DeepSeek-V3.2-Exp发布:稀疏注意力技术重塑大模型效率边界
 项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V3.2-Exp
项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V3.2-Exp 导语
深度求索(DeepSeek)推出实验性大模型DeepSeek-V3.2-Exp,通过创新稀疏注意力机制将长文本处理效率提升50%,同时保持模型性能基本不变,为企业级AI应用落地提供新选择。
行业现状:效率与成本的双重挑战
2025年中国大模型市场正处于技术迭代加速与场景落地深化的关键阶段。据权威机构《2025年全球LLM行业分析》显示,全球大语言模型产业市场总规模预计突破3000亿美元,年复合增长率稳定在35%以上,亚太地区增速领先达到42%。医疗(21.9%)和金融(12.8%)成为大模型应用渗透最深的领域,但企业级用户普遍面临长文本处理效率低、算力成本高的双重挑战。
随着Agent应用兴起,模型对上下文理解能力的需求激增,传统稠密注意力机制已难以满足企业对低成本、高效率的部署要求。技术社区《2025开源大模型效率边界分析》指出,在处理超过10万字的法律文档、代码库或科学论文时,现有模型的计算成本呈指数级增长,这成为制约大模型商业化落地的主要瓶颈之一。
核心亮点:稀疏注意力技术实现效率跃升
DeepSeek Sparse Attention机制革新
DeepSeek-V3.2-Exp最显著的突破在于引入了DeepSeek Sparse Attention(DSA)稀疏注意力机制。这种细粒度稀疏化技术在保持模型性能基本不变的前提下,大幅降低了长文本处理的计算开销。官方测试数据显示,在Prefilling(预填充)和Decoding(解码)场景中,新模型相比上一代V3.1-Terminus均展现出明显的效率优势。

如上图所示,左图展示了在Prefilling场景下不同Token位置的推理成本对比,右图则呈现了Decoding场景的成本差异。可以清晰看到,DSA技术在长序列处理中展现出更优的成本控制能力,这为企业处理海量文档、代码库等长文本场景提供了实质性的效率提升。
性能与效率的平衡
在性能保持方面,通过严格对齐训练设置的对比测试显示,新模型在General、Search Agent、Code等多个领域的公开评测集上表现与V3.1-Terminus基本持平。这种"零性能损失"的效率提升,使得DSA技术具备了快速商业化落地的潜力。
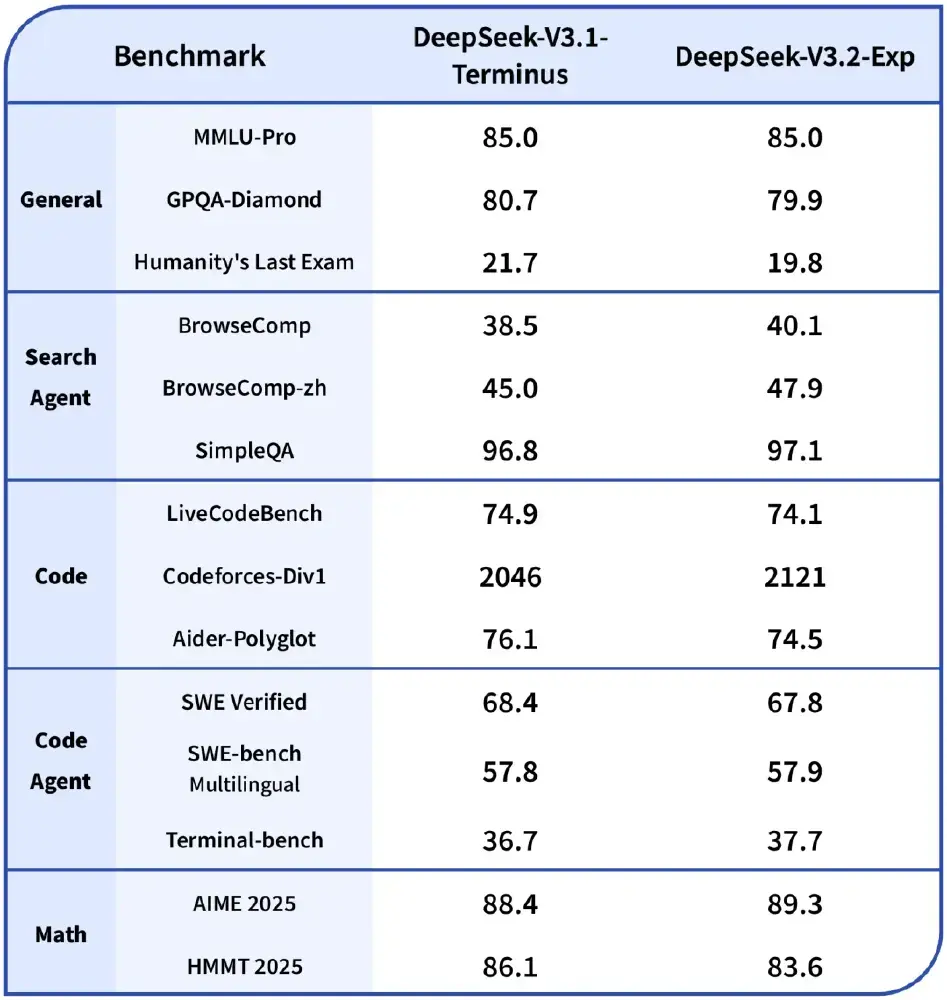
该表格详细展示了DeepSeek-V3.2-Exp与V3.1-Terminus在各领域基准测试中的得分情况。数据显示,新模型在保持性能竞争力的同时,实现了计算效率的突破,这种平衡对于企业级应用具有重要价值。
开源生态与部署灵活性
深度求索同步开源了TileLang与CUDA两种版本的算子,其中TileLang版本便于研究性实验的快速迭代,而CUDA版本则针对生产环境进行了深度优化。这种"双轨制"开源策略,既满足了学术界的探索需求,也为工业界提供了高效部署选项。
