通义千问发布Qwen3-Next系列首款模型 80B参数实现超长上下文与高效推理双重突破
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Next-80B-A3B-Instruct
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Next-80B-A3B-Instruct Qwen3-Next-80B-A3B作为Qwen3-Next系列的开篇之作,在技术架构上实现了多项关键突破。该模型创新性地融合了混合注意力机制(Hybrid Attention)、高稀疏度专家混合(High-Sparsity Mixture-of-Experts, MoE)架构、稳定性优化策略以及多令牌预测(Multi-Token Prediction, MTP)技术,构建起兼顾性能与效率的新一代大语言模型基础。
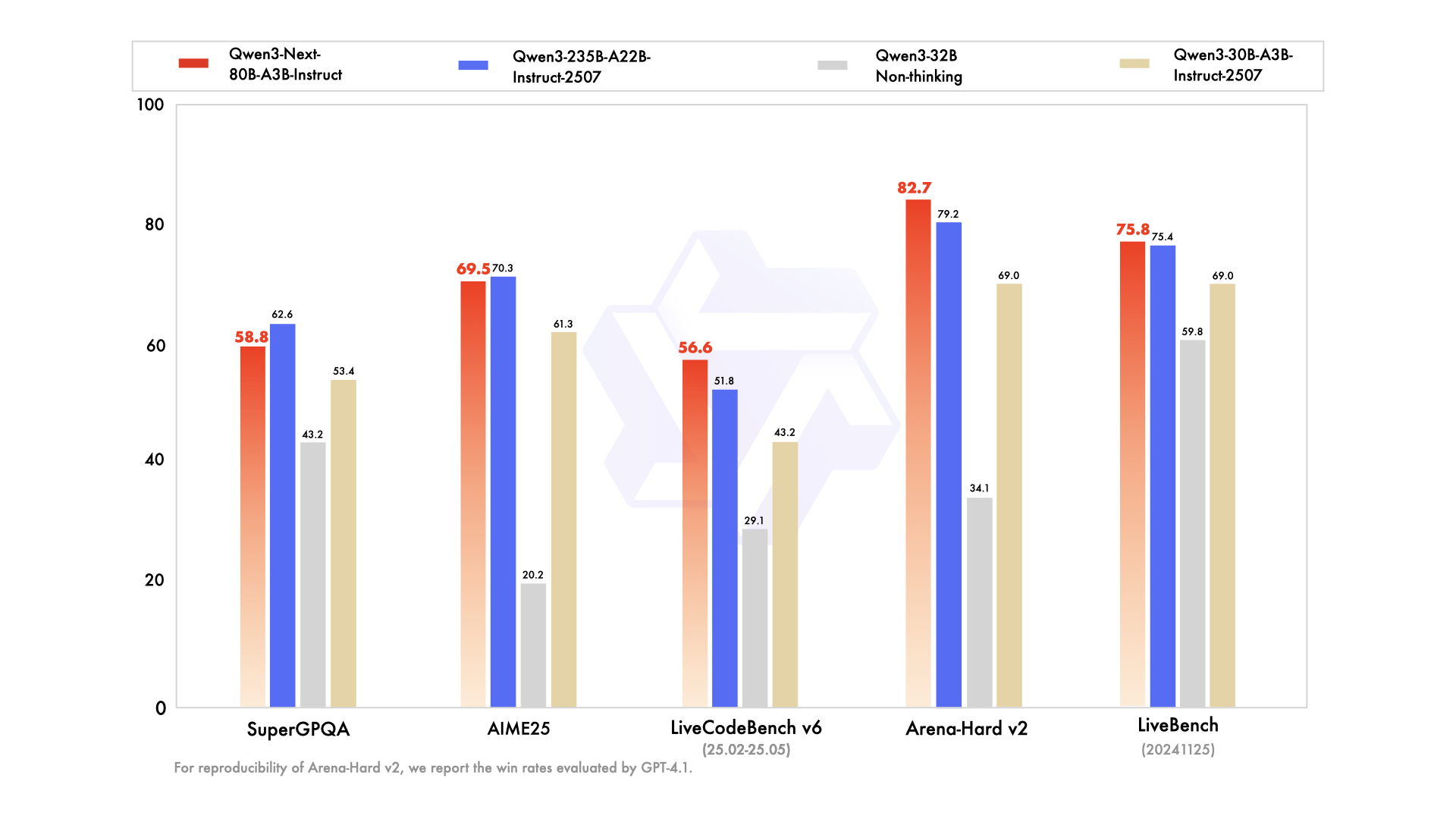 如上图所示,该基准测试对比图表直观呈现了Qwen3-Next-80B-A3B-Instruct与同系列高端模型的性能对照。这一测试结果充分验证了轻量化模型在保持核心能力的同时,在超长上下文任务中展现的独特优势,为开发者选择适配场景的模型提供了关键参考依据。
