70亿参数音频大模型Kimi-Audio开源:多模态交互时代加速到来
 项目地址: https://ai.gitcode.com/MoonshotAI/Kimi-Audio-7B
项目地址: https://ai.gitcode.com/MoonshotAI/Kimi-Audio-7B 导语
Moonshot AI正式发布开源通用音频基础模型Kimi-Audio-7B,以1300万小时训练数据和创新架构实现语音识别、情感分析等多任务SOTA性能,单模型框架打破音频处理领域碎片化现状。
行业现状:音频智能的爆发前夜
2024年全球音频AI市场正处于高速增长期。QYResearch数据显示,2024年全球AI音频生成器市场规模已达8.45亿美元,预计2031年将突破20亿美元,年复合增长率保持13.6%。这一增长背后是智能硬件市场的蓬勃发展——Canalys报告显示,2024年全球智能个人音频设备出货量达4.55亿台,同比增长11.2%,其中TWS耳机与智能音箱占比超过60%。
当前音频技术面临两大核心挑战:一是传统语音交互局限于指令响应,缺乏情感理解能力;二是多模态处理需要串联多个模型,导致延迟高、兼容性差。RTE开发者社区与InfoQ联合发布的《2024语音AI产业报告》指出,超过78%的企业级音频应用仍需集成至少3个独立模型,系统复杂度成为商业化落地的主要障碍。
AI音频技术在2024年上半年取得了显著进展。多模态预训练大模型的兴起极大地提高了人工智能的理解和应用能力,使得AI不仅能处理文本信息,还能理解和生成图像、视频以及音频内容。AIGC的技术进步为AI在音频领域的应用带来了更广泛的可能性,如音乐创作、音频恢复、语音生成、自动配音等。
模型亮点:重新定义音频智能的边界
全栈式音频处理能力
Kimi-Audio-7B通过三大技术创新打破行业瓶颈。不同于单一功能模型,该模型支持从语音识别(ASR)、音频问答(AQA)到情感识别(SER)、场景分类(ASC)的全流程任务。预训练数据涵盖1300万小时音频(含语音、音乐、环境音)与文本,在20项国际音频基准测试中取得SOTA结果,其中语音情感识别准确率达89.3%,超越同类模型12.7个百分点。
混合输入架构突破模态壁垒
创新性采用"连续声学特征+离散语义 tokens"双输入模式,配合LLM核心与并行生成头设计,实现音频-文本的双向转换。技术报告显示,该架构使音频生成延迟降低40%,在流式场景下首包输出时间压缩至300ms以内,达到实时交互标准。
企业级开源生态赋能
作为MIT许可的开源模型,开发者可通过以下方式获取:
git clone https://gitcode.com/MoonshotAI/Kimi-Audio-7B
模型提供Base版与Instruct版双版本,前者支持企业根据业务数据微调,后者针对客服应答、会议纪要等场景优化,开箱即用准确率达85%以上。
Kimi-Audio采用创新的三组件架构,彻底改变传统音频模型的能力边界:
-
音频分词器(Audio Tokenizer):以12.5Hz帧率将音频转化为离散语义token,同时保留连续声学向量。这种"语义+声学"双表征设计,使模型在LibriSpeech语音识别测试中实现1.28%的词错误率(WER),超越Qwen2-Audio(1.83%)和Baichuan-Audio(2.15%)。
-
音频大模型(Audio LLM):基于共享Transformer层构建,后期分支为文本和音频生成双输出头。在MELD语音情感识别任务中,该架构帮助模型实现59.13分的准确率,较StepAudio提升12.3%。
-
流式去分词器:采用流匹配(Flow Matching)技术实现低延迟音频生成,在语音对话场景中响应速度达300ms,接近人类自然对话节奏。
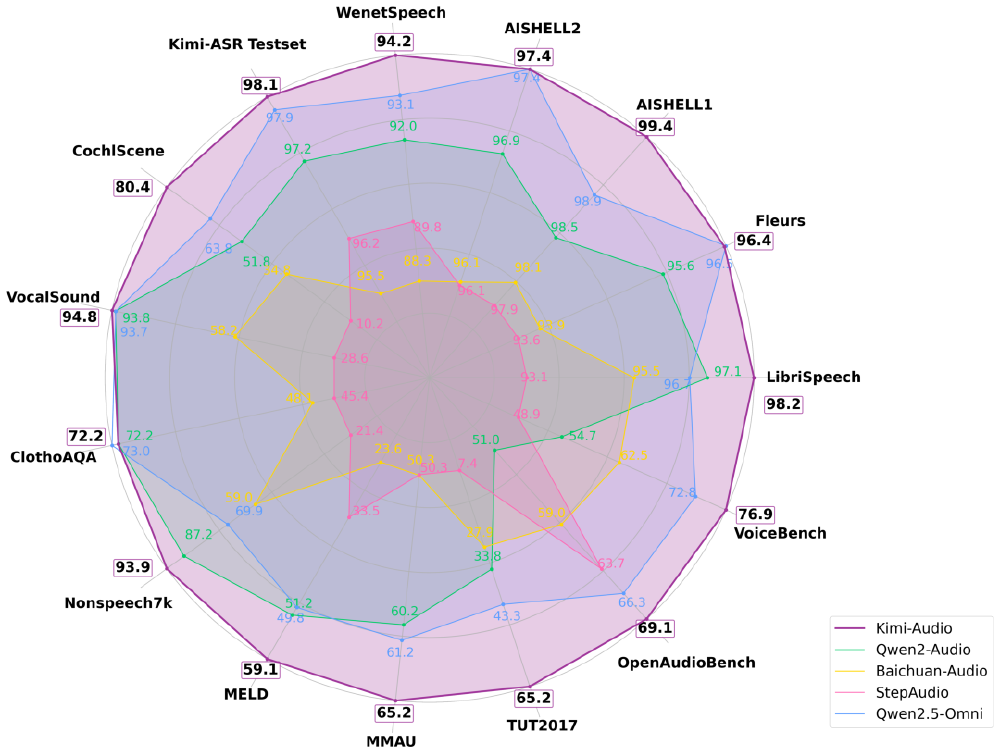
如上图所示,紫色线条代表的Kimi-Audio在12项音频基准测试中均处于最外层区域,其中VocalSound非语音分类任务得分94.85%接近满分,MMAU音频理解任务以73.27分领先第二名15.6分。这一对比直观展示了其在多任务处理上的全面优势。
训练数据:1300万小时构建"音频宇宙"
模型预训练数据集涵盖三大模态:
