DataHub元数据血缘:上游下游关系解析
【免费下载链接】datahub  项目地址: https://gitcode.com/gh_mirrors/datahub/datahub
项目地址: https://gitcode.com/gh_mirrors/datahub/datahub
在数据驱动决策的时代,企业数据系统如同复杂的生态系统,数据从产生到最终应用往往要经过多个处理环节。当数据出现异常时,运营人员需要快速定位问题根源;当业务需求变更时,开发人员需要评估影响范围。这些场景都离不开对数据上下游关系的清晰掌握。DataHub的元数据血缘功能通过可视化的方式呈现数据的流转路径,帮助用户直观理解数据的来源与去向,为数据治理、问题排查和系统优化提供有力支持。
元数据血缘核心概念
元数据血缘(Metadata Lineage)是指数据从产生、处理、转换到消费的整个生命周期中,各个数据实体之间的上下游关系。在DataHub中,这种关系不仅包括表级别的依赖,还能深入到列级别,精确展示数据字段的来源和流向。
DataHub血缘功能主要关注以下实体间的关系:
- 数据集(Dataset):包括数据库表、数据仓库中的表、文件等数据载体
- 数据作业(Data Job):如ETL任务、数据处理脚本等
- 数据流(Data Flow):由多个数据作业组成的完整数据处理流程
通过这些实体间关系的追踪,DataHub能够构建出完整的数据血缘图谱,帮助用户回答"这个数据从哪里来"和"这个数据到哪里去"的关键问题。
血缘信息采集方式
DataHub支持多种方式采集数据血缘信息,以适应不同的数据处理场景和工具链。
Airflow集成
Airflow作为流行的工作流调度工具,其DAG(有向无环图)本身就定义了任务之间的依赖关系。DataHub提供了专门的Airflow插件,能够自动提取这些依赖关系并转化为血缘信息。
插件安装与配置
DataHub Airflow插件分为v1和v2两个版本,其中v2版本支持更丰富的功能。安装命令如下:
pip install 'acryl-datahub-airflow-plugin[plugin-v2]'
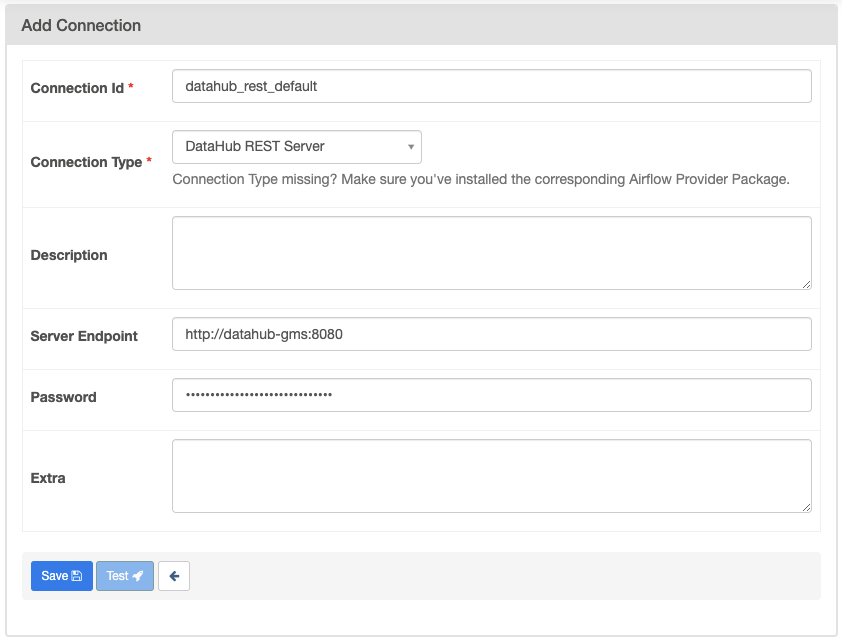
安装完成后,需要配置DataHub连接。可以通过Airflow CLI执行以下命令:
airflow connections add --conn-type 'datahub_rest' 'datahub_rest_default' --conn-host 'http://datahub-gms:8080' --conn-password '<optional datahub auth token>'
也可以在Airflow UI中手动配置连接,导航到Admin -> Connections,创建一个类型为"DataHub REST Server"的连接。
自动与手动血缘提取
v2插件支持自动从多种Operator中提取血缘信息,包括SQL类Operator(如MySqlOperator、PostgresOperator、SnowflakeOperator等)和文件处理Operator(如S3FileTransformOperator)。其原理是基于Airflow的OpenLineage extractors,并结合DataHub的SQL血缘解析器,能够生成更准确的列级别血缘。
对于不支持自动提取的场景,DataHub允许通过inlets和outlets手动标注血缘关系:
from datahub_airflow_plugin.entities import Dataset
task = PythonOperator(
task_id="process_data",
python_callable=process_data,
inlets=[Dataset("hive", "default", "user_data")],
outlets=[Dataset("hive", "default", "processed_user_data")],
dag=dag,
)
更多详细信息可参考官方文档:docs/lineage/airflow.md
Dagster集成
Dagster作为另一种流行的数据流编排工具,DataHub提供了专门的Sensor来捕获其元数据和血缘信息。
集成步骤
首先安装Dagster插件:
pip install acryl_datahub_dagster_plugin
然后在Dagster定义中添加DataHub Sensor:
from datahub_dagster_plugin.sensor import datahub_sensor
defs = Definitions(
assets=[my_asset],
sensors=[datahub_sensor],
)
启动Dagster后,在UI的Overview -> Sensors菜单中启用datahub_sensor,传感器将在每次 pipeline 运行后自动向DataHub发送元数据和血缘信息。
自定义血缘提取逻辑
DataHub允许用户定义自定义的血缘提取逻辑,通过实现asset_lineage_extractor函数,可以根据业务需求捕获特定的资产血缘关系:
from datahub_dagster_plugin.client.dagster_generator import DagsterGenerator, DatasetLineage
def asset_lineage_extractor(
context: RunStatusSensorContext,
dagster_generator: DagsterGenerator,
graph: DataHubGraph,
) -> Dict[str, DatasetLineage]:
dataset_lineage: Dict[str, DatasetLineage] = {}
# 自定义血缘提取逻辑
return dataset_lineage
