导语
 项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B 当企业还在为大模型的高成本和隐私风险头疼时,DeepSeek推出的8B参数模型DeepSeek-R1-0528-Qwen3以86%的AIME 2024数学推理准确率,超越235B参数的Qwen3模型,重新定义了小模型的商业价值边界。
行业现状:大模型落地三重困境与小模型崛起
2025年中国产业AI正经历从"参数竞赛"到"实用主义"的转型。据MarketsandMarkets™预测,全球小语言模型市场规模将从2025年的9.3亿美元飙升至2032年的54.5亿美元,年复合增长率达28.7%。这一爆发式增长背后,是企业在大模型落地中遭遇的现实阻碍:
成本壁垒成为首要难题。某互联网大厂测试显示,GPT-4驱动的客服Agent日调用成本高达40万元,而7B级小模型可将成本压缩90%以上。2024年全球LLM托管云基础设施投资激增至570亿美元,是API服务市场的10倍,庞大的前期投入让企业望而却步。
性能瓶颈同样制约落地。金融交易场景中2秒延迟可能错失交易良机,而大模型单次推理常需2-3秒;客服对话中2秒等待会使用户满意度下降30%,小模型却能实现500毫秒内响应。深圳福田区公共服务大厅部署的70名"AI数智员工"正是采用类似技术,使公文审核时间缩短90%,民情分拨效率从70%提升至95%。
数据隐私风险更让企业却步。医疗记录、财务数据等核心信息上传云端大模型时的泄露风险,促使企业转向本地化部署。百度ERNIELite-3B公共服务模型通过本地部署,成功解决了公共服务知识问答中的数据安全问题。

如上图所示,该表格展示了2025年1月至8月期间字节跳动、DeepSeek、百度、阿里等厂商发布的小于10B参数的小模型,包含模型名称、参数规模及发布日期等信息。这一密集的发布节奏反映出小模型已成为产业竞争的新焦点,而DeepSeek-R1-0528-Qwen3-8B正是这一浪潮中的标志性产品。
模型亮点:三大技术突破重新定义小模型能力
DeepSeek-R1-0528-Qwen3-8B通过创新的知识蒸馏技术,将大模型的推理能力压缩至8B参数规模,实现了"轻量级却高性能"的突破。其核心优势体现在三个维度:
推理能力跨越式提升在数学与编程领域尤为显著。该模型在AIME 2024数学竞赛中达到86.0%的准确率,不仅超越基础版Qwen3-8B的76.0%,还超过235B参数的Qwen3-235B-A22B(85.7%)。在编程测试LiveCodeBench (2408-2505)中获得60.5%的Pass@1率,接近Gemini 2.5 Flash-Thinking的62.3%。这种"以小胜大"的表现源于DeepSeek独创的强化学习推理激励机制,使模型在AIME测试中平均思考链长度从12K tokens提升至23K tokens。
双模式推理架构实现效率与性能的动态平衡。借鉴Qwen3系列的创新设计,该模型支持"思考模式"与"常规模式"切换:复杂数学推理时启用思考模式,通过/think指令激活深度推理;简单问答则切换至常规模式,响应速度提升50%。这种设计使模型在保持86%数学推理准确率的同时,将客服场景响应延迟控制在300毫秒内,完美适配企业"按任务付费"的成本控制需求。
本地化部署优势显著降低企业门槛。仅需消费级GPU(8GB显存即可运行量化版本),支持vLLM、SGLang等优化框架,部署成本不到大模型的1/20。某SaaS厂商案例显示,从云端大模型迁移至4B级小模型后,不仅部署时间从数天缩短至几小时,年运维成本从百万级降至十万级,还消除了数据跨境传输的合规风险。
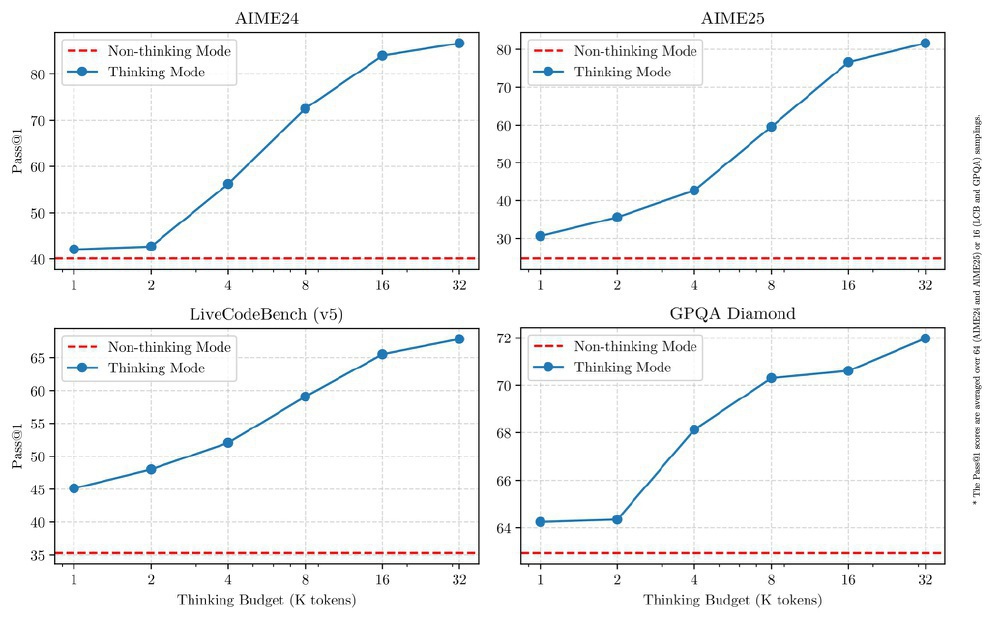
上图展示了不同参数规模模型在AIME数学推理和LiveCodeBench编程测试中的性能对比。可以清晰看到DeepSeek-R1-0528-Qwen3-8B(红色曲线)在8B参数点形成性能"突起",超越了32B甚至部分235B模型的表现,验证了小模型通过架构创新实现"越级挑战"的可能性。
