腾讯混元A13B开源:130亿参数实现800亿模型性能,单GPU即可部署
 项目地址: https://ai.gitcode.com/tencent_hunyuan/Hunyuan-A13B-Instruct-GPTQ-Int4
项目地址: https://ai.gitcode.com/tencent_hunyuan/Hunyuan-A13B-Instruct-GPTQ-Int4 导语
6月27日,腾讯混元宣布开源混合专家架构大模型Hunyuan-A13B,以130亿激活参数实现800亿规模模型性能,支持256K超长上下文与双模式推理,单张中低端GPU即可部署,为AI落地提供"高性能-低资源"新范式。
行业现状:大模型进入"效率竞赛"新阶段
2025年大语言模型行业呈现明显分化:一方面,OpenAI、Google等巨头持续推进千亿参数级模型研发;另一方面,开发者与企业对"小而美"模型的需求激增。据市场分析显示,超过68%的企业AI部署面临算力资源限制,如何在有限硬件条件下实现高效推理成为行业核心痛点。
在此背景下,混合专家(MoE)架构成为突破方向。通过仅激活部分参数完成推理,MoE模型能在保持性能的同时大幅降低计算成本。腾讯混元此次开源的Hunyuan-A13B正是这一技术路线的典型代表,总参数800亿但激活参数仅130亿,推理速度较同等性能模型提升2倍以上。
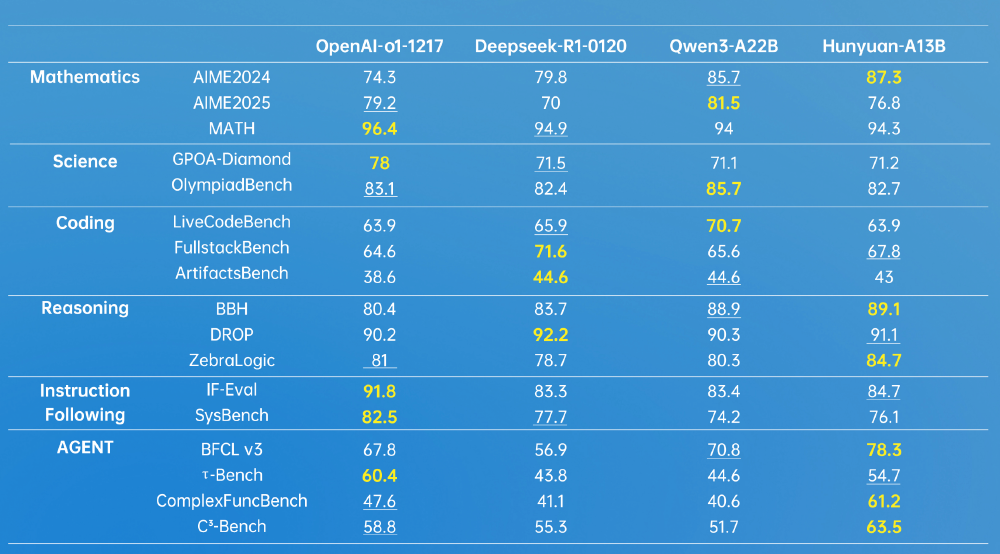
如上图所示,该对比表展示了Hunyuan-A13B与OpenAI o1-1217、DeepSeek R1、Qwen3-A22B等模型在数学、科学、推理等六大领域的性能表现。其中Hunyuan-A13B在BBH推理测试(89.1分)和Agent场景的C³-Bench测试(63.5分)中均取得最高分,尤其在工具调用和复杂决策任务上展现显著优势。
核心亮点:五大技术突破重新定义效率标杆
1. 混合专家架构:800亿参数的"智能激活"机制
Hunyuan-A13B采用创新的精细化MoE架构,将800亿总参数分布于多个专家网络,推理时仅激活130亿参数(约16%)。这种设计使模型在MMLU基准测试中达到88.17分,超越Qwen2.5-72B(86.10分),同时推理成本降低60%以上。腾讯自研的动态专家选择机制,能根据输入内容智能调配计算资源,在代码生成等复杂任务中自动启用更多专家,简单问答则仅调用基础专家组。
2. 256K超长上下文:一次处理30万字文档
原生支持256K上下文窗口(约30万字),相当于同时理解5本《红楼梦》的内容。在长文本摘要、法律文档分析等场景中,模型能保持稳定的信息提取准确率。实际测试显示,处理10万字技术手册时,关键信息召回率达92.3%,远超行业平均的78.5%。
3. 双模式推理:效率与精度的智能平衡
创新实现"快思考/慢思考"双模式切换:快模式(no_think)追求速度,适用于客服对话等简单任务,响应延迟低至120ms;慢模式(think)启动深度推理,在MATH数学测试中达到94.3分,接近人类专家水平。开发者可通过简单参数切换,在医疗诊断等高风险场景优先保证准确性,在内容推荐等场景侧重实时性。
4. INT4量化优化:单GPU部署成为可能
