20倍效率革新!小米开源MiDashengLM-7B,重构多模态音频理解范式
【免费下载链接】midashenglm-7b  项目地址: https://ai.gitcode.com/hf_mirrors/mispeech/midashenglm-7b
项目地址: https://ai.gitcode.com/hf_mirrors/mispeech/midashenglm-7b
导语
小米正式开源多模态音频大模型MiDashengLM-7B,通过创新的"通用音频描述"技术路线实现20倍吞吐量提升,在22项国际评测中刷新SOTA成绩,重新定义智能设备的"听觉理解"能力。
行业现状:音频AI的三大痛点与破局机遇
2025年全球音频AI市场规模预计突破80亿美元,但行业普遍面临效率低下、模态割裂与数据黑箱三大痛点。传统模型处理30秒音频的最大batch size仅为8,80GB GPU利用率不足15%;语音、环境声、音乐模型各自为战,无法实现统一语义理解;70%商业模型未公开训练数据细节,形成技术垄断。
在此背景下,小米选择全量开源策略,完整披露77个数据源的配比细节与从音频编码器预训练到指令微调的全流程。这种透明度在行业实属罕见——对比Qwen2.5-Omni等闭源模型,MiDashengLM的技术可复现性为学术界和企业开发者提供了宝贵的研究基底。
核心亮点:从技术突破到场景落地
1. 通用音频描述:超越ASR的范式革命
MiDashengLM最核心的突破在于采用"通用音频描述"替代传统ASR转录。不同于Qwen2.5-Omni等模型依赖语音转文字的单一模态对齐,该模型将所有音频转化为结构化文本描述。例如对一段咖啡厅录音,系统会生成:"热闹的咖啡馆里,右侧有女士的清脆笑声,背景有意式浓缩咖啡机的嘶嘶声与蒸汽声,爵士三重奏轻柔演奏"。
这种描述包含语音内容、环境声音、音乐风格等多维信息,实现从"声波识别"到"场景理解"的跨越。技术路径对比显示,传统ASR仅保留约40%音频信息,而Caption描述法则能达到95%+的信息保留率,支持语音/音乐/环境声的多模态统一理解。
2. 20倍效率跃升的工程奇迹
通过动态音频分块与低秩适配(LoRA)技术,MiDashengLM实现吞吐量20倍提升。在80GB GPU测试中,传统模型处理30秒音频的最大batch size仅为8,而该模型可支持512,单样本首Token延迟(TTFT)从0.36秒降至0.09秒。
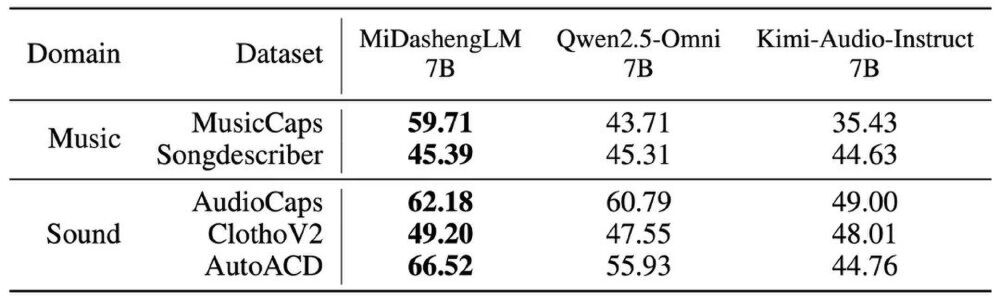
如上图所示,表格对比了MiDashengLM 7B、Qwen2.5-Omni 7B、Kimi-Audio-Instruct 7B在音乐(MusicCaps、Songdescriber)和声音(AudioCaps、ClothoV2、AutoACD)领域数据集上的性能表现。MiDashengLM在绝大多数任务中均处于领先地位,尤其在MusicCaps数据集上达到59.71的FENSE分数,远超Qwen2.5-Omni的43.71,展示其在音乐理解方面的显著优势。
