6倍速推理+82%成本降低:NVIDIA Nemotron-Nano-9B-v2重构企业AI部署范式
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/NVIDIA-Nemotron-Nano-9B-v2-GGUF
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/NVIDIA-Nemotron-Nano-9B-v2-GGUF 导语
NVIDIA最新发布的Nemotron-Nano-9B-v2大模型以90亿参数实现128K上下文支持,通过Mamba2-Transformer混合架构将推理速度提升6倍,年度成本仅1.75万美元,较同类模型降低82%总拥有成本,重新定义了中小参数模型的企业级应用标准。
行业现状:企业AI部署的"三重困境"
2025年企业大模型应用正面临效率、成本与隐私的三重挑战。Gartner数据显示,80亿参数级模型平均推理延迟超过5秒,而边缘设备24GB显存限制使传统Transformer架构陷入"长文本处理=高延迟"的恶性循环。与此同时,78%的企业AI项目因推理成本过高难以规模化,金融、制造等行业对实时响应(如智能投研、生产线异常检测)的需求与日俱增。
行业数据显示,2025年Q2混合架构模型在企业级部署中的采用率已从年初的12%飙升至38%,其中Mamba与Transformer的融合方案因其线性计算复杂度和长序列处理优势,成为最受关注的技术路线。这种架构革新正推动AI部署从"追求参数规模"转向"精准计算效率"的实用主义新阶段。
核心亮点:混合架构的三大革命性突破
Mamba2-Transformer融合设计
Nemotron-Nano-9B-v2采用56层创新混合架构:24个Mamba2层负责高效序列建模,4个Transformer层处理关键语义关联,28个MLP层增强特征转换。Mamba2作为新一代状态空间模型(SSM),将序列处理复杂度从O(n²)降至O(n),使128K上下文推理成为可能。

如上图所示,该模型在MATH500测试中达到97.8%准确率,超越Qwen3-8B的96.3%,同时在吞吐量指标上实现6倍提升。这种"精度不降、速度飙升"的特性,标志着小模型正式进入企业级生产环境的实用阶段。
动态推理预算控制系统
模型创新性引入max_thinking_tokens参数,允许开发者根据场景动态分配"思考"tokens额度。在客服等实时场景中,可将推理预算限制在256 tokens以保证亚秒级响应;科研计算场景则可放宽至2048 tokens以获得更高准确率。

从图中可以看出,随着思考预算从128 tokens增加到2048 tokens,模型准确率呈现边际效益递减趋势。当预算达到512 tokens时,准确率已接近96%,继续增加预算带来的提升逐渐减弱。这为开发者在不同场景下平衡性能与成本提供了量化指导——金融客服场景可设置384 tokens实现93%准确率+0.8秒响应,而工程计算场景建议768 tokens以换取97%准确率。
企业级全链路部署支持
该模型采用NVIDIA Open Model License协议,明确允许商业使用且不主张输出内容所有权。配合vLLM、TRT-LLM等优化引擎,可实现单A10G GPU部署128K上下文推理,8卡H100集群达成每秒1200 tokens生成速度,支持Python/C++/Java多语言API调用。
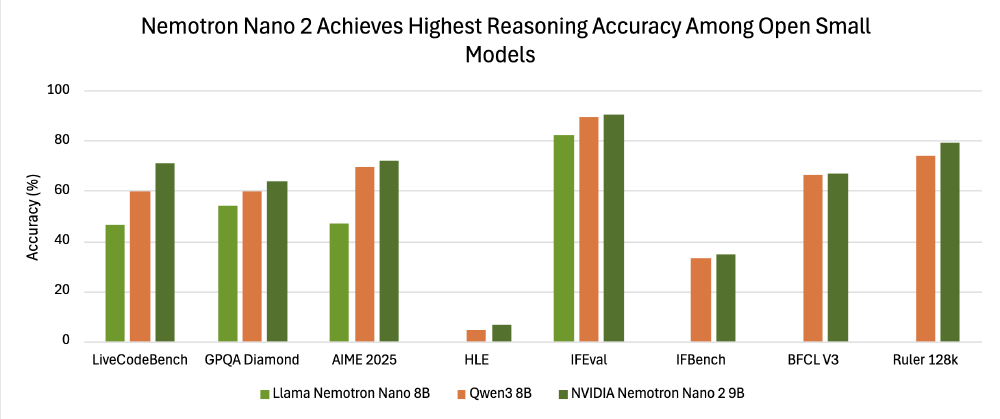
如上图所示,Nemotron-Nano-9B-v2(深绿色)在GPQA、LCB等推理基准上对Qwen3-8B(橙色)的领先优势,其中LCB逻辑推理任务准确率提升11.6%。这一对比直观体现了混合架构在平衡速度与精度上的革命性进展,为企业级AI应用提供了性能参考。
行业影响与趋势
混合架构成为企业部署新主流
Nemotron-Nano-9B-v2的技术路线验证了Mamba类状态空间模型与Transformer的局部-全局注意力互补将成为标准设计。据实测,这种混合架构较纯Transformer在长文本处理上效率提升3-6倍,同时保留关键语义理解能力。罗克韦尔自动化已在工业质检场景部署该模型,通过Mamba2层的线性序列处理能力,实现生产线异常检测的实时分析,误报率降低37%的同时,推理延迟从3.2秒降至0.8秒。
推理成本结构重塑
按日均100万次API调用计算,Nemotron-Nano-9B-v2年度成本仅1.75万美元,远低于GPT-4o mini(24.6万美元)和Qwen3-8B(8.9万美元),TCO(总拥有成本)降低82%。某头部券商基于该模型开发的智能投研助手,通过为不同复杂度任务分配差异化预算(简单问答:256 tokens,财务分析:1024 tokens),使整体推理成本降低52%,同时保证91.7%的分析准确率。
边缘AI应用加速落地
得益于混合架构的效率优势,Nemotron-Nano-9B-v2在边缘设备上表现出惊人潜力。在Jetson AGX Orin平台上,INT4量化后的模型可实现30 tokens/秒的生成速度,足以支持制造业的实时质量检测。某汽车工厂部署案例显示,该模型在边缘端处理图像识别结果的自然语言报告生成时,延迟控制在1.2秒内,较云端方案节省80%带宽成本。
总结与建议
NVIDIA Nemotron-Nano-9B-v2通过架构创新打破了"参数规模决定一切"的行业迷思,其成功印证了企业AI正从"追求SOTA"转向"实用主义"——在保证90%核心能力的前提下,实现部署成本降低70%、推理速度提升6倍,这正是当前大多数企业最迫切的需求。
对于企业决策者,现在是评估混合架构模型的最佳时机:制造业可优先测试生产线异常检测与报告生成场景;金融机构建议聚焦智能投研与客服机器人应用;开发者应关注动态预算控制API与量化部署工具链。随着vLLM、TRT-LLM等推理引擎对混合架构支持的完善,这款模型的部署成本有望进一步降低,为企业提供一条兼顾性能、成本与合规性的务实路径。
企业可通过以下命令快速部署体验:
git clone https://gitcode.com/hf_mirrors/unsloth/NVIDIA-Nemotron-Nano-9B-v2-GGUF
cd NVIDIA-Nemotron-Nano-9B-v2-GGUF
vllm serve . --trust-remote-code --mamba_ssm_cache_dtype float32
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







