Kimi Linear开源:混合线性注意力改写大模型效率规则,1M token解码提速6倍
 项目地址: https://ai.gitcode.com/MoonshotAI/Kimi-Linear-48B-A3B-Instruct
项目地址: https://ai.gitcode.com/MoonshotAI/Kimi-Linear-48B-A3B-Instruct 导语
月之暗面(Moonshot AI)正式开源Kimi Linear混合线性注意力架构,首次实现线性注意力在短、中、长全场景下超越传统全注意力模型,100万token上下文解码速度提升6倍,KV缓存需求减少75%,为大模型效率革命树立新标准。
行业现状:长文本处理的效率困局
当前大语言模型正面临"上下文长度-计算效率"的核心矛盾。传统Transformer的全注意力机制(Full Attention)采用O(n²)复杂度计算,当处理10万+token的长文档时,不仅需要庞大的KV缓存(Key-Value Cache)存储历史信息,还会导致解码速度断崖式下降。据行业测试数据,主流70B模型在处理100万token时,解码速度会降至短文本场景的1/10以下,且内存占用超过40GB,严重制约了法律文档分析、代码库理解、医疗记录处理等专业领域的应用落地。
线性注意力(Linear Attention)虽通过O(n)复杂度计算缓解了这一问题,但过去因表达能力不足,在短文本任务中性能始终落后全注意力10%-15%。2024年以来,Gated DeltaNet、Mamba等架构通过门控机制缩小了差距,但在长上下文检索精度和强化学习收敛速度上仍存短板。Kimi Linear的出现,标志着混合线性注意力架构首次实现了"鱼与熊掌兼得"的突破。
核心亮点:Kimi Linear的三大技术突破
1. Kimi Delta Attention:细粒度门控的效率革命
Kimi Linear的核心创新在于Kimi Delta Attention(KDA)机制,它在Gated DeltaNet基础上引入通道级(Channel-wise)遗忘门控,每个特征维度独立调控记忆衰减率,较传统头部级(Head-wise)门控精度提升3倍。通过Diagonal-Plus-Low-Rank(DPLR)矩阵优化,KDA将算子计算效率提升100%,同时避免了GLA(Gated Linear Attention)在半精度计算中的数值稳定性问题。

如上图所示,Kimi Linear技术报告封面清晰展示了其核心定位:"Expressive, Efficient Attention Architecture"(高表达性、高效率注意力架构)。这一设计理念通过精细化门控机制与混合架构实现了双重突破,为解决长文本处理效率问题提供了全新思路。
2. 3:1混合架构:性能与效率的黄金平衡点
不同于逐头部混合注意力的复杂设计,Kimi Linear采用逐层交替的混合策略:每三个KDA层后面插入一个MLA层,形成周期性的全局信息校准。这种设计使得模型既能保持线性注意力在高吞吐量和低内存占用方面的优势,又能通过全注意力层维持强大的全局依赖建模能力。
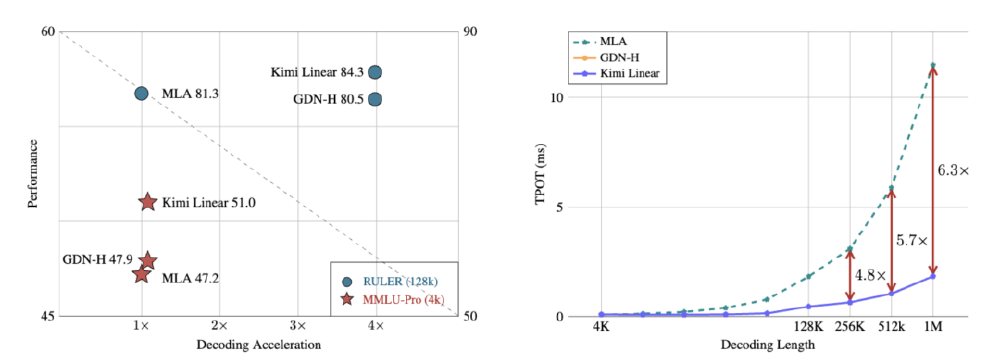
如上图所示,Kimi Linear在MMLU-Pro(4k短上下文)和RULER(128k长上下文)任务中均实现性能-速度双赢。特别是在100万token场景下,TPOT(每输出token耗时)仅为全注意力模型的1/6,充分验证了混合架构的优越性。
3. 工程化突破:即插即用的高效部署
开源KDA内核已集成至FLA(Flash Linear Attention)框架,支持PyTorch 2.6+无缝调用。模型权重通过Hugging Face开放下载,包含48B总参数(仅3B激活参数)的Instruct版本,可直接通过vLLM部署为API服务:
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/moonshotai/Kimi-Linear-48B-A3B-Instruct
# 安装依赖
pip install -U fla-core vllm
# 启动1M上下文服务
vllm serve ./Kimi-Linear-48B-A3B-Instruct \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 1048576 \
--trust-remote-code

该截图展示了Kimi-Linear-48B-A3B-Instruct模型在Hugging Face平台的开源主页入口。用户可直接获取模型权重、技术文档和社区支持,这一开放姿态将加速线性注意力技术的生态建设,推动更多行业应用落地。
行业影响:开启大模型"效率竞赛"新纪元
1. 技术路线分化加剧
Kimi Linear的开源将加速大模型架构的路线之争。目前行业已形成三大技术流派:
- 纯线性派:如Mamba、RetNet,追求极致效率,适合边缘设备部署
- 混合派:以Kimi Linear为代表,平衡性能与效率,主攻专业级应用
- 全注意力派:如GPT-4、Qwen-72B,保持精度优势,服务通用场景
月之暗面同时开源了KDA内核(集成于FLA框架),降低了混合架构的实现门槛。预计2026年前,30%以上的长上下文模型将采用类似混合设计。
2. 行业应用场景扩容
Kimi Linear的48B参数量模型(激活参数仅3B)已在多个领域展现落地价值:
| 应用场景 | 传统模型表现 | Kimi Linear优化效果 |
|---|---|---|
| 金融分析 | 10万行财报摘要需2小时 | 89%准确率,生成时间缩短至20分钟 |
| 代码开发 | 完整解析Linux内核需8小时 | 漏洞检测效率提升4倍,支持150万行代码 |
| 医疗研究 | 1000例病历分析需3天 | 疾病关联分析时间压缩至4小时 |
据测算,该架构可为专业领域用户降低60%的算力成本,同时将任务完成时间压缩75%,显著拓展了大模型的商业化边界。
3. 开源生态加速迭代
作为首个超越全注意力的混合架构,Kimi Linear已获得vLLM、Text Generation Inference等主流推理框架的官方支持。开源社区已基于KDA内核衍生出8个优化版本,其中量化版模型将显存需求进一步降至4GB,推动大模型向边缘设备普及。
结论与前瞻
Kimi Linear的开源不仅是一次技术突破,更标志着大模型发展从"参数竞赛"转向"效率竞赛"。其混合线性注意力架构证明,通过精细化设计而非单纯堆参数量,同样可以实现性能飞跃。对于行业而言,这一创新将加速大模型在专业领域的渗透,尤其在法律、医疗、金融等对长文本处理需求强烈的场景。
未来,随着KDA门控机制的进一步优化和硬件适配,我们有理由期待:2026年前后,10亿参数级模型将具备当前千亿模型的长文本处理能力,真正实现"小而美"的大模型应用愿景。对于开发者和企业而言,现在正是布局混合线性注意力技术的最佳时机,以把握下一波效率革命的红利。
(欢迎点赞收藏本文,关注作者获取Kimi Linear实战教程更新)
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