模型支持HuggingFace、SGLang、vLLM等多种本地运行方式,开源内核设计便于研究,采用MIT许可证,为企业提供了灵活的部署选择。无论是在云端服务器还是本地数据中心,企业都能根据自身需求选择最适合的部署方案。
行业影响与趋势
开源大模型的商业化加速
DeepSeek-V3.2-Exp的技术突破已迅速转化为实际应用价值。11月27日,DeepSeek基于该模型推出的DeepSeekMath-V2数学推理模型,在IMO 2025和CMO 2024中均达到金牌水平,Putnam 2024获118/120分的优异成绩。这一成果验证了稀疏注意力机制在高精度推理场景下的可靠性,为垂直领域应用开辟了新路径。
在企业级应用方面,开源大模型正成为企业AI新引擎。据《2025开源大模型+软件创新应用典型案例》报告显示,VMWare、IBM等16家企业已成功部署开源大模型于代码生成、客户服务等场景。随着DeepSeek-V3.2-Exp的推出,预计将有更多企业选择混合使用开源和封闭模型,建立AI"协调层"调用最适合的模型完成特定任务。
稀疏化技术引领效率革命
DeepSeek于2025年2月提出Native Sparse Attention(NSA)技术,解决传统稀疏注意力训练与推理阶段能力下降问题。该技术实现训练与推理全流程兼容,在64K上下文任务中,后向传播速度提升6倍,解码速度提升11.6倍,显著降低计算成本。
DeepSeek-V3.2-Exp-Base通过创新的稀疏注意力机制将长文本处理效率提升50%以上,同时API调用成本降低过半,这种"效率优先"的技术路线正成为大模型发展的新趋势。随着算力成本持续高企,企业对模型效率的关注度将进一步提升,稀疏化技术有望成为下一代大模型的标配。
结论与建议
DeepSeek-V3.2-Exp通过引入创新的稀疏注意力机制,在保持模型性能的同时实现了长文本处理效率的显著提升,为企业级AI应用落地提供了新的技术路径。该模型的推出不仅展示了开源大模型在效率优化方面的巨大潜力,也为行业树立了性能与成本平衡的新标准。
对于企业用户,建议重点关注以下方向:
- 评估稀疏注意力技术在长文本场景(如法律文档分析、代码库理解、科学论文处理)的应用潜力
- 探索混合部署策略,结合开源模型与商业API,优化AI应用的总体拥有成本
- 关注稀疏化技术与多模态能力、Agent架构的融合趋势,提前布局下一代智能应用
未来,随着稀疏化技术的不断成熟和开源生态的持续完善,大模型应用的效率边界将进一步拓展,为更多行业带来AI赋能的新机遇。
获取DeepSeek-V3.2-Exp的完整代码和文档,请访问项目仓库:https://gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V3.2-Exp
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







