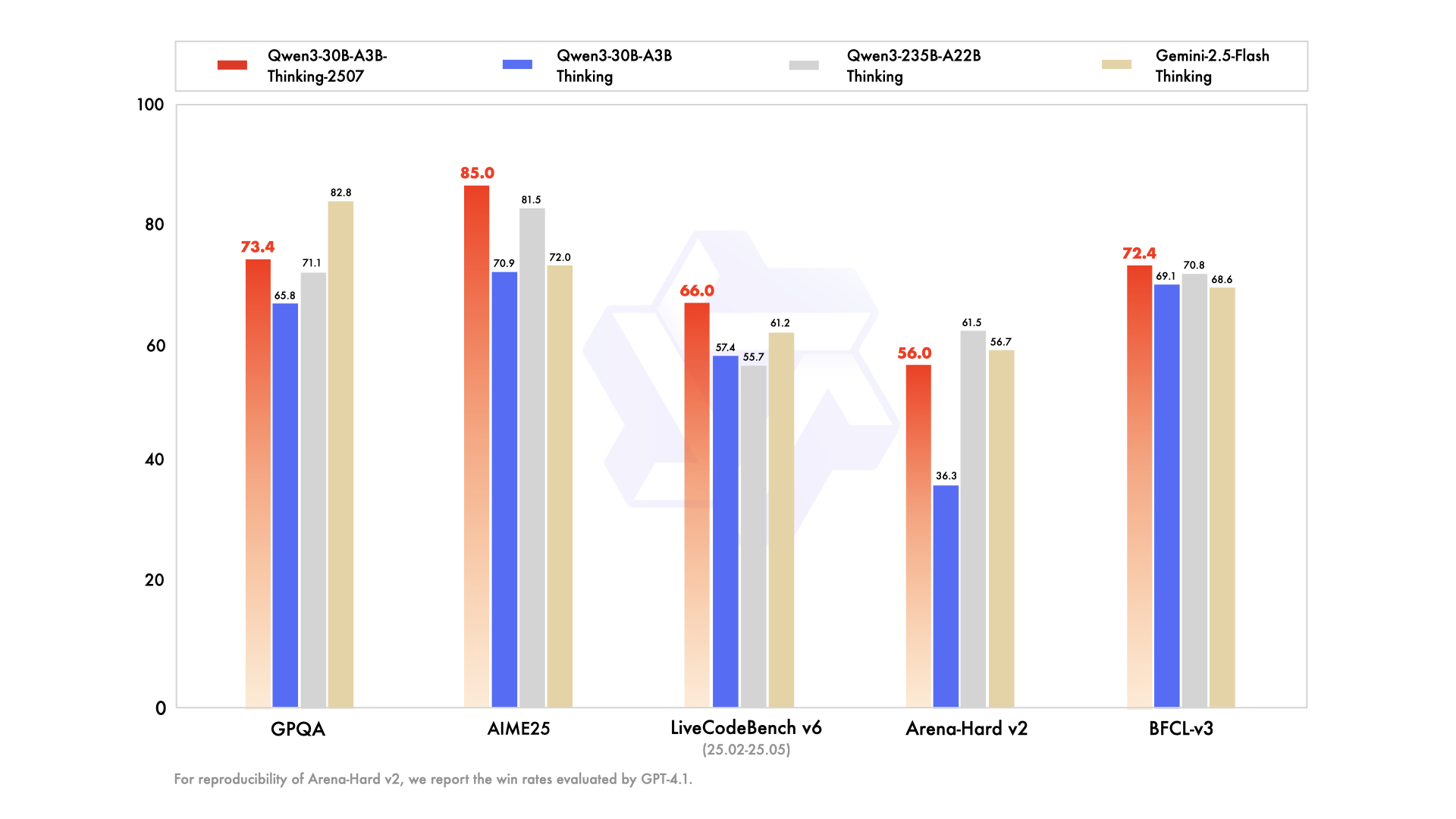
- GPQA:73.4分(↑7.6分),专业领域知识覆盖广度显著提升
- SuperGPQA:56.8分(↑5.0分),复杂问题知识整合能力增强
逻辑推理突破
在数学竞赛级任务中表现尤为突出:
- AIME25(美国数学邀请赛):85.0分,超越Gemini2.5-Flash-Thinking(72.0分)和Qwen3-235B模型(81.5分)
- HMMT25(哈佛-麻省理工数学竞赛):71.4分,较前代提升21.6分,展现出接近人类竞赛选手的解题思路
代码生成能力
- LiveCodeBench v6:66.0分,位列所有参测模型第一,在算法设计与边界条件处理上表现优异
- CFEval:2044分,代码效率评分接近235B模型水平
- OJBench:25.1分,程序正确性与鲁棒性显著提升
对齐与创作能力
- WritingBench:85.0分(↑8.0分),叙事连贯性与创意表达能力领先
- Creative Writing v3:84.4分,接近Gemini2.5-Flash的85.0分
- IFEval:88.9分,指令理解准确率达到行业顶尖水平
智能体能力
在零售、航空、电信等行业场景测试中:
- BFCL-v3:72.4分,多轮工具调用成功率提升3.3分
- TAU2-Airline:58.0分,航班调度问题解决能力超越所有参测模型
- TAU1-Retail:67.8分,客户需求分析准确率较前代提升6.1分
多语言处理
- MultiIF:76.4分,多语言指令遵循能力排名第一
- PolyMATH:52.6分,跨语言数学推理能力接近235B模型水平
测试说明:所有高难度任务(含数学、编程及PolyMATH评测)采用81,920 tokens输出长度,其余任务使用32,768 tokens设置,确保模型有充足思考空间。Arena-Hard v2评分由GPT-4.1进行第三方客观评估。
快速部署指南
该模型已深度集成于Hugging Face transformers库,建议使用最新版本(≥4.51.0)避免兼容性问题(旧版本可能出现KeyError: 'qwen3_moe'错误)。以下为基础推理代码示例:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B-Thinking-2507-FP8"
# 加载分词器与模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto", # 自动选择最优数据类型
device_map="auto" # 自动分配计算资源
)
# 构建对话输入
prompt = "请详细介绍大语言模型的工作原理"
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 生成响应
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768 # 支持超长文本生成
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# 解析思考过程与最终输出
try:
# 通过特殊标记分割思考内容(151668对应`</think>`)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("思考过程:", thinking_content)
print("最终回答:", content)
高效部署方案
-
SGLang部署(推荐用于推理优化):
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B-Thinking-2507-FP8 --context-length 262144 --reasoning-parser deepseek-r1 -
vLLM部署(支持高并发场景):
vllm serve Qwen/Qwen3-30B-A3B-Thinking-2507-FP8 --max-model-len 262144 --enable-reasoning --reasoning-parser deepseek_r1
内存优化提示:若出现显存不足(OOM)问题,可临时降低上下文长度,但为保证推理质量,建议在硬件条件允许时保持131072 tokens以上的上下文设置。本地部署可选用Ollama、LMStudio、llama.cpp等兼容框架。