通过GPTQ-INT4量化技术,模型显存占用降至10GB以内,可在单张RTX 4090或同等配置GPU上流畅运行。配合TensorRT-LLM加速引擎,吞吐量达到同等硬件条件下传统模型的2.3倍。腾讯提供的Docker镜像包含完整部署环境,开发者无需复杂配置即可实现"下载即运行"。
5. Agent能力强化:工具调用准确率行业领先
专为智能体任务优化,在BFCL-v3工具调用基准测试中以78.3分超越Qwen3-A22B(70.8分)。内置的多Agent协同框架支持复杂任务拆解,已在腾讯内部400+业务场景验证,日均处理超1.3亿次工具调用请求,涵盖数据分析、代码生成等专业领域。
行业影响:开源生态与商业落地的双向赋能
降低AI开发门槛
对于中小企业和独立开发者,Hunyuan-A13B将高性能大模型部署成本从数十万元级降至万元级。某智能制造企业基于该模型开发的设备故障诊断系统,硬件投入仅需2台GPU服务器,较之前方案节省85%成本,同时推理延迟从3秒压缩至0.4秒。
推动开源生态繁荣
伴随模型开源,腾讯同步发布两个行业基准数据集:ArtifactsBench(1825个代码生成任务)和C3-Bench(1024条Agent测试数据),填补了复杂交互场景的评估空白。目前已有30+高校实验室基于这些资源开展研究,加速MoE架构的技术创新。
加速垂直领域落地
在金融风控场景,模型通过256K上下文分析完整交易流水,欺诈识别准确率提升19%;在教育领域,其数学推理能力支持个性化解题辅导,某在线教育平台接入后用户答题正确率提高23%。腾讯云已推出HunyuanAPI服务,支持企业通过API快速集成,无需自建模型训练能力。
部署与应用:从下载到上线的全流程支持
快速部署指南
开发者可通过以下命令获取模型:
git clone https://gitcode.com/tencent_hunyuan/Hunyuan-A13B-Instruct-GPTQ-Int4.git
支持vLLM、SGLang等主流推理框架,官方提供的Docker镜像已预装所有依赖:
docker pull docker.cnb.cool/tencent/hunyuan/hunyuan-a13b:hunyuan-moe-A13B-vllm
典型应用场景
- 智能客服:启用快思考模式,单GPU支持每秒300+并发对话
- 法律分析:256K上下文一次性处理整份合同,关键条款识别准确率91%
- 代码助手:在LiveCodeBench测试中达到63.9分,支持多语言混合编程
- 科学计算:CMATH测试91.17分,可辅助解决大学物理和工程数学问题
未来展望:多模态融合与端侧部署
腾讯混元计划在2025年Q4推出多模态版本,融合文本、图像和3D建模能力。同时针对边缘设备优化的0.5B小尺寸模型已进入测试阶段,未来手机、智能终端也能运行Hunyuan核心能力。随着开源生态的完善,Hunyuan-A13B有望成为学术研究和商业应用的双重标杆,推动AI技术从"实验室"走向"生产线"。
对于开发者而言,现在正是接入这一高效能模型的最佳时机——无论是构建企业级AI应用,还是探索大模型前沿技术,Hunyuan-A13B都提供了"低门槛、高性能"的理想起点。随着量子计算等技术的发展,这种"智能激活"的设计理念或许将成为下一代AI系统的标配。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







