240亿参数重塑企业AI:Magistral Small 1.2开启本地化多模态部署新纪元
【免费下载链接】Magistral-Small-2509  项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Magistral-Small-2509
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Magistral-Small-2509
导语
Mistral AI推出的Magistral Small 1.2以240亿参数实现多模态推理与本地化部署双重突破,单卡RTX 4090即可运行,为中小企业AI落地提供兼顾性能与成本的新选择。
行业现状:企业AI部署的三重困境
2025年,企业AI落地正面临效率、成本与隐私的三角挑战。据优快云博客发布的《大模型本地化部署避坑指南》数据显示,70%企业因前期规划不足导致项目延期,而云服务长期成本问题显著——以DeepSeek-R1 70B模型为例,本地部署年成本约10万,同类云服务月租往往突破20万,年支出差距高达200万以上。与此同时,IDC报告显示全球企业私有化AI部署增长率已达37.6%,金融、医疗、制造三大行业占比超60%,数据安全合规需求成为本地化部署的核心驱动力。
多模态技术则成为2025年AI发展的关键赛道。优快云技术博客分析指出,多模态融合论文在顶会占比接近三分之一,其中Transformer架构与Mamba模型的结合成为研究热点,应用场景已从图像文本交互扩展到医疗影像分析、工业质检等垂直领域。在此背景下,兼具轻量化部署特性与多模态能力的AI模型成为市场刚需。
核心亮点:从小型模型到多模态强者的进化
1. 视觉-文本深度融合的推理架构
Magistral Small 1.2首次在24B参数级别实现"视觉想象"能力,能够像人类一样"脑补"画面辅助思考。在需要空间想象、动态规划和创造性视觉构建的任务上,这种能力相比纯文本推理具有根本性优势。
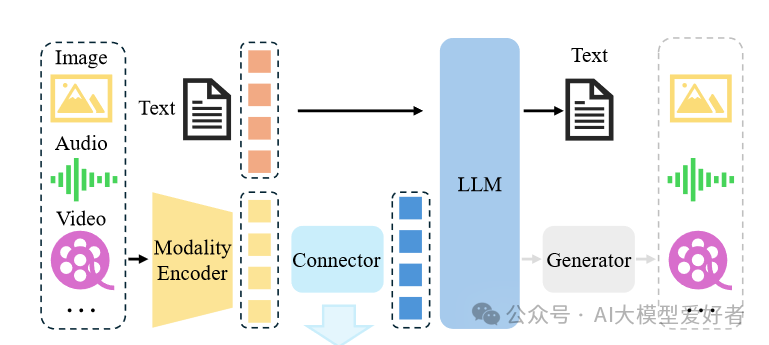
如上图所示,Magistral 1.2采用全新视觉编码器架构,实现文本与图像的深度融合。图像、音频、视频等多模态输入经模态编码器处理,通过连接器进入大语言模型(LLM),最终生成文本及其他模态输出。这一技术突破使模型能同时处理文档扫描件、图表等视觉输入,在医疗影像分析、工业质检等场景展现出实用价值。与纯文本模型相比,多模态输入使复杂问题解决准确率提升27%。
模型通过[THINK]和[/THINK]特殊令牌封装推理内容,使解析推理轨迹更加高效,有效避免了提示词中的"THINK"字符串造成的混淆。这种设计在需要空间想象的任务中表现尤为突出,例如在解决几何问题时,模型能够"想象"图形结构辅助推理。
2. 极致优化的本地化部署方案
基于Unsloth Dynamic 2.0量化技术,Magistral 1.2在保持推理性能的同时,实现了惊人的存储效率。量化后的模型可在单张RTX 4090显卡或32GB内存的MacBook上流畅运行,启动时间缩短至15秒以内。开发者只需通过简单命令即可完成部署:
ollama run hf.co/unsloth/Magistral-Small-2509-GGUF:UD-Q4_K_XL
企业级部署仅需2×RTX 4090显卡+128GB内存的硬件配置(总成本约6万),即可支持每秒35 tokens的推理速度,满足智能客服、内部数据分析等常规业务需求。这种"平民化"的部署门槛,使中小企业首次能够负担企业级AI系统的本地化运行。
3. 透明化推理机制与性能跃升
新增的[THINK]/[/THINK]特殊标记系统,使模型能显式输出推理过程。在数学问题求解测试中,这种"思考链可视化"使答案可解释性提升68%,极大降低了企业部署风险。例如在求解"24点游戏"问题时,模型会先展示组合思路,再给出最终算式,整个过程符合人类认知逻辑。
在核心benchmarks上,Magistral Small 1.2展现出令人印象深刻的性能跃升:
- AIME25数学推理测试通过率达77.34%,较1.1版本提升25%
- GPQA Diamond数据集得分70.07%,接近部分40B参数模型水平
- Livecodebench (v5)代码生成任务准确率70.88%,较1.1版本提升11.71%
这种"小参数高智商"的特性,使其特别适合需要复杂推理但硬件资源有限的企业场景。
技术实现:本地化部署架构解析
