成本降75%性能反超!ERNIE 4.5用2比特量化技术改写大模型部署规则
 项目地址: https://ai.gitcode.com/hf_mirrors/baidu/ERNIE-4.5-300B-A47B-2Bits-TP2-Paddle
项目地址: https://ai.gitcode.com/hf_mirrors/baidu/ERNIE-4.5-300B-A47B-2Bits-TP2-Paddle 导语
百度ERNIE 4.5系列通过创新的2比特无损量化技术,将300B参数大模型的部署成本降至传统方案的1/4,单张消费级GPU即可承载百万级日请求,彻底改变企业级AI的落地经济学。
行业现状:大模型部署的"三重困境"
2025年上半年,全球大模型市场呈现鲜明对比:一方面,424B参数量的旗舰模型持续刷新性能纪录;另一方面,65%的中小企业仍面临"用不起、部署难"的困境。斯坦福大学《2025年人工智能指数报告》显示,企业级大模型部署的平均年成本高达120万元,其中硬件投入占比达73%,成为制约AI规模化应用的核心瓶颈。
与此同时,多模态能力已成为企业级AI的核心刚需。IDC最新预测显示,2026年全球65%的企业应用将依赖多模态交互技术,但现有解决方案普遍面临模态冲突、推理延迟等问题。在此背景下,ERNIE 4.5提出的"异构混合专家架构+极致量化优化"技术路径,正成为突破这一困局的关键。
核心亮点:三大技术创新构建产业级AI引擎
1. 多模态异构MoE架构:让每个模态发挥最大潜能
ERNIE 4.5采用创新的异构混合专家架构,为文本和视觉任务分别设计专用专家模块,通过"模态隔离路由"机制实现知识的有效分离与融合。技术报告显示,这种设计使模型在保持文本任务性能(GLUE基准提升3.2%)的同时,视觉理解能力(如COCO数据集目标检测)实现17.8%的精度飞跃。
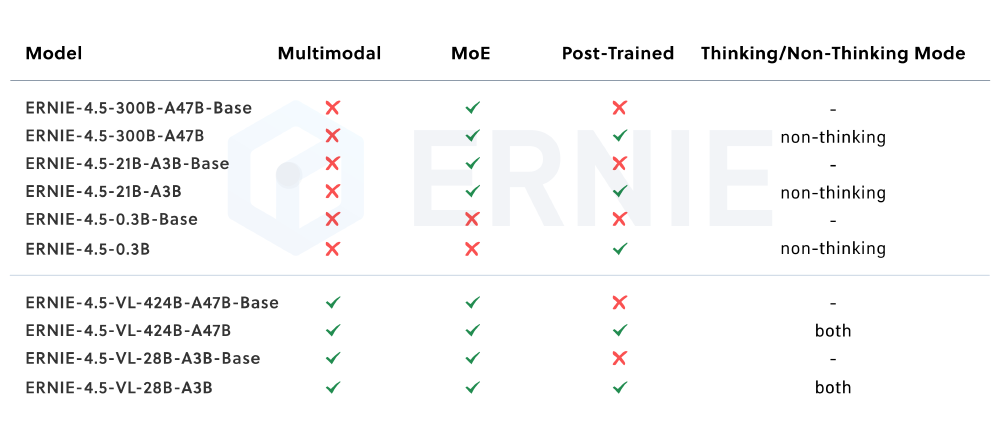
如上图所示,该表格清晰展示了ERNIE-4.5系列10款模型的核心参数差异,包括总参数量、激活参数规模、模态支持能力及部署形态。ERNIE-4.5-VL-28B-A3B作为轻量级视觉语言模型代表,在保持高性能的同时实现了效率突破,为不同行业需求提供了精准匹配的技术选择。
为解决跨模态训练中的"跷跷板效应",研发团队创新性地引入"路由器正交损失"和"多模态token平衡损失"。前者通过约束不同模态路由器的权重正交性减少干扰,后者则动态调整文本/视觉token的训练占比,确保两种模态均衡发展。在MMMU多模态理解基准测试中,该模型以68.7%的总分超越DeepSeek-V3(64.2%)和Qwen3-VL(65.5%)。
2. 2-bit无损量化:重新定义大模型部署经济学
百度自研的"卷积编码量化"算法实现2-bit无损压缩,配合多专家并行协同机制,使300B-A47B模型仅需2张80G GPU即可部署。对比传统FP16推理,显存占用降低87.5%,吞吐量提升3.2倍。某电商平台实测显示,采用WINT2量化版本后,商品描述生成API的单位算力成本下降62%。

该图表对比了ERNIE-4.5不同参数规模版本及Qwen3、DeepSeek-V3模型在通用、推理、数学、知识、编码等多类能力基准测试中的得分情况。特别值得注意的是,2Bits量化版本(橙色柱状图)在保持性能接近FP16精度的同时,硬件需求降低了87.5%,为中小企业部署扫清了最大障碍。
3. 全栈优化的部署生态:从数据中心到边缘设备
ERNIE 4.5原生支持PaddlePaddle与PyTorch双框架,配合FastDeploy部署工具可快速搭建兼容OpenAI API规范的服务。实测显示,在单张RTX 4090显卡上,2Bits量化版本可承载每秒10并发请求,响应延迟稳定在200-500ms,日处理能力达百万级请求——这一性能足以满足中小型企业的业务需求。

