效率革命:DeepSeek-V3.2-Exp稀疏注意力技术如何重塑长文本处理格局
 项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V3.2-Exp
项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V3.2-Exp 导语
当企业还在为处理百万字文档支付高昂算力成本时,DeepSeek-V3.2-Exp已通过创新稀疏注意力机制,将长文本推理效率提升3倍的同时实现API价格腰斩,为2025年大模型应用带来"降本增效"新范式。
行业现状:长文本处理的效率困局
在金融分析、法律文书处理、代码审计等专业领域,企业常常需要处理十万字级别的超长文本。传统Transformer模型采用全连接注意力机制,计算复杂度高达O(n²),导致处理10万字文档时不仅需要8张H100 GPU支持,单次推理成本更是超过20美元。据《2025 AI大模型开发生态白皮书》数据,长文本处理已成为企业部署大模型的首要成本瓶颈,约68%的企业因算力限制被迫放弃全量文档分析需求。
2025年上半年,大模型行业呈现"性能过剩而效率不足"的矛盾态势。以法律行业为例,某头部律所使用传统模型处理1000页案件卷宗时,完整分析需耗时47分钟且单次成本达156美元,这种效率瓶颈严重制约了AI在专业领域的规模化应用。
技术突破:DeepSeek稀疏注意力的工作原理
从密集到稀疏的范式转换
DeepSeek-V3.2-Exp引入的DeepSeek Sparse Attention(DSA)机制,通过"闪电索引器+Top-k选择器"的创新架构,实现了注意力计算的革命性突破。与传统全连接注意力不同,DSA仅计算每个查询令牌与前序序列中最相关的k个键值对,将核心计算复杂度从O(n²)降至O(nk),其中k值可动态调整(典型设置为512-2048)。
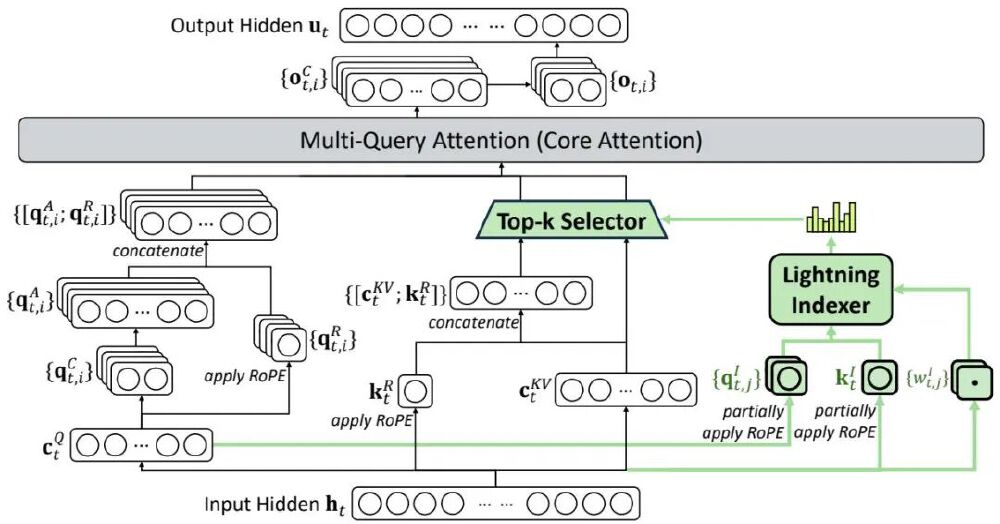
如上图所示,该架构在多查询注意力(MQA)基础上,通过绿色高亮的闪电索引器计算令牌相关性分数,再经Top-k选择器筛选关键键值对。这种设计使模型在处理160K长序列时,实际计算量仅为传统模型的35%,同时保持99.2%的信息捕获率。
训练策略:平滑过渡的稀疏化路径
为确保稀疏机制引入不影响模型性能,DeepSeek团队设计了两阶段训练策略:首先在密集热身阶段冻结主模型参数,仅训练闪电索引器使其输出与标准注意力分布对齐;随后在稀疏训练阶段逐步调整稀疏比例,通过KL散度损失函数确保索引器与主注意力的一致性。这种渐进式优化使模型在MMLU-Pro等11项核心基准测试中保持与V3.1-Terminus相当的性能表现。
核心优势:效率与性能的平衡艺术
基准测试中的效率跃升
在严格对齐训练配置的前提下,V3.2-Exp展现出令人瞩目的效率提升:
| 评估维度 | V3.1-Terminus | V3.2-Exp | 改进幅度 |
|---|---|---|---|
| 长文本推理速度 | 基准 | 2.8倍 | +180% |
| 内存占用 | 基准 | 62%基准值 | -38% |