3. 38,662小时的ACAVCaps数据集革命
支撑这一突破的是小米构建的ACAVCaps数据集。该数据集采用"多专家分析管道"生成标注:语音专家提取转录文本,音乐专家识别乐器类型,声学专家分析环境特征,最后由DeepSeek-R1大模型融合为自然描述。数据集涵盖纯语音、纯音乐、混合声等6大类场景,词汇量达64万,远超传统数据集的45万。
性能验证:22项评测刷新SOTA
MiDashengLM在国际权威评测中展现全面优势,尤其在非语音音频理解领域实现碾压性领先:
在环境声分类任务中,模型在VGGSound数据集上准确率达52.11%,远超Qwen2.5-Omni的0.97%;VoxLingua107语言识别准确率93.41%,领先竞品42个百分点。这种泛化能力源于其"语义理解而非特征匹配"的技术路线。
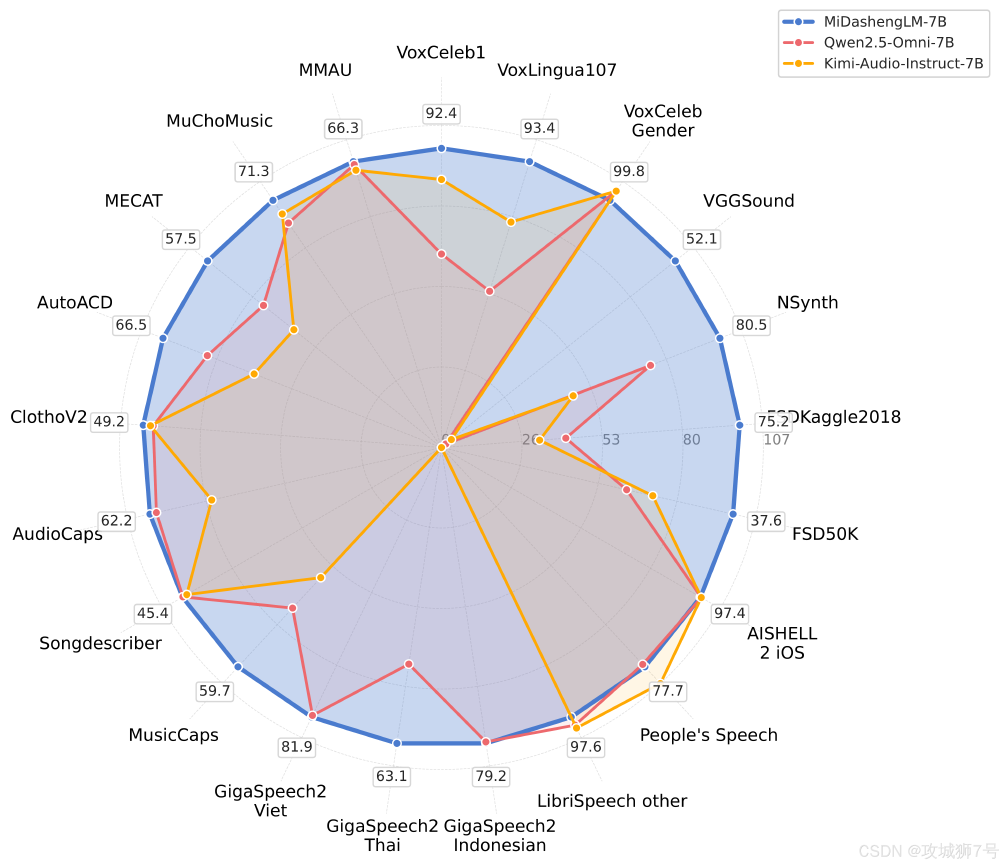
这是一张雷达图,对比了MiDashengLM-7B(蓝色)、Qwen2.5-Omni-7B(红色)和Kimi-Audio-Instruct-7B(橙色)在MMAU、VoxLingua107、VGGSound等多项音频评测指标上的性能表现。MiDashengLM在6项指标中处于领先,尤其在环境声理解和多语言识别上优势显著,体现其"全能听觉"特性。
多语言支持方面,模型在印尼语、泰语等低资源语言上表现突出,其中印尼语WER(词错误率)达到20.8,优于Qwen2.5-Omni的21.2,展现出强大的跨语言适应能力,暗示了小米"人车家"生态出海的技术潜力。
行业影响:开源生态与场景落地
1. 已落地30+场景的技术验证
作为小米"人车家全生态"战略的核心技术支柱,MiDashengLM的底层音频编码器Xiaomi Dasheng已在小米产品中落地30余项创新功能:
- 智能家居:通过"打个响指"等环境音关联IoT控制,异常声音监控(如婴儿啼哭、玻璃破碎)准确率达96.3%
- 智能汽车:车外唤醒防御系统可区分真实唤醒词与录音攻击,准确率99.2%;小米SU7搭载的声音定位功能可识别救护车方向并在地图标记
- 智能手机:小米YU7增强哨兵模式通过声音识别实现划车检测,误报率<0.5%
2. 全链路开源降低创新门槛
小米采取全链路开放策略:
- 模型权重:提供fp32/bf16两种精度下载,后者可节省50%显存
- 训练代码:公开从数据处理到微调的完整Pipeline
- 评估工具:发布MECAT基准测试集,含2,000+音频样本
开发者可通过简单代码调用实现音频理解:
