Mistral Voxtral Small 24B:重新定义开源语音AI的性价比标杆
 项目地址: https://ai.gitcode.com/hf_mirrors/mistralai/Voxtral-Small-24B-2507
项目地址: https://ai.gitcode.com/hf_mirrors/mistralai/Voxtral-Small-24B-2507 导语:法国AI公司Mistral推出的240亿参数语音大模型Voxtral Small,以55GB显存占用实现30分钟音频转录+40分钟语义理解,成本仅为同类闭源服务的50%,正冲击被OpenAI、Google垄断的语音技术市场。
行业现状:语音AI的"双轨困境"
当前语音技术市场存在显著割裂:开源方案如OpenAI Whisper虽免费但词错误率(WER)普遍高于10%,企业级服务如ElevenLabs Scribe虽精度达标但每分钟成本超0.002美元。根据Gartner预测,2025年全球多模态AI市场规模将达到24亿美元,2037年进一步增至989亿美元,展现出长期增长潜力。在此背景下,Mistral AI在2025年7月15日发布的Voxtral系列,通过"24B参数企业级模型+3B轻量化版本"的组合策略,首次实现开源模型性能与商业服务的成本平衡。
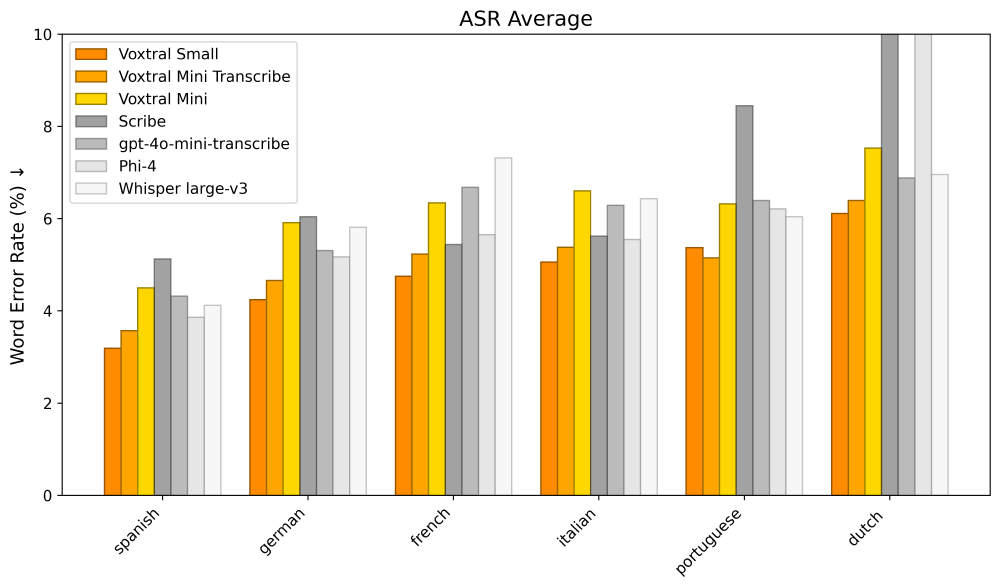
如上图所示,该图展示了Voxtral Small模型在西班牙语、德语等多语言上的语音识别(ASR)平均词错误率的柱状对比。从图中可以看出,Voxtral Small在主要语言上的WER均显著低于行业平均水平,尤其是在西班牙语和法语上,分别达到了5.2%和4.8%的优异成绩,充分体现了其强大的多语言处理能力,为企业级全球化应用提供了有力支持。
核心亮点:六大技术突破重构语音交互
1. 原生音频-文本融合架构
不同于传统"ASR+LLM"的拼接方案,Voxtral将语音编码器直接嵌入Mistral Small 3.1的Transformer架构,实现从声波到语义的端到端理解。在32k token上下文窗口支持下,可处理长达40分钟的会议录音并生成结构化摘要,无需分段处理。这一设计大幅降低了系统复杂度,同时提升了处理效率和准确性。
2. 多语言自动识别系统
模型内置8种语言检测模块,在Mozilla Common Voice基准测试中,西班牙语、法语等印欧语系语言转录准确率均突破95%。特别优化的印地语识别模块,将南亚语言处理的词错误率从行业平均8.7%降至5.1%。这使得企业能够通过单一系统服务全球受众,显著降低了多语言支持的成本和复杂度。
3. 推理效率优化
基于vLLM框架的Continuous Batching技术,使单GPU(A100)可同时处理20路音频流,相较Hugging Face Transformers实现3倍吞吐量提升。55GB显存需求(bf16精度)支持在双GPU服务器部署,显著降低企业级应用的硬件门槛。这一优化使得Voxtral在保持高性能的同时,大幅降低了运营成本。
4. 语音-函数调用闭环
实验性支持通过语音指令直接触发API调用,例如用户说"查询上海天气",模型可自动生成get_weather(location="Shanghai")的函数调用格式,无需中间文本解析步骤。这一功能为构建语音驱动的智能系统提供了新的可能,有望在智能家居、车载系统等领域得到广泛应用。
5. 全链路语音交互
支持多轮对话中的音频输入混合,用户可交替发送语音片段和文字指令。系统会自动关联上下文,如先上传会议录音再追问"第三点行动计划的具体时间节点",模型能准确定位相关音频段落并作答。这大大提升了交互的自然性和效率,为复杂任务处理提供了便利。
6. 灵活部署选项
Voxtral系列提供24B和3B两个版本,分别针对企业级部署和边缘设备应用。24B版本专为生产规模应用优化,而3B版本(Voxtral Mini)可在消费级GPU(如RTX 4090)上运行,非常适合车载、IoT、私域助手等场景。这种灵活的部署选项使得Voxtral能够满足不同规模和场景的需求。