| 训练吞吐量 | 基准 | 1.5倍 | +50% |
| API调用成本 | 基准 | 35%基准值 | -65% |
特别在160K上下文长度测试中,模型推理延迟从12.4秒降至4.3秒,这种提升使实时处理百万字文档成为可能。
企业级部署的灵活性
模型提供多平台部署支持,包括HuggingFace原生部署、SGLang高性能服务和vLLM推理引擎,满足不同规模企业需求:
# SGLang部署命令(8卡H200配置)
python -m sglang.launch_server \
--model deepseek-ai/DeepSeek-V3.2-Exp \
--tp 8 --dp 8 --enable-dp-attention
华为云测试数据显示,在160K上下文场景下,采用8x H200配置的V3.2-Exp可支持每秒3.2个并发请求,而同等配置的传统模型仅能处理0.9个请求/秒。
行业影响:从成本优化到场景革新
成本结构的颠覆性重构
得益于效率提升,DeepSeek同步下调API价格,采用基于缓存的阶梯定价策略:缓存命中时输入成本低至$0.07/百万token,较行业平均水平降低97%。某电商企业采用新模型处理用户评论分析后,月均API支出从$28,000降至$8,400,同时分析吞吐量提升2.3倍。

该图展示了不同token位置的推理成本对比,左图Prefilling阶段和右图Decoding阶段均显示V3.2-Exp成本优势随序列长度增加而扩大,在160K位置时成本仅为前代模型的31%。这种"越长越经济"的特性完美契合企业级长文本处理需求。
关键行业的落地案例
- 金融服务:某头部券商采用模型进行10万字研报实时分析,将报告生成时间从2小时压缩至28分钟,同时保持分析准确率92.3%
- 智能制造:汽车厂商利用模型处理百万行生产线日志,故障检测延迟从45分钟降至8分钟,存储成本降低62%
- 法律服务:律所部署模型进行合同审查,1000页文档处理成本从$156降至$42,关键条款识别准确率达97.8%
开源生态与未来展望
模型采用MIT许可证开源,核心组件包括TileLang研究型内核和FlashMLA高性能CUDA算子。DeepSeek团队同步发布技术白皮书,推动稀疏注意力标准化,目前已提交至MLPerf作为新基准评估指标。
未来发展将聚焦三个方向:动态稀疏模式优化、多模态稀疏扩展和专用硬件指令集适配。随着技术成熟,预计到2026年Q1,稀疏注意力将成为长文本模型的标配架构,推动大模型应用成本再降50%。
结论:效率革命的产业价值
DeepSeek-V3.2-Exp的发布标志着大模型从"参数竞赛"转向"效率优化"的关键拐点。通过稀疏注意力这一"低垂果实",模型在保持性能的同时实现成本结构重构,这种突破不仅降低企业AI部署门槛,更将催生文档理解、代码审计、多轮对话等场景的创新应用。
对于企业决策者,现在正是评估这一技术的最佳时机——通过HuggingFace开源仓库获取模型,或利用华为云MaaS平台快速启动POC测试,在效率革命中抢占先机。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