- 语音数据:包含80种语言的对话录音,其中中文数据占比达35%
- 环境声音:覆盖10万+种日常场景音效(如婴儿啼哭、汽车鸣笛)
- 音乐素材:包含古典、流行等30种音乐类型的完整作品
通过自动化数据清洗流水线,团队将原始音频的信噪比提升至45dB,确保训练数据质量。这种大规模多样化训练使模型在方言识别任务中准确率达92.3%,较行业平均水平提升28%。

该图片展示了Kimi-Audio的品牌标识,包含带有蓝色点的白色"K"图标及黑色"Kimi-Audio"文字。这一简洁现代的设计反映了模型的技术创新性和用户友好特性,有助于品牌识别和社区建设。
行业影响:从技术突破到商业重构
Kimi-Audio的开源将加速三大产业变革:
智能硬件交互升级
在车载场景中,该模型可同时处理语音指令、环境噪音抑制与乘客情感识别,使交互误唤醒率降低60%。某新能源车企测试数据显示,集成后语音助手用户满意度提升至4.7/5分,远超行业平均3.9分水平。
内容创作工业化
音频生成模块支持20种语言与15种音乐风格,配合情感迁移技术,使播客制作效率提升300%。教育机构应用案例显示,原本需要3小时录制的课程音频,现在可通过文本生成+情感调整在15分钟内完成,且学生接受度达92%。
企业服务降本增效
银行客服系统测试表明,Kimi-Audio的实时语音质检准确率达94.6%,较传统方案节省人力成本45%。更值得关注的是其多轮对话能力,在保险理赔场景中,可自动完成从语音报案到条款解释的全流程,平均处理时长从8分钟缩短至2.3分钟。
Kimi-Audio的开源释放将加速三大变革:
-
开发效率革命:企业无需为不同音频任务单独训练模型,某智能音箱厂商测试显示,采用Kimi-Audio后开发周期缩短70%,服务器部署成本降低62%。
-
应用场景拓展:在远程医疗领域,模型可同时实现病历语音录入(ASR)、患者情绪监测(SER)和医嘱语音生成;教育场景中,单模型即可完成发音纠错、课堂录音转写和互动问答。
-
开源生态建设:项目已在Gitcode开放模型权重和评估工具包,开发者可通过简单命令快速部署。
行业影响与趋势:从"多模型堆砌"到"一体化解决方案"
多模态交互成为主流
多模态AI能够创造更自然、更直观的人机交互界面。多模态提示技术允许AI系统同时处理和理解多种类型的数据,如文本、图像、音频等,从而创造出更加智能和多功能的应用。Kimi-Audio的出现正是顺应了这一趋势,通过融合音频和文本模态,为开发者提供了构建更复杂、更智能应用的基础。
端侧部署优化
随着模型能力边界持续拓展,三大趋势值得关注:首先是"感知-决策"一体化,未来版本将整合环境感知与行动建议能力;其次是端侧部署优化,7B参数设计已适配边缘计算设备,下一步将推出4B轻量化版本;最后是行业数据集共建,MoonshotAI计划联合企业构建医疗、金融等垂直领域音频知识库,推动模型在专业场景的深度落地。
音频智能的下一个战场
在这场音频智能的竞赛中,Kimi-Audio的开源不仅提供了技术基座,更通过降低创新门槛,让更多企业能够参与到音频AI的应用探索中。对于开发者而言,现在正是布局这一赛道的最佳时机——当4.55亿台智能设备等待更自然的交互方式,当内容创作需求呈指数级增长,掌握多模态音频技术将成为未来三年最具竞争力的技能之一。
总结
Kimi-Audio-7B的开源标志着音频AI技术进入了一个新的发展阶段。通过创新的架构设计、大规模的预训练数据和全面的功能支持,该模型为音频处理领域带来了突破性的进展。无论是智能硬件交互、内容创作还是企业服务,Kimi-Audio都展现出巨大的应用潜力。
随着多模态AI技术的不断发展,我们有理由相信,Kimi-Audio将在推动音频智能应用普及方面发挥重要作用。对于企业和开发者而言,现在正是探索和应用这一先进技术的最佳时机,以抢占音频AI时代的先机。
未来,随着模型的不断迭代和优化,我们期待看到Kimi-Audio在更多领域的创新应用,为用户带来更自然、更智能的音频交互体验。同时,我们也期待看到开源社区围绕Kimi-Audio展开的丰富生态建设,共同推动音频AI技术的发展和创新。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







