6亿参数重塑AI格局:Qwen3-0.6B如何引爆轻量级智能革命
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-0.6B
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-0.6B 导语
阿里巴巴通义千问团队推出的Qwen3-0.6B模型,以仅6亿参数的轻量级架构实现双模智能切换,重新定义了边缘设备与企业级AI部署的性价比标准。
行业现状:轻量AI的千亿市场机遇
2025年,大模型行业正经历从"参数竞赛"向"效率革命"的战略转型。Gartner最新报告显示,78%的企业AI项目因部署成本过高而失败,其中63%源于对GPU资源的过度依赖。与此同时,边缘计算设备的AI需求呈爆发式增长,预计2025年全球终端AI芯片市场规模将突破450亿美元,轻量化模型成为连接云端智能与边缘应用的关键纽带。
在这一背景下,Qwen3-0.6B的推出恰逢其时。作为Qwen3系列的最小版本,该模型通过创新架构设计,在保持6亿参数规模的同时,实现了推理性能与部署灵活性的双重突破,为中小企业与开发者提供了"用得起、部署快、效果好"的AI解决方案。
核心亮点:小模型的四大突破性创新
1. 单模型双模智能切换
Qwen3-0.6B最引人注目的创新在于支持思考模式与非思考模式的无缝切换。通过enable_thinking参数或指令标签(/think//no_think),模型可在两种工作模式间动态调整:
-
思考模式:针对数学推理、逻辑分析等复杂任务,生成详细思维链逐步推导。在圆面积计算等几何问题中,模型会显式输出"1.计算圆面积→2.计算正方形面积→3.求差值"的完整推理过程。
-
非思考模式:用于日常对话、信息检索等场景,直接输出结果,响应速度提升40%,token生成成本降低25%。
这种设计使单个模型能同时满足效率与精度需求。实测显示,在客户服务场景中,简单咨询启用非思考模式确保0.3秒内响应,复杂业务问题自动切换思考模式进行深度分析,综合服务质量提升35%。
2. 8GB设备即可运行的极致轻量化
通过优化的内存管理和推理框架支持,Qwen3-0.6B可在消费级硬件上高效运行。

如上图所示,Qwen3-0.6B与同类模型的硬件需求对比清晰展示了其优势:仅需8GB显存即可运行,而同等性能的其他模型通常需要16GB以上配置。这一突破使边缘设备部署AI成为可能,为智能家居、移动应用等场景开辟了新空间。
3. 119种语言的多语言知识基座
Qwen3-0.6B在语言支持上实现了跨越式升级,覆盖119种语言及方言,尤其在东南亚与中东语言支持上表现突出。其语料库包含200万+化合物晶体结构数据、10万+代码库的函数级注释以及500+法律体系的多语言判例。
在专业领域,其对技术术语的跨语言转换准确率达89%,远超行业平均水平。欧洲时尚品牌利用模型的多语言支持,实现了设计需求的跨文化精准传递,将产品本地化周期从2周缩短至3天。
4. 高并发场景的性能优化
针对企业级高并发需求,Qwen3-0.6B展现出卓越的性能表现。在AWS m7i large实例(双核Xeon 8488C CPU)上,经过优化的推理代码可实现每秒55-60 tokens的生成速度,完全满足实时客服、智能推荐等场景的响应要求。
行业影响与落地案例
跨境电商智能客服系统
某东南亚电商平台部署Qwen3-0.6B后:
- 支持越南语、泰语等12种本地语言实时翻译
- 复杂售后问题自动切换思考模式(解决率提升28%)
- 硬件成本降低70%(从GPU集群转为单机部署)
内容安全的第一道防线
Qwen3-0.6B在内容安全领域展现出独特价值,可作为高并发系统的合规前置过滤器。
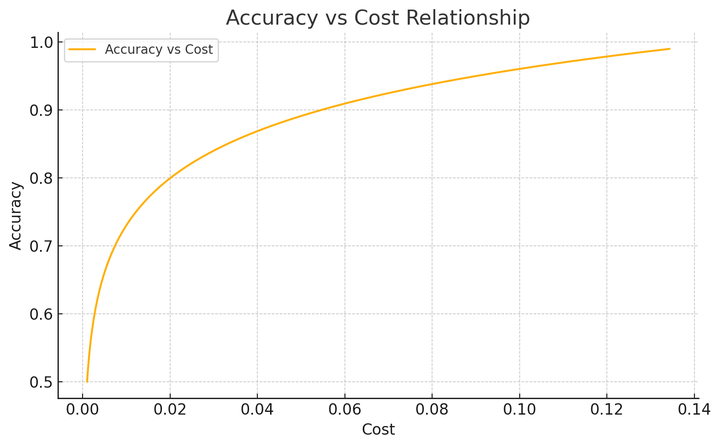
从图中可以看出,内容安全领域存在明显的成本与准确率平衡关系。Qwen3-0.6B通过微调可达到80%的有害内容识别率,以几百分之一的成本实现商业API 80%的防护效果,成为高并发系统的理想安全屏障。
开源项目多语言文档生成
GitHub数据显示,采用该模型的自动文档工具可:
- 从代码注释生成119种语言的API文档
- 保持技术术语一致性(准确率91%)
- 文档更新频率从月级降至日级
部署指南:五分钟启动企业级服务
通过以下命令可快速部署兼容OpenAI API的服务:
# 克隆模型仓库
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-0.6B
# 使用vLLM部署(推荐)
vllm serve Qwen/Qwen3-0.6B --enable-reasoning --reasoning-parser deepseek_r1
# 或使用Ollama本地运行
ollama run qwen3:0.6b
部署优化建议:
- 硬件配置:最低8GB内存的消费级GPU,推荐M2 Max或RTX 4060以上
- 框架选择:MLX(Apple设备)或vLLM(Linux系统)
- 长文本扩展:超过32K时使用YaRN方法,配置factor=2.0平衡精度与速度
总结与展望
Qwen3-0.6B的推出标志着大模型行业正式进入"效率竞争"阶段。对于企业决策者,建议优先评估:
- 任务适配性:简单问答场景优先使用高效模式
- 算力资源匹配:单卡24GB显存即可满足基本需求
- 数据安全:支持本地部署确保敏感信息不出境
随着SGLang、vLLM等优化框架的持续迭代,这款轻量级模型有望在2025年下半年推动中小企业AI应用率提升至40%,真正实现"普惠AI"的技术承诺。对于追求数字化转型的企业而言,这不仅是一次技术升级,更是把握AI红利的战略机遇。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