FP8量化技术优势
本版本采用细粒度FP8量化技术(块大小128),在保持模型性能的同时实现以下优化:
- 存储效率:模型文件体积较BF16版本减少60%,单卡即可部署30B级模型
- 推理速度:在支持FP8计算的GPU(如NVIDIA H100/A100)上,吞吐量提升1.8倍
- 能耗优化:同等任务处理能耗降低45%,符合绿色AI发展趋势
该量化方案已通过transformers、sglang、vllm等主流框架验证,开发者可无缝迁移现有代码,无需额外修改量化相关配置。
智能体应用指南
Qwen3系列模型在工具调用领域表现卓越,推荐结合Qwen-Agent框架实现企业级智能体开发。该框架内置工具调用模板与解析器,大幅降低开发复杂度:
from qwen_agent.agents import Assistant
# 配置语言模型(支持阿里云DashScope或本地部署)
llm_cfg = {
'model': 'qwen3-30b-a3b-thinking-2507-FP8',
'model_type': 'qwen_dashscope', # 阿里云部署方式
# 本地部署示例:
# 'model': 'Qwen3-30B-A3B-Thinking-2507-FP8',
# 'model_server': 'http://localhost:8000/v1',
# 'api_key': 'EMPTY',
# 'generate_cfg': {'thought_in_content': True}
}
# 定义工具集(支持MCP配置、内置工具与自定义工具)
tools = [
{
'mcpServers': {
'time': { # 时间查询工具
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
'fetch': { # 网页抓取工具
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter' # 内置代码解释器
]
# 创建智能体实例
bot = Assistant(llm=llm_cfg, function_list=tools)
# 流式处理用户请求
messages = [{"role": "user", "content": "分析https://qwenlm.github.io/blog/ 中的Qwen3最新进展"}]
for responses in bot.run(messages=messages):
pass
print(responses)
最佳实践:部署时建议关闭推理框架的工具调用解析功能,由Qwen-Agent统一处理思考过程与工具调度,以获得更连贯的推理链条。
性能调优最佳实践
为充分发挥模型性能,建议采用以下配置策略:
1. 采样参数优化
- 推荐配置:Temperature=0.6,TopP=0.95,TopK=20,MinP=0
- 重复抑制:在支持的框架中设置presence_penalty=0.5~2.0(过高可能导致语言混乱)
2. 输出长度设置
- 常规任务:32,768 tokens(约6万字)
- 复杂任务:81,920 tokens(数学竞赛、代码生成、学术写作等)
- 超长文本处理:262,144 tokens(需确保硬件内存≥40GB)
3. 提示词工程规范
- 数学问题:添加"请分步推理,最终答案放入\boxed{}中"
- 选择题:指定JSON输出格式,如
{"answer": "C"} - 代码任务:明确编程语言与功能需求,例:"用Python实现快速排序,要求时间复杂度O(n log n)"
4. 多轮对话管理
历史对话中仅保留最终输出内容,无需包含中间思考过程。Jinja2模板已内置此处理逻辑,非模板调用场景需手动实现。
引用方式
若在研究或商业项目中使用本模型,请按以下格式引用:
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
Qwen3-30B-A3B-Thinking-2507-FP8模型的发布,标志着开源大模型在推理能力与部署效率上的又一次突破。随着模型性能的持续迭代与应用生态的不断完善,Qwen系列正逐步成为企业级AI解决方案的核心引擎,为科研创新与产业升级提供强大算力支持。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