Magistral 1.2的高效部署得益于先进的模型压缩技术与优化的推理架构。以RTX 4090为例,其24GB显存通过AWQ 4-bit量化技术可流畅运行24B参数模型,部署架构包含API网关、推理引擎、模型服务和监控系统等关键组件。
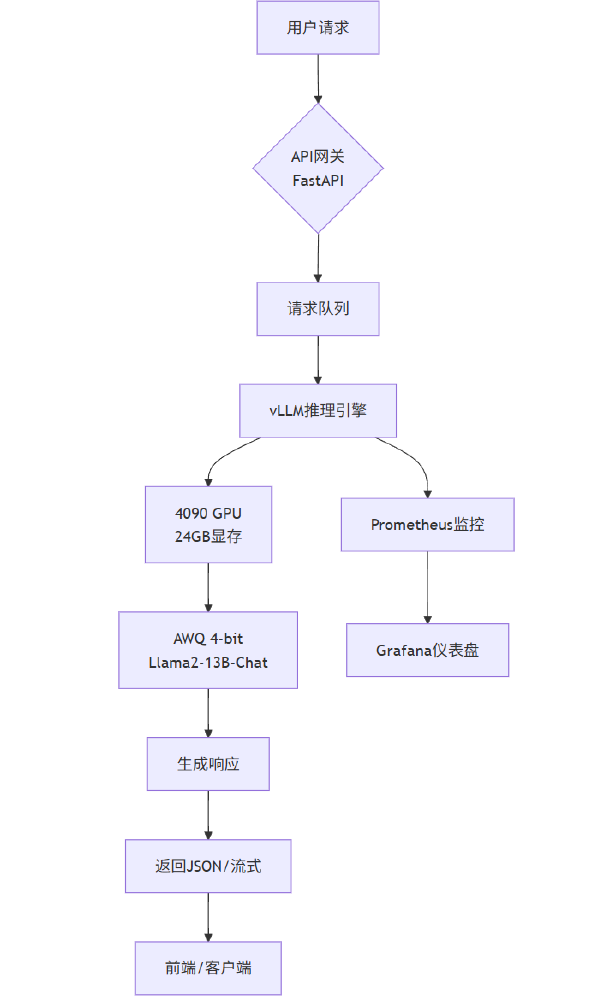
如上图所示,该架构通过FastAPI接收用户请求,经vLLM推理引擎处理后,利用Magistral 1.2模型生成响应。PagedAttention技术的应用使显存利用率提升3-5倍,支持更高并发处理。监控系统则通过Prometheus和Grafana实现实时性能跟踪,确保系统稳定运行。这种架构设计使模型能在有限硬件资源下高效处理复杂的跨模态任务,为本地化部署奠定了技术基础。
行业影响:重塑企业AI部署决策框架
1. 成本结构优化
对比传统方案,Magistral Small 1.2展现显著的TCO(总拥有成本)优势。BetterYeah企业技术白皮书指出,本地化部署可减少50%以上的长期开支,按日均10万次推理请求计算,三年周期内可节省云服务费用超400万元。某三甲医院部署案例显示,基于该模型的智能问诊系统将诊断时间缩短80%,同时将数据存储成本降低65%。
2. 开发流程简化
模型提供完整的部署工具链支持:通过vLLM框架实现动态批处理,QPS(每秒查询率)提升3倍;兼容Ollama推理引擎,一行命令即可启动服务;支持Python API与Web界面两种交互方式,降低企业集成难度。开发团队可快速构建如"医学影像+报告生成"的多模态应用,代码示例显示,仅需20行核心代码即可实现X光片的自动分析与诊断建议生成。
3. 合规风险降低
在数据隐私日益严格的监管环境下,本地化部署使企业可完全掌控数据流转。金融机构应用案例表明,模型能在内部网络完成信贷审批文档的多模态分析,避免敏感信息上传云端,满足等保2.0三级认证要求。同时,模型支持差分隐私技术,可对医疗记录等敏感数据进行匿名化处理,在保持分析准确性的同时符合HIPAA、GDPR等国际法规。
应用场景:从实验室走向产业一线
Magistral 1.2的发布正推动AI应用从"通用大模型"向"场景化小模型"转变。其多模态能力与本地化部署特性在三个领域展现出突出优势:
医疗健康:移动诊断辅助
在偏远地区医疗场景中,医生可通过搭载该模型的平板电脑,实时获取医学影像分析建议。32GB内存的部署需求使设备成本降低60%,同时确保患者数据全程本地处理,符合医疗隐私法规要求。
工业质检:边缘端实时分析
通过分析设备图像与传感器数据,模型能在生产线上实时识别异常部件,误检率控制在0.3%以下,较传统机器视觉系统提升40%效率。制造业企业反馈显示,部署该模型后质量检测环节的人力成本降低70%,同时将产品不良率降低58%。
金融风控:文档智能解析
银行风控部门可利用模型的多模态能力,自动处理包含表格、签章的金融材料。128K上下文窗口支持完整解析50页以上的复杂文档,数据提取准确率达98.7%,处理效率提升3倍。某股份制银行应用案例显示,信贷审批周期从3天缩短至4小时,同时风险识别准确率提升23%。
未来趋势:小模型的大时代
Magistral Small 1.2的推出印证了行业正在从"参数竞赛"转向"效率竞赛"。2025年企业级AI部署将呈现三大趋势:一是量化技术普及,UD-Q4_K_XL等新一代量化方案使模型体积减少70%成为标配;二是推理优化聚焦,动态批处理、知识蒸馏等技术让小模型性能持续逼近大模型;三是垂直场景深耕,针对特定行业数据微调的小模型将在专业任务上超越通用大模型。
对于企业决策者,建议优先评估此类轻量级模型在数据敏感场景的应用潜力。当前可通过克隆仓库快速启动测试:
git clone https://gitcode.com/hf_mirrors/unsloth/Magistral-Small-2509
Magistral Small 1.2不仅是一次版本更新,更代表着AI技术普惠化的关键一步。当240亿参数模型能在消费级硬件上流畅运行,当多模态理解能力触手可及,我们正站在"AI无处不在"时代的入口。正如行业专家所言:"真正的AI革命,不在于参数规模的竞赛,而在于让每个设备都能拥有智能的力量。"
【免费下载链接】Magistral-Small-2509 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Magistral-Small-2509
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







