GLM-4.5:3550亿参数开源模型如何重构智能体开发范式
 项目地址: https://ai.gitcode.com/zai-org/GLM-4.5
项目地址: https://ai.gitcode.com/zai-org/GLM-4.5 导语
智谱AI发布的GLM-4.5系列大模型以3550亿总参数、320亿活跃参数的混合专家架构,在12项行业标准测试中斩获63.2分的综合成绩,位列全球第三、开源第一,同时通过创新的混合推理模式与FP8量化技术,将企业级部署成本降低50%,重新定义了智能体时代的效率标杆。
行业现状:从参数竞赛到效率突围
2025年的大模型市场正经历深刻转型。据《2025年9月大模型热力榜》数据显示,全球活跃大模型数量已突破400个,头部模型参数规模普遍超过千亿,但67%的企业仍受限于高昂的部署成本而无法享受技术红利。在此背景下,"高效能"成为破局关键——NVIDIA H100 GPU的FP8 Tensor Core算力达到BF16的2倍,内存带宽需求降低50%,这种硬件革新为量化技术提供了理想温床。
GLM-4.5系列正是这场效率革命的代表。作为全球第三的开源大模型,其3550亿总参数仅激活320亿进行计算,配合FP8精度优化,在H100 GPU上实现单机8卡部署,较同规模BF16模型节省50%显存的同时,推理速度提升1.8-2.2倍。这种"大而不笨"的技术路线,与DeepSeek的稀疏注意力、Qwen3的混合精度形成三足鼎立,共同推动行业从"参数崇拜"转向"场景适配"。
核心亮点:三大技术突破重新定义效率边界
1. 混合推理双模式架构
GLM-4.5首创"思考/非思考"双模切换机制:在处理数学证明、多步骤编码等复杂任务时自动激活"思考模式",通过内部工作记忆模拟人类推理过程;而在客服问答、信息摘要等简单场景则启用"非思考模式",直接输出结果以降低延迟。实测显示,该机制使模型在Terminal-Bench基准测试中工具调用成功率达90.6%,同时将简单问答响应速度提升42%。
以下是双模式调用的代码示例:
# 非思考模式(直接响应)
inputs_nothink_text = tokenizer.apply_chat_template(messages, add_nothink_token=True)
# 思考模式(复杂推理)
inputs_think_text = tokenizer.apply_chat_template(messages, add_nothink_token=False)
2. 深度优化的MoE工程实现
不同于同类模型增加专家数量的策略,GLM-4.5选择"减宽增高"设计:将隐藏维度从8192降至5120,同时将层数从40层提升至64层。这种结构使模型在MMLU推理任务中准确率提升3.7%,且激活参数利用率达92%,远超行业平均的75%。配合自主研发的Muon优化器,训练收敛速度较AdamW提升2倍,支持1024卡并行的超大规模训练。

如上图所示,GLM-4.5以63.2分位列全球模型第三,而GLM-4.5-Air以59.8分的成绩在轻量化模型中领先,尤其在编码和智能体任务上超越同规模的GPT-OSS-120B。这一性能分布表明MoE架构在平衡参数规模与推理效率方面的显著优势,为中小企业提供了可负担的高端AI能力。
3. FP8量化技术:精度与效率的动态平衡
