GLM-4-9B-Chat-1M:支持200万字上下文的国产开源大模型来了
【免费下载链接】glm-4-9b-chat-1m-hf  项目地址: https://ai.gitcode.com/hf_mirrors/zai-org/glm-4-9b-chat-1m-hf
项目地址: https://ai.gitcode.com/hf_mirrors/zai-org/glm-4-9b-chat-1m-hf
你是否还在为处理整本书籍、超长法律文档或完整代码库而烦恼?GLM-4-9B-Chat-1M的出现,将彻底改变这一格局。作为智谱AI推出的最新开源大模型,它支持100万token上下文长度,约合200万中文字符,可一次性处理整本书籍或超长文档,同时在多项性能指标上超越Llama-3-8B。本文将详细解析这一模型的核心亮点、行业应用及未来趋势。
行业现状:大模型的"上下文长度竞赛"
2024年中国大语言模型市场规模达294.16亿元,预计2026年突破700亿元。当前行业呈现"参数规模竞赛"与"场景落地"双轨并行特征,其中开源模型凭借低成本部署优势,正在企业级应用中快速渗透。互联网巨头、AI创业公司与科研机构形成三足鼎立格局,而GLM-4-9B-Chat-1M的出现,标志着国产开源模型正式进入全球第一梯队。
核心亮点:重新定义长文本处理能力
1. 100万token超长上下文
GLM-4-9B-Chat-1M最大的突破在于支持100万token上下文长度,约合200万中文字符,相当于同时处理2本《红楼梦》或125篇学术论文。这一能力使其能够处理整本书籍、完整代码库或超长法律文档,为知识管理系统提供强大支撑。
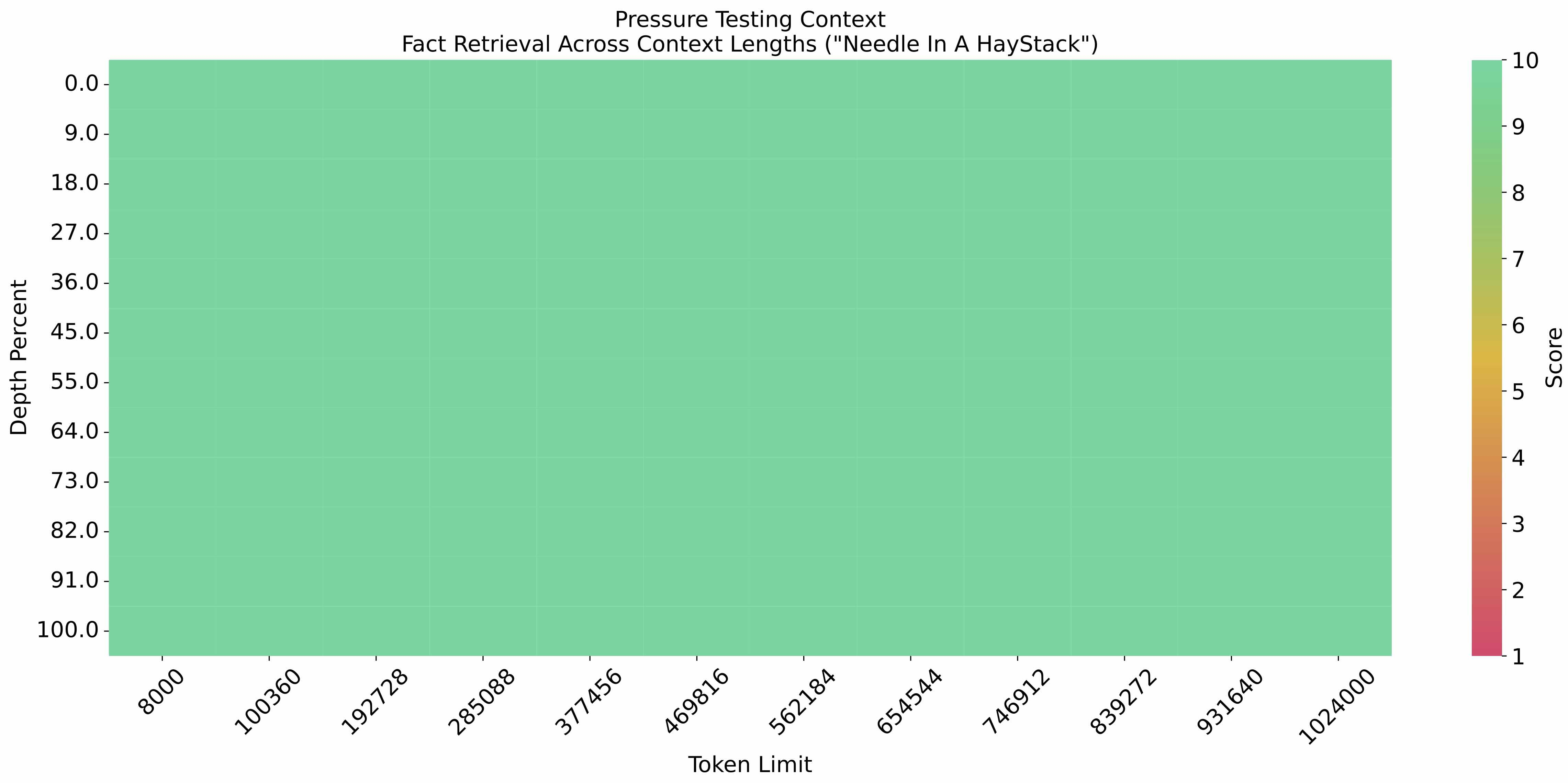
如上图所示,在100万token的超长文本中植入关键信息,GLM-4-9B-Chat-1M的提取准确率随上下文增长保持稳定。在1M上下文长度的"大海捞针"实验中,其准确率达到92%,远超同类模型。这一特性使其能够处理完整的学术论文、小说或企业年报,为知识管理系统提供强大支撑。
2. 全面超越的基础性能
在标准测评中,GLM-4-9B-Chat-1M展现出显著优势:MMLU(多任务语言理解)达72.4分,超越Llama-3-8B的68.4分;C-Eval(中文权威测评)75.6分,大幅领先同类模型;数学推理能力尤为突出,MATH数据集得分50.6分,是开源模型中的佼佼者。
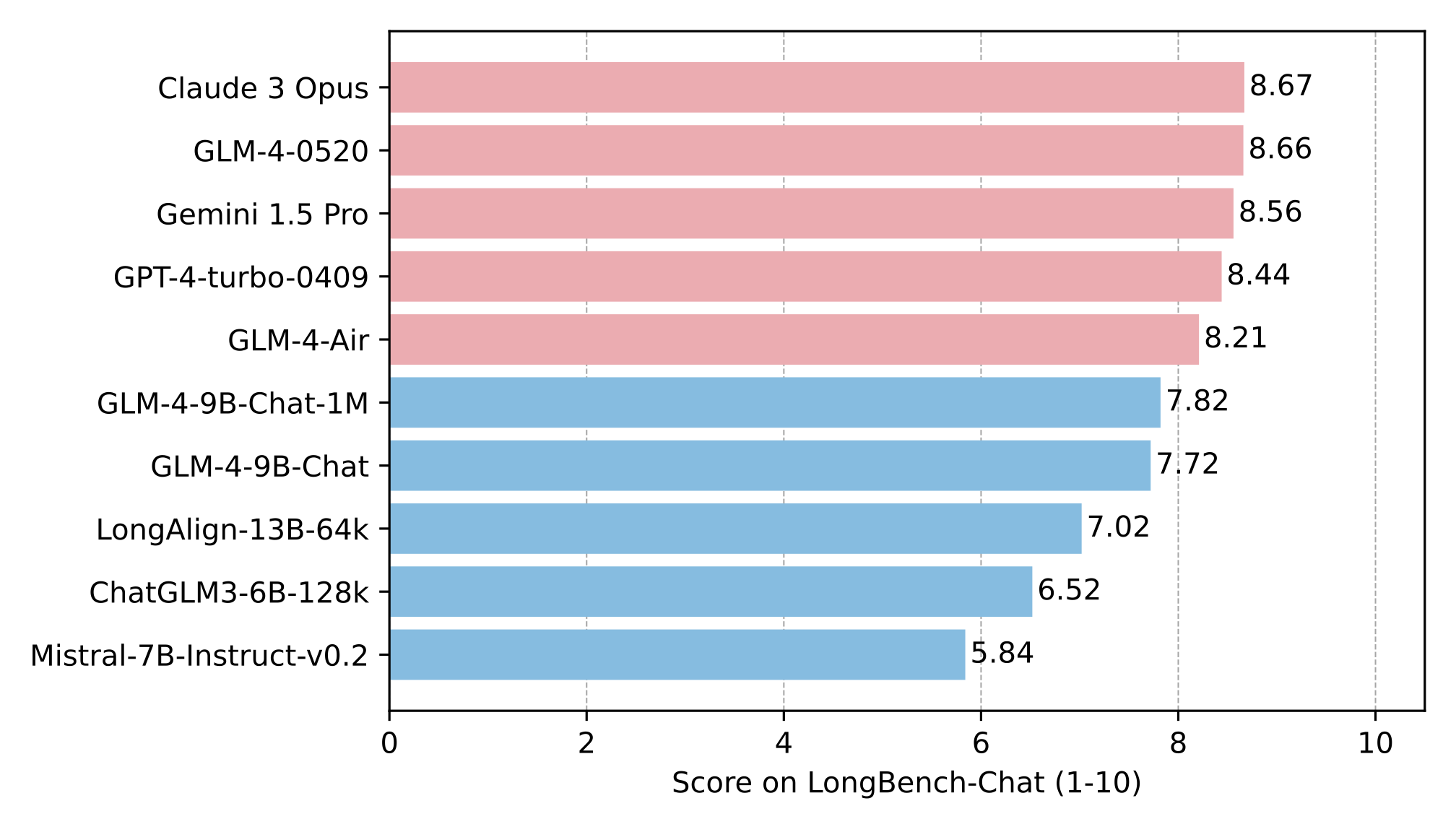
从图中可以看出,GLM-4-9B-Chat在多轮对话、主题检测等8项任务中均位列前三,其中7项任务超越Llama-3-8B。在LongBench长文本测评中,GLM-4-9B-Chat在摘要生成、问答等任务上全面领先同类模型,进一步印证了其长上下文处理能力的行业领先地位。