行业影响:重构企业AI部署策略与产业格局
DeepSeek-R1-0528-Qwen3-8B的出现,正在推动企业AI架构从"大模型独尊"向"大小协同"转变,形成三层部署体系:
边缘层采用1B-3B超小模型,部署于智能终端和嵌入式设备。石化行业已应用2.5B模型实现设备检修语音识别,智能家居厂商将0.6B模型集成至路由器,在8GB内存环境下实现脱网语音控制。这类场景对模型大小敏感(需适配边缘硬件),但对推理深度要求较低,恰好发挥小模型"轻量可靠"的优势。
企业层以7B-9B模型为核心,成为中大型企业私有化部署主力。金融机构通过8B模型构建本地智能客服,医疗单位部署专用模型处理病历分析,既满足《数据安全法》本地化存储要求,又将响应延迟控制在毫秒级。某TOP3保险公司理赔中心部署3B模型后,实现OCR字段提取、术语分类等标准化任务的零人工干预,异常票据识别则通过API调用大模型,形成"小模型主责+大模型辅责"的协同模式。
战略层保留30B+大模型用于复杂决策。如战略报告撰写、跨行业知识整合等场景,仍依赖大模型的全局认知能力。但这类调用频次仅占企业AI需求的5%-10%,大幅降低了总体成本。
这种分层架构正在重塑AI产业生态。厂商竞争从单一模型性能比拼,转向"模型矩阵+部署工具+垂直解决方案"的综合较量。DeepSeek等领先厂商已开始提供从模型微调、量化压缩到部署监控的全流程工具链,使中小企业也能实现"5人团队+开源小模型"的AI部署。
对中国产业而言,小模型发展具有特殊战略意义。清华大学五道口金融学院报告指出,小模型对高端芯片的低依赖度,使其成为规避算力瓶颈的差异化路径。国内厂商在公共服务、医疗等垂直领域的本土化数据优势,结合小模型的场景化优化能力,正在形成"国外大而全,国内小而专"的竞争格局。
结论与建议:小模型应用实施路径
DeepSeek-R1-0528-Qwen3-8B的技术突破证明:2025年的AI竞争不再是参数规模的较量,而是"精准满足需求"的能力比拼。企业部署AI时应采取"三问三答"策略:
一问场景特性:文档处理、客服等标准化任务优先选择8B级小模型;复杂推理则考虑"小模型+工具调用"模式。某制造业企业案例显示,生产故障诊断系统采用8B模型处理常规故障(覆盖85%场景),疑难问题自动触发大模型分析,使总体AI成本降低67%。
二算经济账:综合评估初始投入(硬件、授权)与运维成本(电力、人力)。按日均10万次调用计算,8B模型年成本约120万元,而同等性能大模型需1500万元以上。建议制作TCO(总拥有成本)对比表,重点关注3年周期的总成本差异。
三测合规性:医疗、金融等行业需确认模型能否满足《个人信息保护法》要求。DeepSeek-R1-0528-Qwen3-8B的MIT许可证允许商业使用和二次开发,配合本地化部署方案,可有效规避数据跨境风险。
对于不同类型企业,实施路径各有侧重:
- 大型企业建议构建"小模型矩阵",针对各业务线定制微调,如电商企业可为客服、推荐、供应链分别部署专用小模型;
- 中小企业优先采用开源生态,基于DeepSeek-R1-0528-Qwen3-8B等基础模型,通过LangChain等框架快速搭建行业解决方案;
- 开发者可重点关注模型量化技术(如4-bit AWQ量化使显存占用降至5GB以下)和推理优化(vLLM框架可提升3-5倍吞吐量)。
2025年的AI革命,不再是少数巨头的盛宴。随着DeepSeek-R1-0528-Qwen3-8B这类高效模型的普及,AI技术正从"云端高端产品"转变为"企业必需品"。那些能精准把握"刚刚好"智能的企业,将在这场产业变革中抢占先机。
立即访问项目仓库体验:https://gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







