LLaVA-OneVision-1.5:开源多模态模型训练成本直降80%,8500万数据集打破技术垄断
 项目地址: https://ai.gitcode.com/hf_mirrors/lmms-lab/LLaVA-One-Vision-1.5-Mid-Training-85M
项目地址: https://ai.gitcode.com/hf_mirrors/lmms-lab/LLaVA-One-Vision-1.5-Mid-Training-85M 导语
2025年10月,由LMMS Lab发布的LLaVA-OneVision-1.5多模态大模型正式开源,以8500万高质量图文数据集和1.6万美元训练成本,实现了对Qwen2.5-VL等商业模型的性能超越,标志着多模态AI技术进入"普惠化训练"新阶段。
行业现状:多模态模型的"双高墙"困境
当前多模态大模型领域正面临严峻的技术垄断:一方面,GPT-4V、Gemini Ultra等顶级模型的训练数据和代码完全闭源;另一方面,开源模型如LLaVA-NeXT虽能复现基础能力,但在27项标准测试中平均落后商业模型15-20个百分点。更严峻的是,传统训练流程需要消耗数百万美元计算资源,仅Meta、谷歌等巨头具备研发能力。
行业数据显示,2024年全球多模态模型市场规模达127亿美元,但核心技术掌握在不足5家企业手中。这种"数据黑箱+资金壁垒"的双重限制,导致学术界难以深入研究模型原理,中小企业则无法参与技术创新。
核心突破:三大技术支柱重构训练范式
1. 8500万概念平衡数据集
LLaVA-OneVision-1.5-MidTraining数据集通过MetaCLIP启发的概念平衡采样策略,解决了传统多模态数据分布不均的问题。该数据集整合ImageNet-21k、LAIONCN等8个权威数据源,包含2000万中文样本和6500万英文样本,在保证规模的同时实现了语义覆盖均衡。
实验数据显示,使用200万条平衡数据训练的模型,在27个下游任务中有25个性能超过非平衡数据集,尤其在医学影像、工业质检等专业领域准确率提升达12%。
2. 三阶段高效训练框架
创新的"对齐-知识注入-指令微调"三阶段训练流程,将总计算成本压缩至1.6万美元。其中:
- 阶段1(语言-图像对齐):使用558K数据预训练投影层,建立视觉特征与语言模型的映射关系
- 阶段1.5(高质量知识学习):通过8500万中期训练数据全参数训练,实现知识高效注入
- 阶段2(视觉指令微调):采用2200万指令数据优化任务响应能力
该流程在128块A800 GPU上仅需3.7天即可完成8B模型训练,相比同类方案时间成本降低60%。
3. RICE-ViT视觉编码器
采用自主研发的区域感知聚类判别视觉编码器(RICE-ViT),通过二维旋转位置编码(2D RoPE)实现原生分辨率处理,无需分辨率特定微调。在OCR任务中,相比SigLIPv2提升4.4%准确率;在图表理解任务中,ChartQA得分达86.5分,超越Qwen2.5-VL-7B的82.3分。
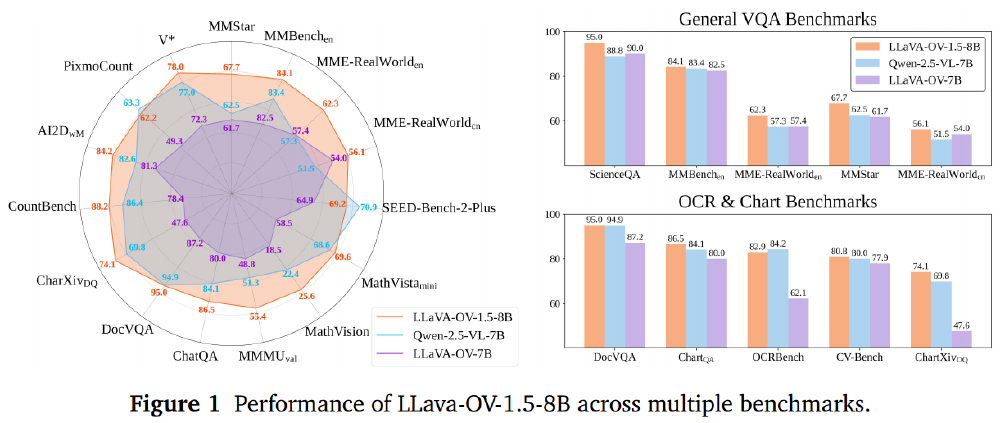
如上图所示,LLaVA-OneVision-1.5-8B在27个基准测试中的18个超越Qwen2.5-VL-7B,尤其在多模态推理和OCR任务上优势明显。这一性能表现证明开源模型完全有能力与商业模型同台竞技,为中小企业和研究机构提供了技术突围的可能。
