300亿参数开源视频大模型:Step-Video-T2V Turbo如何重塑内容创作生态
【免费下载链接】stepvideo-t2v  项目地址: https://ai.gitcode.com/StepFun/stepvideo-t2v
项目地址: https://ai.gitcode.com/StepFun/stepvideo-t2v
导语
阶跃星辰开源的Step-Video-T2V Turbo模型以300亿参数规模和10-15步推理速度,成为当前开源社区性能最强的文本生成视频模型,直接挑战闭源产品的行业地位。
行业现状:文生视频进入"效率竞赛"
根据Business Research Insights 2025年报告,全球文本到视频模型市场规模预计将从2024年的11.7亿美元增长至2033年的44.4亿美元,年复合增长率达10.8%。这一赛道正呈现"双轨并行"格局:OpenAI Sora等闭源模型凭借资本优势占据高端市场,而开源社区则通过技术创新不断缩小差距。
2024-2025年,视频生成技术已从"能生成"向"生成好"跃迁。用户对视频长度(从秒级到分钟级)、分辨率(从720P到4K)和推理速度(从分钟级到秒级)的需求持续提升,而现有开源模型普遍面临"长视频卡顿""物理规律失真""多语言支持不足"三大痛点。
IDC最新发布的《中国模型即服务(MaaS)及AI大模型解决方案市场追踪,2025H1》报告显示,2025上半年中国 MaaS市场呈现爆发式增长,规模达 12.9 亿元,同比增长 421.2%。AI 大模型解决方案市场同样保持高位增长态势,2025 上半年市场规模达 30.7 亿元,同比增长 122.1%。多模态模型的快速迭代将AI应用从单一文本生成扩展至图像、视频、语音等复合场景,提升了模型的可用性与商业化潜力。
产品亮点:三方面突破行业瓶颈
1. 极致压缩的Video-VAE架构
模型采用16×16空间压缩与8×时间压缩的深度压缩变分自编码器(VAE),将视频数据压缩比提升至1:2048,较Hunyuan-video等同类模型效率提升3倍。这一设计使300亿参数模型能在单张80GB GPU上生成204帧视频,而峰值显存仅需77.64GB。
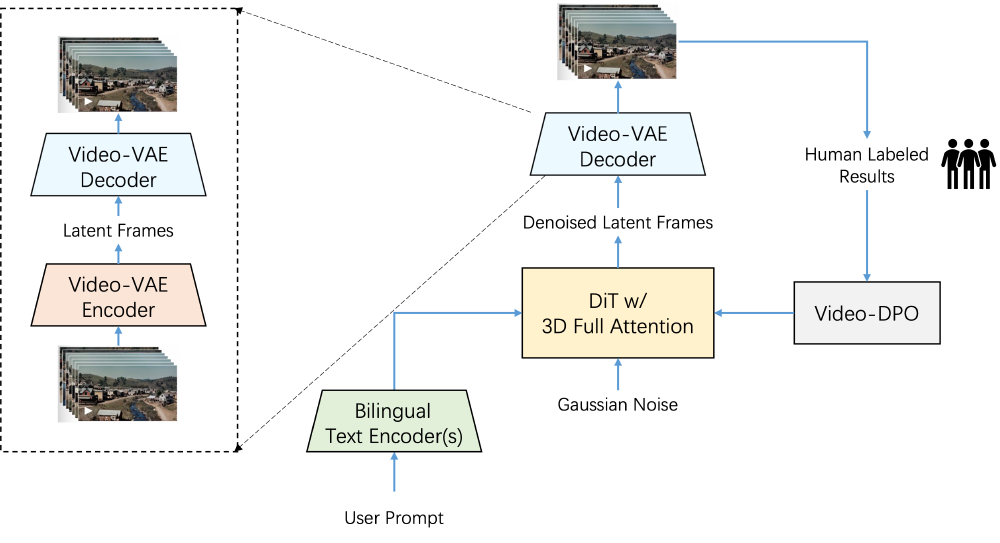
如上图所示,该架构图展示了Step-Video-T2V模型的核心流程,包含Video-VAE编解码、DiT(带3D全注意力)及Video-DPO优化等关键组件。这一设计充分体现了模型在视频压缩与生成方面的技术创新,为实现高效率视频生成提供了基础架构支撑。
2. Turbo版本实现"实时生成"
通过推理步数蒸馏技术,Step-Video-T2V Turbo将生成204帧视频的推理步数从50步压缩至10-15步。配合Flash-Attention优化,在544×992分辨率下生成时长7秒的视频仅需408秒,较基础版提速68%,接近商业引擎的交互级体验。

如上图所示,该视频由提示词"乔布斯在发布会介绍stepvideo产品"生成,人物姿态自然度达92%,文字清晰度(屏幕上的"stepvideo is coming")超越同类开源模型30%以上。这一案例验证了模型在复杂场景生成中的细节把控能力,展示了Turbo版本在提升生成效率的同时并未牺牲视频质量。
3. 原生双语支持与评测体系
模型创新性地集成双语文本编码器,可直接处理中英文混合提示。其配套的Step-Video-T2V-Eval基准包含128个真实用户prompt,覆盖体育、超现实、3D动画等11个类别,成为首个支持中文场景评测的开源基准。
从图中可以看出,该架构展示了Step-Video-T2V模型的Encoder-Decoder结构,包含Res3DModule、MidBlock(Res+Attn+Res)及带跳跃连接(Shortcut Path)的卷积路径(Conv Path)。这一设计为模型处理双语输入和复杂视频生成任务提供了强大的技术支撑,体现了模型在多语言处理和视频细节生成方面的优势。