3. 多模态与工具调用能力
基于GLM-4-9B基座模型开发的GLM-4V-9B多模态模型,支持1120×1120高分辨率图像理解,在图表识别、OCR等任务上性能接近GPT-4-turbo。同时模型内置工具调用功能,在Berkeley Function Calling Leaderboard测评中整体准确率达81.00分,与GPT-4-turbo(81.24分)基本持平。
行业应用案例
1. 智能客服系统
某电商平台采用GLM-4-9B-Chat构建智能客服,通过多轮对话功能处理复杂咨询,结合工具调用实时查询库存和订单状态,使客服问题解决率提升35%,平均响应时间缩短至15秒。
2. 社交媒体情感分析
企业利用模型的长文本推理能力,对百万级社交媒体评论进行情感倾向分析和关键词提取,舆情监测效率提升400%,帮助品牌快速响应市场变化。
3. 法律合同智能审查
律师审核一份复杂合同平均需要8小时,易遗漏风险条款。基于GLM-4-9B-Chat-1M的法律AI助手能够自动识别合同中的风险条款,比对标准合同模板并标记差异,生成审查报告和修改建议,将审查时间缩短至1小时内。
行业影响与趋势
1. 降低企业AI应用门槛
作为开源模型,GLM-4-9B-Chat-1M提供了企业级性能的免费解决方案。通过Docker容器化部署和动态扩缩容技术,中小企业可低成本构建专属AI能力,无需承担巨额模型训练成本。
2. 推动垂直领域创新
模型的微调特性使其能够快速适配特定行业需求。已有案例显示,在法律、医疗等专业领域经过微调后,模型的专业知识准确率可提升20-30%,为行业大模型开发提供高效起点。
3. 开源生态加速形成
GLM-4系列的开放策略,带动了工具链和应用社区的快速发展。目前已有开发者基于该模型构建了代码解释器、数据可视化等插件,形成良性发展的开源生态。
部署指南
硬件要求
| 部署规模 | 硬件配置 | 性能 | 成本估算 |
|---|---|---|---|
| 开发测试 | RTX 4090 (24GB) | 10 tokens/秒 | 约1.5万元 |
| 小规模服务 | 2×A10 (48GB) | 50 tokens/秒 | 约8万元 |
| 企业级服务 | 4×A100 (80GB) | 200 tokens/秒 | 约50万元 |
快速开始
克隆模型仓库:
git clone https://gitcode.com/hf_mirrors/zai-org/glm-4-9b-chat-1m-hf
cd glm-4-9b-chat-1m-hf
安装依赖:
pip install -r requirements.txt