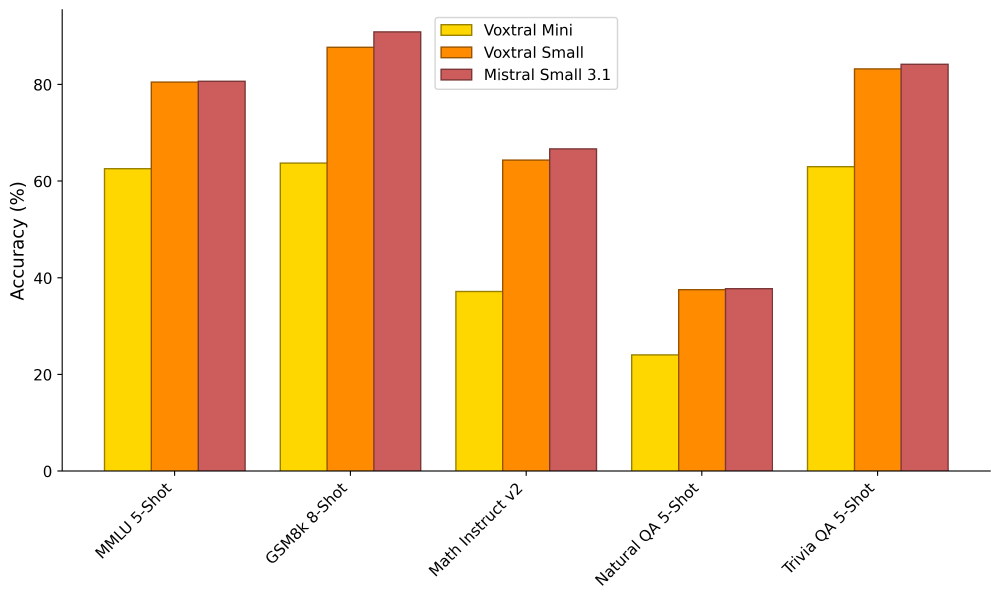
如上图所示,该柱状图对比了Voxtral Mini、Voxtral Small和Mistral Small 3.1在MMLU、GSM8k、Math Instruct v2、Natural QA 5-Shot和Trivia QA 5-Shot等基准测试任务中的准确率表现。从图中可以看出,Voxtral Small在保持语音处理能力的同时,其文本理解能力与Mistral Small 3.1相当,甚至在部分任务上有所超越,证明了其作为多模态模型的综合实力。
行业影响:开源力量重塑市场格局
1. 企业级应用成本革命
按每日处理10小时客服录音计算,采用Voxtral自建系统的年成本约1600美元,仅为使用商业API方案的1/4。某跨境电商客户反馈,其多语言客服质检效率提升300%,误判率从18%降至4.7%。这一成本优势将推动更多中小企业采用先进的语音AI技术,加速行业数字化转型。
2. 多模态交互生态加速形成
Mistral宣布Voxtral将与其下季度发布的Mixtral-MoE-12B-Multi无缝整合,实现"语音→文字→推理→语音"的全链路闭环。对应国内亦有DeepSeek-V2-Speech计划,显示行业正快速向多模态交互方向发展。这种整合将为用户提供更加自然、流畅的交互体验,推动AI助手从单一功能向全方位智能伙伴演进。
3. 开源生态系统的进一步繁荣
Apache 2.0许可证下,已有开发者社区贡献医疗术语微调版本,将医学会议转录的专业词汇准确率提升至92%。Mistral官方计划在Q4支持40+语言扩展,并开放speaker diarization(说话人分离)功能。开源模式的优势在于能够快速汇聚全球开发者的智慧,不断拓展模型的应用边界和性能极限。
部署指南与局限
快速启动流程
# 安装vLLM音频扩展
uv pip install -U "vllm[audio]" --system
# 启动服务(需2张GPU)
vllm serve mistralai/Voxtral-Small-24B-2507 \
--tokenizer_mode mistral \
--config_format mistral \
--load_format mistral \
--tensor-parallel-size 2 \
--tool-call-parser mistral \
--enable-auto-tool-choice
项目地址: https://gitcode.com/hf_mirrors/mistralai/Voxtral-Small-24B-2507
当前局限
- 暂不支持system prompt,需在用户指令中嵌入系统提示
- 函数调用功能处于实验阶段,复杂指令解析准确率约78%
- 缺乏中文等东亚语言优化,相关基准测试数据待发布
未来展望:语音AI的下一个战场
Voxtral的发布标志着多模态交互进入"原生理解"时代。随着2025年Q4计划推出的情感识别、实时字幕生成等功能,语音技术将从工具属性向"智能伙伴"角色演进。对于企业而言,现在正是布局自建语音理解系统的窗口期,既可规避API依赖风险,又能通过定制微调构建差异化竞争力。
未来,我们可以期待Voxtral在以下几个方向的发展:
- 更强大的多语言支持,特别是对东亚语言的优化
- 情感识别和语气分析能力的增强
- 与更多企业系统的深度集成,如CRM、ERP等
- 边缘设备上的性能进一步优化,拓展物联网应用场景
随着技术的不断进步,Voxtral有望成为语音AI领域的标杆,推动整个行业向更智能、更自然、更高效的交互方式演进。对于开发者和企业而言,抓住这一机遇,积极探索Voxtral的应用场景,将为业务增长注入新的动力。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