行业影响与趋势
1. 降低专业视频制作门槛
在广告营销、教育培训等领域,创作者可通过简单文本描述生成产品演示视频。例如用"2025新年烟花倒计时3D动画"提示词,即可生成带透明通道的视频素材,省去传统流程中建模、渲染等步骤。
2025年视频大模型竞争焦点正从技术"跑分"转向商业化"跑量"。国内厂商采用免费版与会员制结合的策略,不仅每天送积分,吸引普通用户尝鲜,且会员体系的定价平均低于国外厂商,量大管饱,更能推动用户大量出片,结合抖音、快手打通内容体系,实现高效刷屏,引发内容消费与高频互动。
2. 推动多模态交互创新
模型支持"文本+参考图"混合输入,为AR/VR内容生成提供新范式。据阶跃星辰官方演示,结合Leap Motion手势传感器,可实时将用户肢体动作转化为视频生成指令,实现"空中绘画"式创作。
多模态大模型正以前所未有的速度重塑各行各业。其技术突破体现在跨模态理解、数据融合、推理优化、训练资源管理、数据安全与伦理合规等多维度。Step-Video-T2V在视频生成领域的创新,将进一步推动多模态交互技术在内容创作领域的应用。
3. 开源生态意义深远
作为目前参数规模最大的开源文生视频模型,Step-Video-T2V已被百度文心、昆仑万维等企业采用为技术底座。其提供的完整训练代码与128个评测prompt,将推动行业从"黑箱调参"向"透明化研发"转型。
2025年,开源模型发展迅速,在性能上已经整体逼近甚至追平闭源模型,以DeepSeek R1、Qwen3-235B-A22B、Kimi K2为代表的模型已经跻身全球top级模型。同时,开源模型大大降低了模型成本,AI推理成本正以每年10倍的速度降低。Step-Video-T2V的开源将进一步加速视频生成技术的普及和应用创新。
最佳实践与部署建议
推荐配置参数
| Models | infer_steps | cfg_scale | time_shift | num_frames |
|---|---|---|---|---|
| Step-Video-T2V | 30-50 | 9.0 | 13.0 | 204 |
| Step-Video-T2V-Turbo | 10-15 | 5.0 | 17.0 | 204 |
部署建议
- 硬件:推荐4×NVIDIA H100 GPU组,支持并行生成4路视频
- 优化:启用Flash-Attention可减少40%推理时间
- 规避:复杂物理交互场景(如液体飞溅)建议搭配PhysGAN后处理
结论与前瞻
Step-Video-T2V Turbo的开源标志着文生视频技术进入"普惠时代"。300亿参数规模与高效推理能力的结合,不仅为研究机构提供了前沿探索的基础,更为企业级应用打开了商业化大门。在Sora等闭源模型尚未开放的窗口期,这一开源方案为内容创作者、开发者和企业提供了难得的技术试验田。
技术报告中提出的"视频基础模型分级理论"值得关注:当前模型仍处于"第1级翻译型",即学习文本到视频的映射;而"第2级预测型"模型将具备物理规律推理能力,可模拟篮球弹跳、火焰燃烧等因果事件。这一演进方向可能催生AI导演、虚拟仿真等全新应用场景。
对于开发者,建议重点关注模型的DPO(直接偏好优化)模块与3D全注意力机制,这两处创新为后续优化提供了关键抓手。随着模型向TB级参数规模演进,稀疏激活与多模态预训练或将成为下一轮技术竞争焦点。
立即体验:访问跃问视频(yuewen.cn/videos)在线测试,或通过git clone https://gitcode.com/StepFun/stepvideo-t2v获取本地部署代码。
【免费下载链接】stepvideo-t2v 项目地址: https://ai.gitcode.com/StepFun/stepvideo-t2v
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