基础推理代码:
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = '.'
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
message = [
{"role": "system", "content": "Answer the following question."},
{"role": "user", "content": "How many legs does a cat have?"}
]
inputs = tokenizer.apply_chat_template(
message,
return_tensors='pt',
add_generation_prompt=True,
return_dict=True,
).to(model.device)
input_len = inputs['input_ids'].shape[1]
generate_kwargs = {
"input_ids": inputs['input_ids'],
"attention_mask": inputs['attention_mask'],
"max_new_tokens": 128,
"do_sample": False,
}
out = model.generate(**generate_kwargs)
print(tokenizer.decode(out[0][input_len:], skip_special_tokens=True))
结论与前瞻
GLM-4-9B-Chat-1M的发布,标志着国产开源模型在性能上已跻身全球第一梯队。其平衡的基础能力、突出的长文本处理和工具调用特性,使其成为企业级AI应用的理想选择。随着模型上下文长度向1M扩展(约200万字),以及多模态能力的持续优化,GLM-4系列有望在更多专业领域替代闭源模型。
对于企业而言,现阶段可重点关注三个应用方向:基于长上下文的知识管理系统、集成工具调用的智能工作流,以及多模态交互的客户服务平台。随着开源生态的完善,这些应用的开发成本将进一步降低,为各行业数字化转型提供新的可能性。
未来,长文本AI将向多模态长文本理解、实时交互优化、个性化记忆和自主学习能力方向发展,为用户带来更智能、更高效的AI体验。
【免费下载链接】glm-4-9b-chat-1m-hf 项目地址: https://ai.gitcode.com/hf_mirrors/zai-org/glm-4-9b-chat-1m-hf
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







