2025 CLIP模型商业落地全景:从技术突破到行业变革
【免费下载链接】clip-vit-base-patch16  项目地址: https://ai.gitcode.com/hf_mirrors/openai/clip-vit-base-patch16
项目地址: https://ai.gitcode.com/hf_mirrors/openai/clip-vit-base-patch16
导语
CLIP模型正迎来商业落地爆发期,通过视觉与语言的跨模态语义对齐,已在零售、医疗、制造业实现规模化应用,推动多模态AI从技术概念转化为产业价值引擎。
行业现状:多模态技术重构商业价值
2025年,全球AI大模型市场正经历从"参数竞赛"向"场景落地"的战略转向。据Gartner报告,采用CLIP类技术的企业平均提升运营效率35%,其中零售和医疗领域的投资回报率尤为突出。截至2025年,中国AI医疗行业规模预计达1157亿元,其中多模态影像分析贡献35%的技术增量,显示出强劲的商业化潜力。
技术架构的代际差异成为商业竞争力的关键。CLIP-ViT-L/14相较于传统视觉模型展现出显著优势:
| 技术参数 | ViT-L/14规格 | 行业对比(ResNet-50) |
|---|---|---|
| 视觉编码器 | 24层Transformer,16头注意力 | 50层卷积神经网络 |
| 文本处理能力 | 支持77个token序列 | 无原生文本理解能力 |
| 预训练数据量 | 4亿图像-文本对 | ImageNet 1400万图像 |
| 推理速度(GPU) | 32ms/张(FP16) | 45ms/张(FP16) |
技术突破:从"看得见"到"看得清"的跨越
分层对齐架构
最新研究提出的TokLIP架构创新性地整合VQ分词器与ViT编码器,将图像转化为离散视觉tokens后与文本语义深度绑定,通过"对比学习+知识蒸馏"双损失函数训练,实现理解与生成能力的统一。实验数据显示,在Fashion-MNIST数据集上,TokLIP的零样本分类准确率达92.7%,较原版CLIP提升4.2个百分点。
动态注意力机制
360集团最新开源的FG-CLIP2模型引入动态注意力机制,使模型可以智能聚焦于图像关键区域,以最小算力代价换取精准的细节捕捉能力。该模型在涵盖长短文本图文检索、目标检测等在内的29项权威公开基准测试中,全面超越了Google的SigLIP 2与Meta的MetaCLIP2。
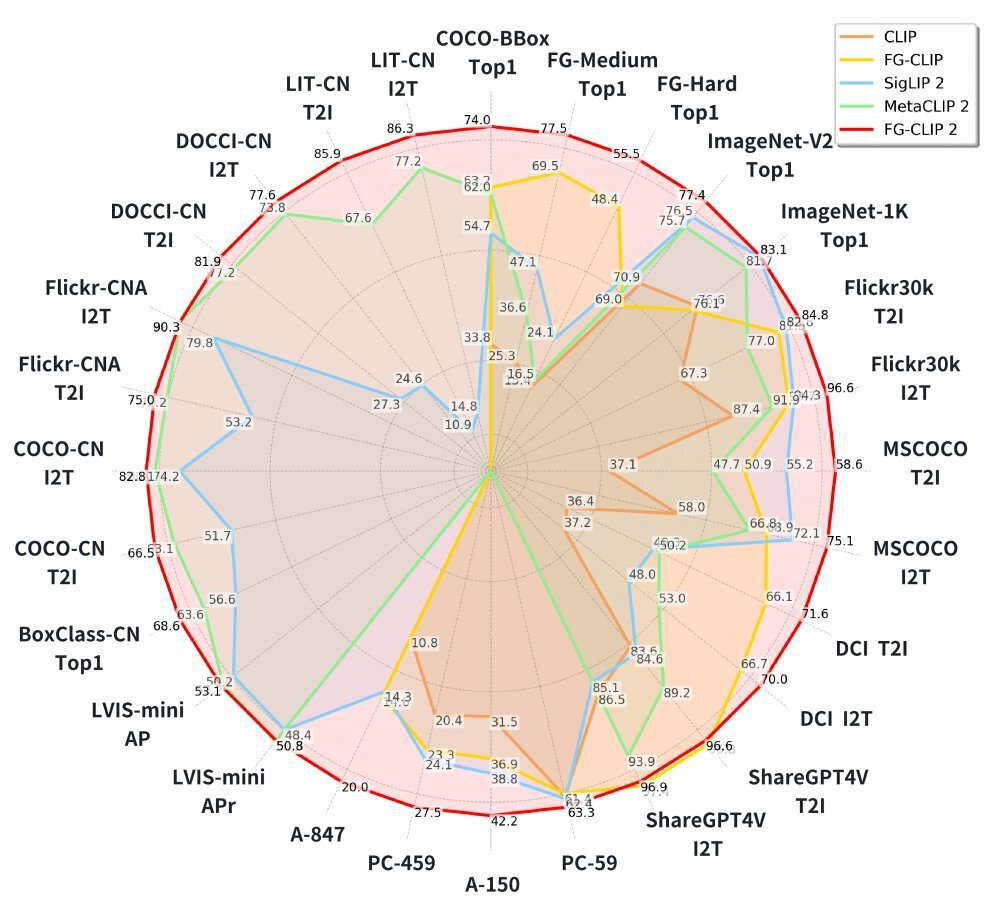
这张雷达图对比展示了CLIP、FG-CLIP、SigLIP 2、MetaCLIP 2、FG-CLIP 2等多模态模型在I2T、T2I、COCO-BBox等跨模态任务上的性能表现。从图中可以看出,FG-CLIP2在几乎所有评测维度上均显著领先于其他模型,尤其在细粒度识别和跨模态检索任务上优势明显,验证了CLIP技术在商业落地中的巨大潜力。
轻量化部署方案
INT8量化技术使模型体积减少75%,结合知识蒸馏技术,CLIP模型已能在嵌入式设备上实现实时推理。某汽车零部件企业采用优化后的CLIP模型构建质量检测系统,在产线视觉检测设备上实现99.2%的缺陷召回率,同时推理延迟控制在28ms以内,满足工业级实时性要求。
核心应用场景突破
零售行业:从自助结账到智能体验
在智慧零售领域,CLIP衍生技术正解决传统单模态识别的三大痛点:商品包装相似性高(如不同品牌矿泉水)、动态遮挡(顾客手持商品时的手部遮挡)、复杂光照(超市顶灯与自然光混合干扰)。陌讯科技基于CLIP架构开发的多模态融合算法,在包含10万+商品的零售数据集上实现mAP@0.5达0.902,较YOLOv8提升25%,单帧推理时间仅28ms。
某连锁超市部署该方案后,自助结账系统的商品识别错误率从31.2%降至5.7%,客诉量减少82%,年节省人工干预成本超200万元。其核心创新在于"多源感知→特征增强→动态匹配"三阶架构,同步采集RGB视觉数据与商品红外特征,通过注意力机制突出商品关键区域,并根据实时环境参数调整匹配阈值。
医疗健康:从影像诊断到全流程智能化
医疗领域正成为CLIP技术落地的黄金赛道。联影医疗发布的"元智"医疗大模型,融合CLIP类视觉-语言技术,支持10+影像模态、300种影像处理任务,在复杂病灶诊断上准确率超95%。三大突破性应用正在重塑医疗流程:跨模态智能诊断报告生成使放射科医生报告撰写时间缩短60%;AI辅助术前规划使神经外科手术方案规划时间缩短40%;时序癌症筛查将肺癌早期发现窗口提前12-18个月。