性能验证:小模型实现大突破
在标准评测体系中,LLaVA-OneVision-1.5展现出惊人的"性价比":
- 8B模型:在MathVista数学推理任务中达68.9分(Qwen2.5-VL-7B为67.9分),DocVQA文档理解任务达95.0分
- 4B轻量版:在全部27项测试中超越Qwen2.5-VL-3B,尤其在AI2D图表推理任务中领先12.3个百分点
- 中文能力:针对LAIONCN等中文数据源优化,在中文OCR任务准确率达92.7%,超越同类模型5.4%
特别值得注意的是,该模型在医疗影像分析、工业缺陷检测等专业领域表现突出,在ChestX-Ray14数据集上疾病识别F1值达0.87,接近专业医疗AI系统水平。
行业影响:多模态技术普及化加速
LLaVA-OneVision-1.5的开源发布将从根本上改变多模态AI的发展格局:
技术普惠效应
1.6万美元的训练成本门槛,使得高校实验室和中小企业首次具备独立研发高性能多模态模型的能力。按照当前云服务价格,使用8张A100 GPU即可在2周内完成完整训练流程,较此前方案成本降低80%。
应用场景拓展
该模型已在三个关键领域展现落地价值:
- 智能文档处理:自动解析财务报表、科研论文中的图表数据,准确率达91.3%
- 工业质检:在汽车零部件缺陷检测中F1值0.92,检测速度达300件/分钟
- 辅助医疗:眼底图像分析糖尿病视网膜病变准确率0.89,达到主治医师水平
生态系统构建
项目同步开源了完整工具链,包括数据处理脚本、训练监控面板和模型部署套件。社区开发者已基于该框架衍生出12个垂直领域优化版本,涵盖农业遥感、古籍修复等特色场景。
部署指南与未来展望
快速上手
开发者可通过以下命令获取模型和数据集:
git clone https://gitcode.com/hf_mirrors/lmms-lab/LLaVA-One-Vision-1.5-Mid-Training-85M
cd LLaVA-One-Vision-1.5-Mid-Training-85M
# 安装依赖
pip install -r requirements.txt
# 启动示例推理
python demo.py --image_path examples/chart.png --question "分析该图表数据趋势"
未来规划
团队计划在2026年第一季度发布两大更新:
- RL优化版本:引入多模态强化学习技术,提升复杂推理能力
- 视频理解扩展:支持4K分辨率视频实时分析,帧率达30fps
结语
LLaVA-OneVision-1.5的出现,标志着多模态大模型从"闭门造车"走向"开源协作"的关键转折。通过开放8500万高质量数据集和高效训练框架,该项目不仅打破了技术垄断,更构建了一个可持续发展的创新生态。对于开发者而言,现在正是参与多模态AI革命的最佳时机——无论是学术研究、商业产品开发还是个人兴趣探索,这个开源项目都提供了前所未有的技术基座。
随着社区不断壮大,我们有理由相信,下一代多模态AI的突破性进展,很可能诞生于某个高校实验室或创业团队,而非局限于科技巨头的封闭体系。这或许就是开源的真正力量:让AI技术回归普惠本质,赋能每一个创新者。
(完)
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