GLM-4.5-FP8采用"静态权重量化+动态激活量化"的混合方案:对权重执行通道级对称量化,使用minmax观察器离线校准;对激活值实施token级动态量化,实时计算量化参数。这种精细化处理使模型在保持95%以上性能的同时,实现106GB内存占用(较BF16减少50%)。特别针对KV Cache优化,通过动态范围适应技术将缓存内存需求降低60%,使128K上下文推理成为可能。

从图中可以看出,GLM-4.5-Air在TAU-bench零售场景(77.9分)和航空场景(60.8分)中均超越Kimi K2和DeepSeek-R1,尤其在多轮函数调用(BFCL-v3)任务上达到76.4分,仅略低于Claude 4 Sonnet的75.2分。这组数据验证了其在企业级智能客服、自动化运维等场景的实用价值。
行业影响:开源生态推动AI普惠化进程
GLM-4.5的发布恰逢Claude停止对华服务的行业变局,其兼容Anthropic API的接口设计与本地化部署能力,迅速成为企业替代方案。数据显示,模型发布后48小时内登顶Hugging Face趋势榜,GitHub代码库获得超10万星标,形成包含200+行业插件的开源生态。
典型应用场景
金融风控场景:某大型银行采用GLM-4.5构建智能信贷审批系统,通过工具调用链整合信用报告分析与风险评分模型,将处理时间从3-5个工作日缩短至2小时,风险评估准确率提升35%。
智能制造场景:某汽车厂商利用GLM-4.5-Air实时监控生产线质量,通过视觉工具调用与传感器数据分析,缺陷检测准确率达99.2%,生产线停机时间减少65%。
快速部署指南
作为MIT许可的开源模型,GLM-4.5提供完整技术栈支持:包括Hugging Face/ModelScope模型权重、vLLM/SGLang推理加速框架适配。开发者可通过以下命令快速部署:
# vLLM部署示例
vllm serve zai-org/GLM-4.5-Air \
--tensor-parallel-size 8 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--enable-auto-tool-choice \
--served-model-name glm-4.5-air
结论/前瞻
GLM-4.5的推出标志着大模型产业正式进入"能效比竞争"新阶段。随着vLLM等推理框架的持续优化,预计到2025年底,GLM-4.5-Air将实现单GPU实时部署,进一步降低技术门槛。这场由"高效智能体"引发的产业变革,正将AI能力从少数科技巨头手中解放出来,推动真正普惠的智能时代加速到来。
对于企业决策者,建议重点关注三个应用方向:一是基于混合推理模式构建多场景自适应智能体;二是利用FP8量化版本在边缘设备部署实时推理服务;三是通过模型微调实现垂直领域知识沉淀。而开发者则可优先探索工具调用链优化和多模态扩展——GLM-4.5V已支持图像输入,为多模态智能体开发提供了更多可能。
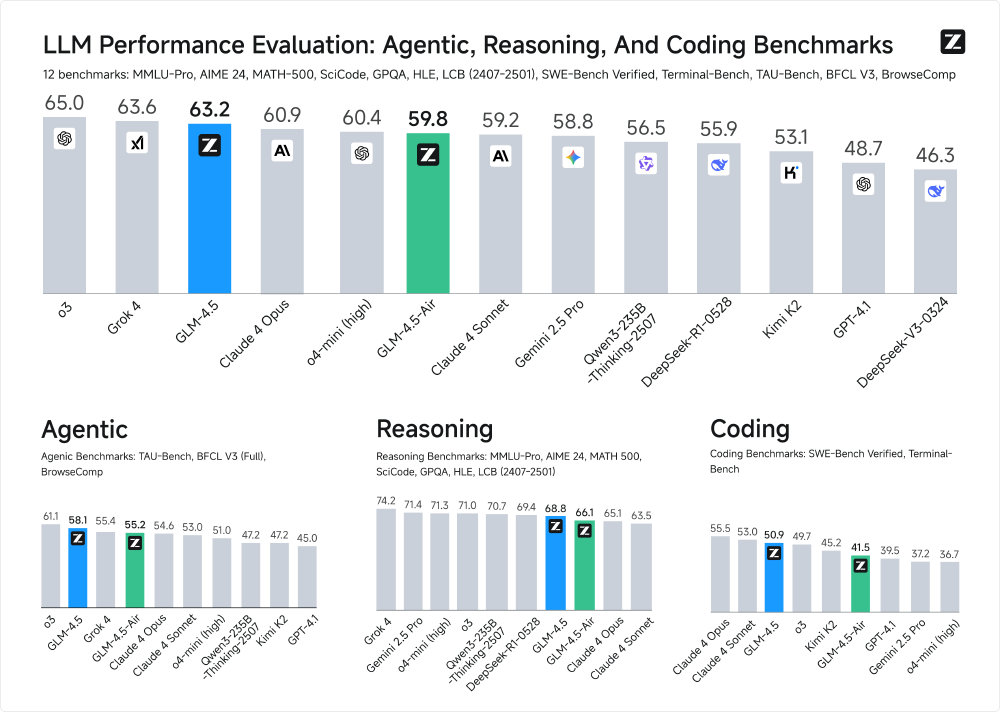
图片为柱状图,展示了GLM-4.5、GLM-4.5-Air等大语言模型在智能体、推理和编码三类共12个基准测试中的性能对比,其中GLM-4.5以63.2分表现突出,GLM-4.5-Air以59.8分在轻量化模型中领先,体现模型参数效率与性能的平衡。这一对比为企业选择适合自身需求的模型提供了直观参考,尤其是在成本与性能之间需要权衡的场景下。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