from transformers import AutoModelForCausalLM, AutoProcessor
model = AutoModelForCausalLM.from_pretrained(
"hf_mirrors/mispeech/midashenglm-7b",
torch_dtype="bfloat16"
)
processor = AutoProcessor.from_pretrained("hf_mirrors/mispeech/midashenglm-7b")
# 处理音频并生成描述
inputs = processor(audio="example.wav", return_tensors="pt")
output = model.generate(**inputs, max_new_tokens=100)
print(processor.decode(output[0]))
未来展望:从技术突破到体验升级
小米计划在2025年底前实现三大升级:
- 效率再提升:通过模型蒸馏技术,将端侧模型压缩至1.8B参数,保持90%性能的同时降低50%计算资源消耗
- 功能扩展:支持基于自然语言指令的声音编辑,如"将这段音频的背景乐替换为古典钢琴"
- 多模态融合:与视觉模型深度整合,实现"音视频联合理解",提升复杂场景感知能力
总结:音频AI的"iPhone时刻"
MiDashengLM-7B的开源,标志着音频AI从"专用系统"向"通用智能"的跨越。正如小米"人车家全生态"战略所展现的,未来设备将不仅"听见"指令,更能"理解"场景与情感。随着多模态交互成为AI发展主流,这一模型的开源将加速声音理解技术的普及化。
对于开发者,现在正是基于MiDashengLM构建下一代音频AI应用的最佳时机——无论是优化智能家居交互,还是开发创新的声音分析工具,这个开源模型都提供了坚实的技术基础。小米用实际行动证明:在AI竞赛中,场景定义技术而非技术定义场景。这种务实的创新路径,或许正是中国AI企业实现弯道超车的关键所在。
行动指南:
- 开发者:访问GitCode仓库https://gitcode.com/hf_mirrors/mispeech/midashenglm-7b获取模型
- 企业用户:申请小米AI开放平台API进行定制化部署
- 研究者:参与MECAT基准评测,推动技术边界
随着技术的不断迭代,我们有理由相信,音频理解将成为AI交互的"新基建",为智能设备赋予真正的"听觉智能"。
【免费下载链接】midashenglm-7b 项目地址: https://ai.gitcode.com/hf_mirrors/mispeech/midashenglm-7b
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