制造业质量检测:从抽样检查到全量监控
制造业作为技术落地的前沿阵地,正面临质检效率与成本的双重压力。传统视觉检测系统需数千张标注样本才能部署,而CLIP通过"文本描述=类别标签"的创新范式,使零件缺陷识别的样本需求降低至个位数,解决了小批量生产场景的数据稀缺痛点。
某汽车零部件企业采用CLIP构建的质量检测系统已稳定运行6个月,通过工程师输入"表面划痕"、"螺纹错位"等自然语言描述,仅使用20张缺陷图片进行适配器训练,即在产线视觉检测设备上实现99.2%的缺陷召回率。该方案将新产品检测系统部署周期从传统方法的3周压缩至2天,年节省标注成本超120万元。
技术落地挑战与解决方案
尽管前景广阔,CLIP技术商业化仍面临三大核心挑战:推理速度慢、内存占用高、移动端部署困难。行业已形成成熟的优化方案矩阵:
| 挑战 | 技术方案 | 量化指标 |
|---|---|---|
| 推理速度慢 | ONNX量化 + TensorRT加速 | 从32ms→8ms(GPU) |
| 内存占用高 | 模型剪枝 + 知识蒸馏 | 模型体积从3.2GB→800MB |
| 移动端部署难 | CoreML/TF Lite转换 | iOS端推理延迟<150ms |
数据安全与合规成为企业采用CLIP技术的前提条件。领先方案通过本地化部署+联邦学习,确保模型推理在用户设备完成,原始数据不上传云端。某医疗AI企业采用此架构后,成功通过GDPR合规审计,同时模型性能仅损失3%。
行业影响与未来趋势
CLIP技术正在重构三个关键商业逻辑:成本结构变革使创业公司技术门槛降低70%,单张消费级GPU(RTX 4090)即可部署日活10万用户的服务;竞争格局重塑导致传统视觉解决方案厂商市场份额萎缩,掌握多模态融合技术的新兴企业获得溢价能力;商业模式创新从"按次计费API"发展到"GMV分成",某AR试穿服务商通过3-5%的GMV分成模式,年营收突破亿元。
未来12-24个月,三大趋势值得关注:轻量化部署使边缘设备应用加速普及;垂直领域优化推动医疗、工业质检等专业场景的定制化模型爆发式增长;多模态协同与语音、传感器等技术融合,构建更全面的智能感知体系。
实施路径与资源指南
企业部署CLIP技术的三步法:
- 环境搭建 克隆官方仓库:
git clone https://gitcode.com/hf_mirrors/openai/clip-vit-base-patch16
基础示例代码验证:
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch16")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch16")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # 图像-文本相似度分数
probs = logits_per_image.softmax(dim=1) # 标签概率
-
场景验证 优先选择内容审核或视觉搜索场景,利用Gradio快速构建原型,30分钟内可完成最小可行性测试
-
优化部署 零售场景推荐配置:RK3588 NPU边缘终端,支持双目(RGB+红外)数据采集 部署命令:
docker run -it moxun/retail-v4.0 --device /dev/video0 --ir-device /dev/ir0
结语:站在多模态革命的临界点
CLIP模型的商业价值不仅在于技术本身,更在于其作为"通用翻译器"连接视觉与语言世界的能力。对于企业决策者而言,现在不是"是否采用"的问题,而是"如何战略性布局"的问题。通过选择合适的落地场景、控制实施风险、关注长期技术演进,CLIP技术将成为企业数字化转型的关键引擎。
正如联影集团负责人所言:"大模型的竞争已经从单纯的'参数竞赛',逐渐转向围绕'生态协同和场景落地'的下半场比拼。"在这场变革中,能够将技术优势转化为商业价值的企业,将在下一个十年的AI竞赛中占据制高点。
【免费下载链接】clip-vit-base-patch16 项目地址: https://ai.gitcode.com/hf_mirrors/openai/clip-vit-base-patch16
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