详细示例可参考 metadata-ingestion-modules/dagster-plugin/examples/advanced_ops_jobs.py
OpenLineage集成
OpenLineage是一个开源的 lineage 标准,旨在统一不同数据处理工具的血缘数据格式。DataHub提供了对OpenLineage的原生支持,能够接收和处理符合OpenLineage规范的血缘事件。
REST端点使用
DataHub提供了专门的REST端点接收OpenLineage事件,只需向以下地址发送POST请求:
POST GMS_SERVER_HOST:GMS_PORT/api/v2/lineage
请求体示例:
{
"eventType": "START",
"eventTime": "2020-12-28T19:52:00.001+10:00",
"run": {
"runId": "d46e465b-d358-4d32-83d4-df660ff614dd"
},
"job": {
"namespace": "workshop",
"name": "process_taxes"
},
"inputs": [
{
"namespace": "postgres://workshop-db:None",
"name": "workshop.public.taxes",
"facets": {
"dataSource": {
"_producer": "https://github.com/OpenLineage/OpenLineage/tree/0.10.0/integration/airflow",
"_schemaURL": "https://raw.githubusercontent.com/OpenLineage/OpenLineage/main/spec/OpenLineage.json#/definitions/DataSourceDatasetFacet",
"name": "postgres://workshop-db:None",
"uri": "workshop-db"
}
}
}
],
"producer": "https://github.com/OpenLineage/OpenLineage/blob/v1-0-0/client"
}
Airflow配置示例
对于Airflow,可以通过配置OpenLineage transport将血缘信息发送到DataHub:
{
"type": "http",
"url": "https://GMS_SERVER_HOST:GMS_PORT/openapi/openlineage/",
"endpoint": "api/v1/lineage",
"auth": {
"type": "api_key",
"api_key": "your-datahub-api-key"
}
}
血缘关系可视化与应用
DataHub不仅能够采集血缘信息,还提供了直观的可视化界面,帮助用户理解和利用这些关系。
血缘图查看
在DataHub UI中,每个数据集详情页面都有专门的"Lineage"标签页,展示该数据集的上下游关系。用户可以通过缩放、平移等操作探索复杂的血缘网络,点击任意节点可查看对应实体的详细信息。
血缘查询
对于复杂的血缘关系,DataHub提供了强大的查询能力。通过GraphQL API,用户可以精确查询特定实体的上下游关系:
query {
dataset(urn: "urn:li:dataset:(urn:li:dataPlatform:hive,default.users,PROD)") {
upstreamLineage(
input: { direction: UPSTREAM, depth: 3, includeEdges: true }
) {
nodes {
urn
type
... on Dataset {
name
platform {
name
}
}
}
edges {
sourceUrn
destinationUrn
type
}
}
}
}
实际应用场景
-
问题排查:当某个报表数据异常时,通过血缘图可以快速定位上游数据源,逐级排查问题根源。
-
影响分析:当需要修改某个核心表结构时,通过血缘分析可以评估该变更对下游所有依赖系统的影响范围。
-
数据治理:通过血缘关系,可以追踪敏感数据的流转路径,确保数据使用符合合规要求。
-
系统优化:识别血缘图中的关键节点和瓶颈,为系统优化提供依据。
快速开始使用血缘功能
环境准备
- 安装Docker和Docker Compose
- 安装DataHub CLI:
python3 -m pip install --upgrade acryl-datahub
- 启动DataHub:
datahub docker quickstart
- 摄入示例数据,包含血缘关系:
datahub docker ingest-sample-data
- 访问DataHub UI:http://localhost:9002(默认用户名/密码:datahub/datahub)
查看示例血缘
在DataHub UI中,导航到"Browse" -> "Datasets",选择任意数据集,点击"Lineage"标签页即可查看其血缘关系图。
总结与展望
DataHub的元数据血缘功能通过灵活的采集方式和直观的可视化界面,帮助用户深入理解数据的来龙去脉。无论是Airflow、Dagster等调度工具,还是遵循OpenLineage标准的系统,DataHub都能无缝集成,构建完整的血缘图谱。
随着数据生态系统的不断复杂化,血缘信息将在数据治理、系统优化和业务决策中发挥越来越重要的作用。DataHub团队也在持续增强血缘功能,未来将支持更细粒度的血缘追踪、更丰富的可视化选项和更强大的分析能力,帮助用户更好地驾驭数据资产。
要深入了解DataHub血缘功能,可以参考以下资源:
【免费下载链接】datahub 项目地址: https://gitcode.com/gh_mirrors/datahub/datahub
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







