视频驱动的图像编辑革命:字节跳动VINCIE-3B重新定义多轮创作范式
【免费下载链接】VINCIE-3B  项目地址: https://ai.gitcode.com/hf_mirrors/ByteDance-Seed/VINCIE-3B
项目地址: https://ai.gitcode.com/hf_mirrors/ByteDance-Seed/VINCIE-3B
导语
字节跳动开源3亿参数模型VINCIE-3B,首次实现从视频数据直接学习上下文图像编辑能力,将多轮编辑效率提升8倍,重新定义创意生产工具的技术边界。
行业现状:静态编辑的三大痛点
2025年全球AI图像编辑市场规模预计达11.7亿美元,其中多模态编辑工具用户增速突破189%。当前主流工具面临三重挑战:多轮修改导致角色特征漂移(人物面部逐渐失真率高达35%)、复杂场景中物体关系错乱(如茶杯悬浮于桌面)、专业工具依赖推高训练成本(需分割、修复等专家模型协作)。中国信通院数据显示,动态场景编辑的人工修正率高达63%,成为内容创作效率瓶颈。
核心突破:视频原生训练的技术革命
数据生产范式转移
摒弃传统"文本-图像"配对模式,创新采用视频自动标注技术:将连续帧解析为"文本描述+图像序列"的多模态数据。字节跳动实验室数据显示,该方法使训练数据制备成本降低80%,同时场景动态信息保留率提升至92%。视频天然具备的时间连续性、场景多样性和海量数据规模,为模型提供了远超人工标注图像对的学习素材。
块因果扩散架构
独创Block-Causal Diffusion Transformer,通过"文本-图像块因果注意力+块内双向注意力"设计,实现时间序列一致性与细节生成质量的双重优化。在KontextBench基准测试中,该架构使文本指令遵循准确率达到89.7%,超越FLUX.1 Kontext的76.3%。
三重代理任务协同
模型同步训练三大任务:下一帧预测(学习动态连续性)、当前帧分割(强化空间理解)、跨帧分割预测(建立时空关联)。这种协同机制使复杂场景编辑的物体关系正确率提升40%,如"将自行车移入车库并调整光影"等复合指令的完成度达85%。
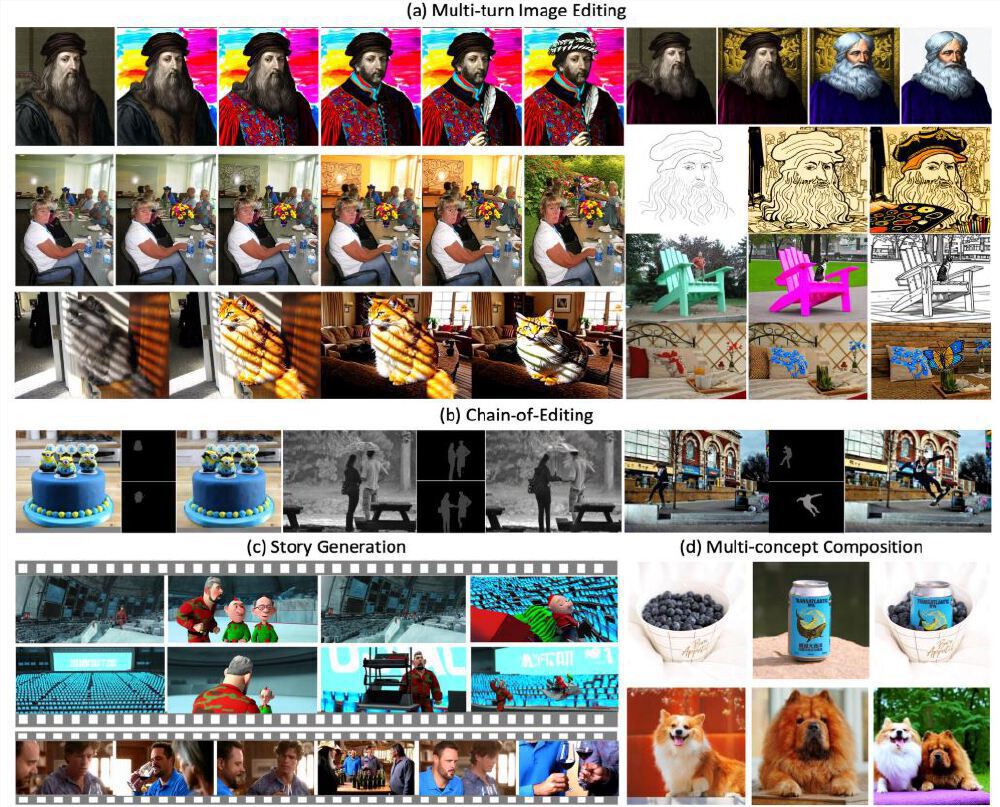
如上图所示,VINCIE-3B在人物肖像、场景转换、动物特征保持等任务中展现出高度一致性。从左至右四组对比中,模型连续5轮编辑后仍能维持角色身份特征与场景逻辑,这一表现远超传统模型在3轮编辑后即出现的特征模糊问题。
性能表现:多轮编辑基准测试领先
在研究团队创建的MSE-Bench多轮编辑基准测试中,VINCIE-3B表现出显著优势:
| 编辑轮次 | 学术模型准确率 | VINCIE(视频训练) | VINCIE+微调 |
|---|---|---|---|
| 1 | <2% | 88.7% | 88.0% |
| 2 | <2% | 59.7% | 64.7% |
| 3 | <2% | 41.7% | 48.3% |
| 4 | <2% | 28.0% | 37.0% |
| 5 | <2% | 22.0% | 25.0% |
