推荐开源项目:递归模型索引(RMI)
随着数据处理需求的日益增长,高效的索引结构变得至关重要。在这一背景下,我们发现了递归模型索引(Recursive Model Indexes,简称RMI)——一个源自深度学习与传统索引结构交汇点的创新解决方案。本文将全面解析RMI项目,探讨其技术内核,应用场景,并突出其独特优势。
项目介绍
递归模型索引是基于2017年Kraska等人发表的《对学习型索引结构的倡议》一文提出的一种参考实现。该项目以机器学习为驱动力,旨在优化数据查找效率。通过构建一个映射函数,RMI能够高效地在排序数据中定位信息,犹如一种智能的二叉搜索树增强版。
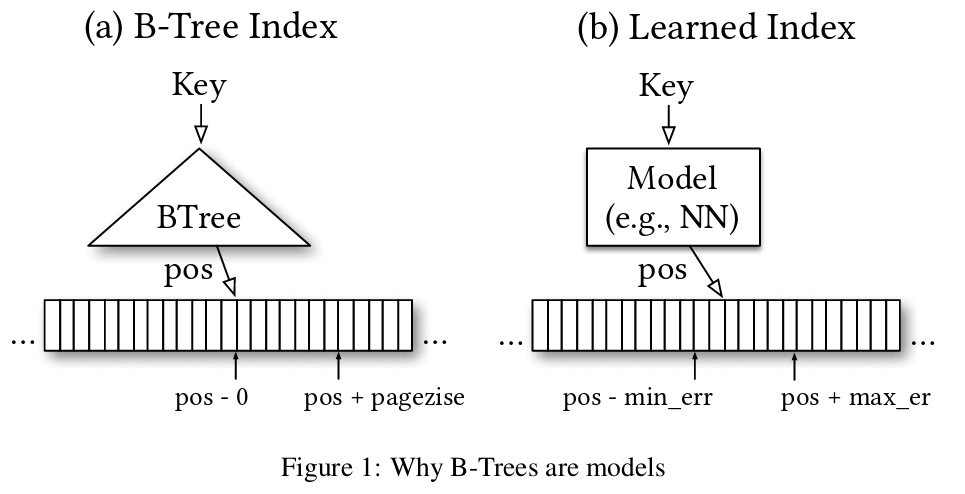
技术分析
不同于传统的B-Tree或基数树,RMI采用机器学习算法来构建数据键到索引位置的近似映射,这种方法通常生成的是轻量级且快速评估的数学模型。RMI的关键在于它的动态预测能力和紧凑的数据占用,虽然它需要预先训练并无法直接支持插入操作,但其在重复访问场景下的查询速度和存储效率展现出了显著优势。
应用场景
RMI特别适合大数据检索环境,如数据库系统、大规模日志分析、搜索引擎内部索引等,其中对于相同排序数据频繁查询的场景尤为有效。例如,在线服务中的缓存管理、大规模数据分析平台的列式存储优化中,RMI都能提供更快的访问速度和更小的内存占用。
项目特点
- 高速查寻: 经过适当调优,RMI能提供比传统索引快的查询时间。
- 体积小巧: 相较于传统结构,RMI占用的空间大幅减少,利于资源受限环境。
- 预训练模型: 需要提前针对特定数据集进行训练,这意味着首次部署时需要一定准备时间。
- 非动态更新: 一旦建立,不支持直接插入新数据,需重新训练。
如何使用RMI
本项目基于Rust编程语言,使用者需先安装Rust环境。RMI编译器接受特定格式的输入数据,生成可集成至C/C++应用的代码,大大简化了集成过程。此外,项目提供了灵活的层类型选择和优化工具,使开发者可以针对不同数据特性微调索引结构。
结语
递归模型索引(RMI)以其创新的架构,结合了机器学习的力量与索引设计的智慧,为现代大数据处理提供了全新的视角。无论是从性能提升还是空间优化的角度来看,RMI都是值得深入探索的技术宝藏。对于追求极致数据处理效率的开发者来说,掌握并应用RMI无疑是一条通往更高性能系统的捷径。立即拥抱RMI,让您的数据处理能力迈上新的台阶!
本篇文章介绍了RMI的基本概念、技术优势和应用场景,希望通过这些信息,您能够对RMI有更深的理解并考虑将其引入您的项目之中,享受技术带来的效能提升。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







