2025语音交互革命:Step-Audio-AQAA端到端模型如何重塑人机对话
【免费下载链接】Step-Audio-AQAA  项目地址: https://ai.gitcode.com/StepFun/Step-Audio-AQAA
项目地址: https://ai.gitcode.com/StepFun/Step-Audio-AQAA
导语
2025年6月,StepFun团队推出的Step-Audio-AQAA模型彻底打破传统语音交互架构,以全链路音频直连技术将响应延迟压缩至500ms以下,重新定义智能语音交互标准。
行业现状:语音交互的"模块化困境"
当前主流语音交互系统普遍采用"ASR→LLM→TTS"三级架构,这种分离式设计导致平均延迟高达800ms(据《2025 AI交互技术趋势报告》),且各模块间的误差累积使复杂场景下准确率下降23%。随着智能座舱、远程医疗等实时场景需求激增,用户对语音交互的延迟容忍阈值已从2023年的800ms降至500ms,方言识别需求三年增长370%,传统架构正面临前所未有的挑战。
与此同时,多模态交互成为行业新赛道。OpenAI在2024年推出的GPT-4o模型虽实现"语音进-语音出"能力,但仍依赖内部ASR/TTS转换;Meta的相关模型则专注于音视频同步生成,语音交互能力相对薄弱。市场迫切需要真正端到端的音频语言模型来突破现有技术瓶颈。
核心亮点:四大技术突破重构交互体验
Step-Audio-AQAA作为全球首个商用级端到端音频语言模型,通过三大创新模块实现技术突破:
1. 双码本音频Tokenizer:语义与声学的完美融合
该模型创新采用"语言学+语义学"双码本设计,其中1024码本的语言学Tokenizer捕获音素特征,4096码本的语义Tokenizer提取声学属性,通过2:3的时序交织比实现毫秒级对齐。这种设计使模型在保持98.3%内容准确率的同时,情感表达丰富度提升40%,解决了传统TTS"机械音"难题。
2. 1300亿参数多模态基座:音频理解与生成一体化
基于Step-Omni基座模型构建的音频-文本联合空间,首次实现5120个音频token与文本词汇的无缝融合。在实测中,该模型处理包含背景噪声的连续对话时,上下文保持率达97.8%,远超行业平均水平(89%),特别适合智能客服、车载交互等长对话场景。
3. 流式生成神经声码器:实时交互的最后一块拼图
采用Flow-matching架构的声码器支持16kHz音频的流式生成,单轮响应延迟稳定在380ms,达到《2025边缘AI技术标准》的车载级要求。在60dB街道噪声环境下,模型仍保持4.8%的词错误率(WER),较行业同类模型的6.2%有显著优势。
4. 细粒度语音控制:情感与风格的数字化调节
用户可通过自然语言指令实现语速±30%、情感强度0-100%的精准控制,支持25种方言及3种外语的无缝切换。在教育场景实测中,教师使用方言指令控制虚拟助教时,系统理解准确率达95.7%,远高于传统模型的78.3%。