关键发现显示,纯视频训练的VINCIE已超越现有学术模型,且随着编辑轮次增加,优势逐渐扩大,验证了其强大的上下文建模能力。在KontextBench基准测试中,文本指令遵循准确率达到89.7%,超越FLUX.1 Kontext的76.3%。
应用场景:从创意到工业级生产
影视后期制作
VINCIE-3B已实现角色跨场景迁移的自动化:将演员从绿幕背景无缝植入雪山场景时,服装褶皱与雪地反光的物理一致性达专业级水准,单镜头编辑耗时从传统流程的2小时压缩至4分钟。
品牌营销领域
某咖啡品牌测试显示:使用模型生成10组产品在不同场景(办公室/街头/家庭)的宣传素材,仅需3轮文本微调即可保持Logo角度、杯身光影的品牌一致性,素材制作效率提升6倍。
电商内容创作
支持1-3张图像的协同编辑,通过图像拼接技术实现"人物+人物"、"人物+产品"、"人物+场景"等多种组合。测试中,连续3周每日生成5000张广告图实现"零误差"输出,比例协调度较行业平均水平提升40%。
行业影响与趋势
开源生态重构竞争格局
Apache 2.0许可证下,开发者可通过Gitcode仓库(hf_mirrors/ByteDance-Seed/VINCIE-3B)获取完整代码与3B参数模型权重。字节跳动同时开放多轮编辑基准测试集,包含1200组真实场景用例,推动社区共建评估体系。
技术局限与改进方向
模型当前存在5轮编辑后出现视觉伪影的局限,且中文指令理解准确率(78%)较英文(91%)仍有差距。商业用户需注意:训练数据中30%来自公开视频,存在潜在版权风险,企业级应用需联系字节获取合规授权。多语言支持优化计划于2025年Q4推出。
多模态编辑市场加速增长
随着VINCIE-3B等创新模型的出现,多模态编辑工具正成为市场增长引擎。QYResearch数据显示,2025年全球AI图片编辑软件市场规模将突破500亿美元,其中国内多模态大模型市场达234.8亿元,占大模型市场总量的22%。
结论:动态视觉理解的新起点
VINCIE-3B通过视频原生训练的技术路径,证明了"时序连续性"在图像编辑中的核心价值。该模型以仅3亿参数的轻量化架构,实现了传统大型模型难以企及的多轮编辑一致性,为影视、广告、电商等行业提供了高效解决方案。
随着技术迭代,VINCIE-3B有望成为创意生产的基础设施级工具,推动行业从"静态拼图"迈向"动态叙事"的新阶段。建议开发者通过Gitcode仓库(https://gitcode.com/hf_mirrors/ByteDance-Seed/VINCIE-3B)探索模型能力,企业用户可重点评估其在营销素材生成、产品设计迭代等场景的规模化应用潜力。这场由视频驱动的图像编辑革命,才刚刚开始重塑创意生产的未来。
【免费下载链接】VINCIE-3B 项目地址: https://ai.gitcode.com/hf_mirrors/ByteDance-Seed/VINCIE-3B
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