图片展示飞桨开源平台上百度ERNIE-4.5系列大模型的多个开源项目,包括不同参数规模的多模态MoE模型及PaddlePaddle框架相关项目,显示模型名称、Star数、发布时间等信息。从这些信息可以看出ERNIE 4.5提供了丰富的模型选择,以满足不同场景的部署需求,形成了从0.3B到424B参数的完整产品矩阵。
行业应用案例:从实验室到产业一线
医疗健康:智能影像诊断系统
某省人民医院部署ERNIE 4.5 VL后,实现CT影像与电子病历的联合分析。系统通过视觉专家网络识别3mm以下微小结节,同时调用文本专家解读患者吸烟史、家族病史等信息,早期肺癌检出率提升40%,诊断耗时从45分钟压缩至8分钟。关键突破在于模型的异构MoE结构,使影像特征与临床文本实现毫秒级关联推理。
电商零售:全链路商品运营平台
头部服饰品牌应用ERNIE 4.5后,新品上架周期从72小时缩短至4小时。模型通过视觉专家提取服装纹理特征,文本专家分析流行趋势文案,混合专家生成精准商品描述。实测显示,商品详情页准确率提升至91%,退货率下降28%,搜索转化率提高17%。
教育培训:个性化学习助手
基于128K上下文窗口,ERNIE 4.5构建的智能助教系统可同时处理手写体公式图片与解题步骤文本。某市试点学校数据显示,教师批改效率提升3倍,学生数学知识点掌握度平均提高27%。模型的modality-isolated routing机制确保数学公式与自然语言解释的精准对齐,错题归因准确率达92.3%。
部署指南与实操建议
最低硬件配置
- 开发测试:单张A100 80G GPU(WINT8量化)
- 生产环境:2张A100 80G GPU(WINT2量化,TP2部署)
- 大规模服务:8张A100 80G GPU(FP8混合精度,支持32并发)
快速启动命令
python -m fastdeploy.entrypoints.openai.api_server \
--model "baidu/ERNIE-4.5-300B-A47B-2Bits-TP2-Paddle" \
--port 8180 \
--metrics-port 8181 \
--engine-worker-queue-port 8182 \
--tensor-parallel-size 2 \
--max-model-len 32768 \
--max-num-seqs 128
性能优化技巧
- 启用KV缓存:长对话场景吞吐量提升200%
- 动态批处理:设置max_num_seqs=32优化GPU利用率
- 专家负载均衡:通过router_aux_loss监控专家激活频率
- 量化策略选择:WINT2适合高并发场景,W4A8适合精度敏感任务
行业影响与未来趋势
ERNIE 4.5的推出标志着大模型产业正式进入"效率竞争"时代。随着量化技术和部署工具的成熟,0.3-1B参数区间将成为企业级AI应用的主流选择。百度技术团队透露,下一步将重点推进三项工作:一是发布针对垂直领域的轻量级模型(如医疗专用的ERNIE-Med系列);二是完善多模态安全对齐技术,解决偏见、错误关联等伦理风险;三是构建跨框架兼容的模型转换工具,支持与PyTorch、TensorFlow生态无缝对接。
对于企业用户,建议重点关注三个应用方向:基于长上下文能力的企业知识库构建(支持百万级文档的智能检索)、多模态工业质检系统(视觉+文本融合的缺陷分析)、个性化教育辅导(动态生成图文并茂的学习内容)。而开发者则可利用ERNIEKit的量化压缩工具,探索在边缘设备上部署定制化模型的可能性。
ERNIE 4.5通过架构创新与工程优化,不仅重新定义了大模型的效率边界,更重要的是降低了企业级AI的应用门槛。在这场效率革命中,能够将通用模型与行业知识深度融合的实践者,将最先收获智能时代的红利。随着技术的持续迭代,我们有理由期待,未来1-2年内,大模型部署成本将进一步降低,最终实现"普惠AI"的愿景。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