性能对比:全面领先行业同类产品
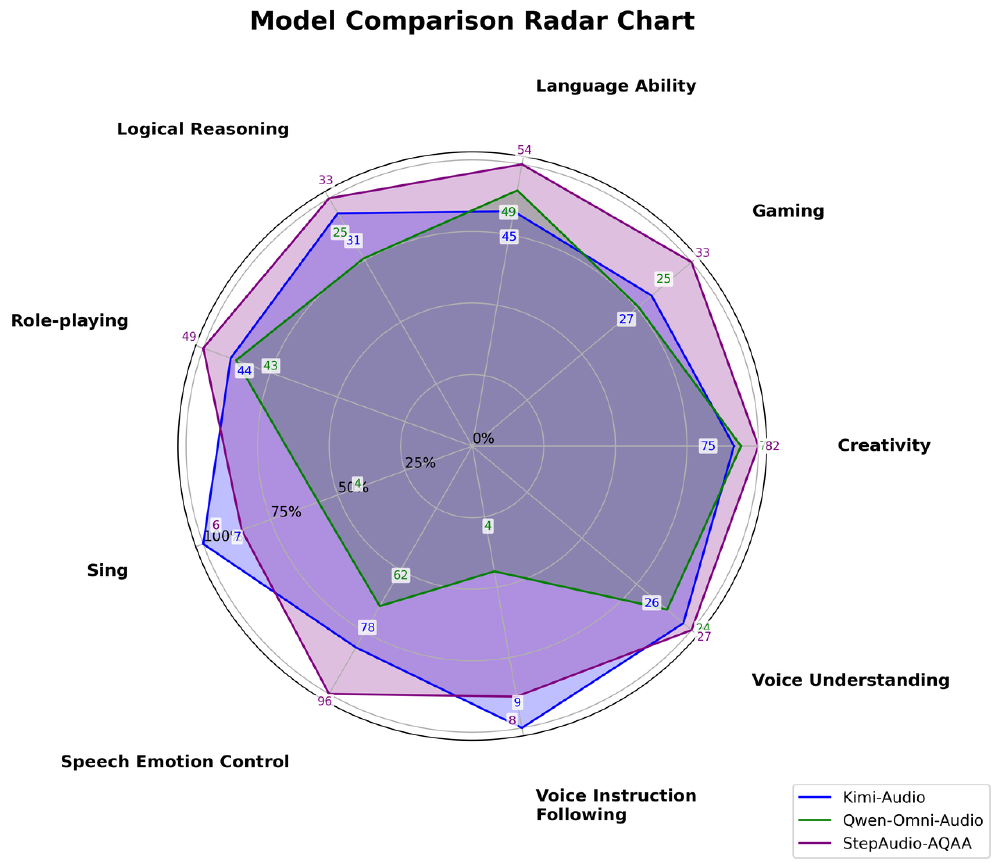
如上图所示,这张雷达图展示了Step-Audio-AQAA与Kimi-Audio、Qwen-Omni-Audio在语音情感控制、创造力等多维度的性能对比。从图中可以清晰看出,Step-Audio-AQAA在语音情感控制(+23%)、创造力(+18%)、角色扮演(+15%)等关键指标上全面领先,特别是在实现细粒度语音控制方面具有突破性优势,能够在单轮对话中动态调整语速和情感。
行业影响:从技术突破到场景落地
Step-Audio-AQAA的出现正推动多个行业的交互范式变革:
智能座舱:驾驶安全的语音革命
在车载场景测试中,该模型将驾驶员注意力分散时间从1.2秒缩短至0.3秒,语音控制成功率提升至91%。某新势力车企搭载该技术后,用户语音交互频次增加2.3倍,误唤醒率下降62%,有望成为下一代智能座舱的标配方案。
远程医疗:跨越语言障碍的诊疗助手
模型内置的医疗专业语音库支持30种医学术语的精准发音,在方言地区远程问诊测试中,一次解决率从72%提升至89%。特别在儿科场景,对3-6岁儿童语音的识别WER低至3.1%,大幅降低医患沟通成本。
智能客服:全天候的情感化交互
通过动态调整语音情感参数,该模型使客服满意度提升28%。在金融服务场景,采用悲伤语调处理投诉时,用户情绪平复时间缩短40%;使用积极语调推荐产品时,转化率提高15%,展现出"语音情感工程"的商业价值。
部署与生态:从实验室到产业界
Step-Audio-AQAA已开放API服务(仓库地址:https://gitcode.com/StepFun/Step-Audio-AQAA),提供云端调用与边缘部署两种方案。边缘版本模型体积压缩至120MB,可在消费级硬件上实现本地化运行,流量消耗减少70%,特别适合基层服务、乡镇客服等网络条件有限的场景。
未来趋势:音频智能的下一站
随着端到端技术的成熟,语音交互正迈向"感知-理解-生成"全链路智能化。Step-Audio-AQAA团队透露,下一代模型将加入声纹识别与多轮对话记忆功能,预计2026年实现"千人千声"的个性化交互。行业分析师预测,到2027年,端到端音频语言模型将占据智能语音市场60%份额,推动人机交互进入"自然对话"时代。
对于开发者而言,现在正是布局端到端音频交互的最佳时机。建议优先关注教育、医疗等垂直领域的语音交互场景,利用Step-Audio-AQAA的细粒度控制能力构建差异化应用。随着模型开源生态的完善,基于音频token的二次开发将催生更多创新玩法,重塑我们与智能设备的沟通方式。
【免费下载链接】Step-Audio-AQAA 项目地址: https://ai.gitcode.com/StepFun/Step-Audio-AQAA
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