如上图所示,该基准测试对比图表直观呈现了Qwen3-Next-80B-A3B-Instruct与同系列高端模型的性能对照。这一测试结果充分验证了轻量化模型在保持核心能力的同时,在超长上下文任务中展现的独特优势,为开发者选择适配场景的模型提供了关键参考依据。
在上下文处理能力方面,Qwen3-Next-80B-A3B原生支持高达262,144 tokens的超长文本序列,通过YaRN扩展技术更可将上下文窗口进一步拓展至1,010,000 tokens级别,这一能力使其在处理完整书籍、代码库、多轮对话历史等复杂场景时表现出色。模型架构层面,研发团队创新性地将Gated DeltaNet与Gated Attention机制相结合,形成协同增效的上下文建模方案,有效提升了长序列信息的捕捉精度与处理效率。
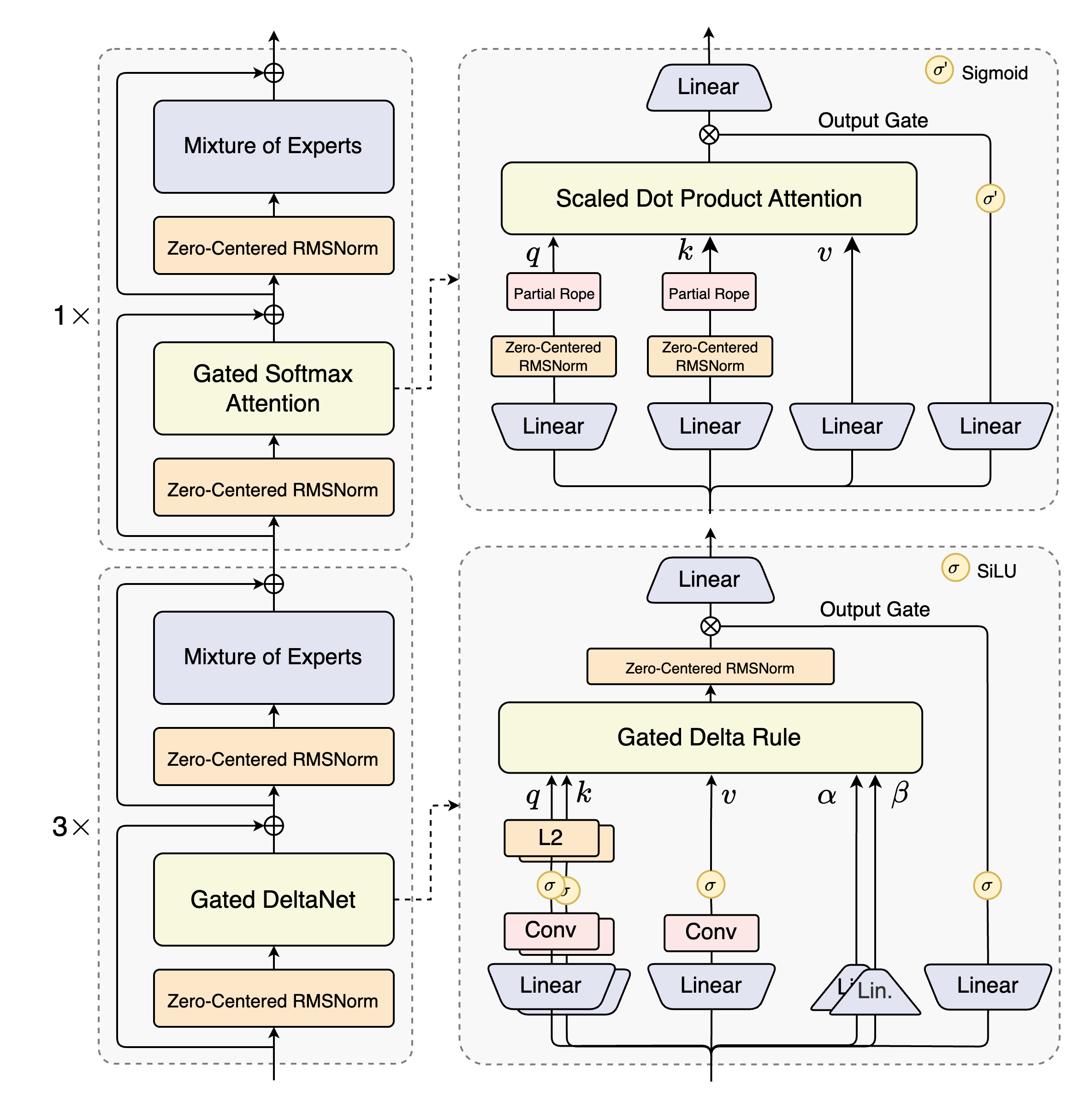 该架构图清晰展示了Qwen3-Next系列模型的核心技术组件与协同工作流程。图中呈现的模块化设计不仅保障了模型在超长上下文中的稳定运行,更为后续功能迭代与性能优化预留了扩展空间,帮助技术人员深入理解模型的底层工作原理。
该架构图清晰展示了Qwen3-Next系列模型的核心技术组件与协同工作流程。图中呈现的模块化设计不仅保障了模型在超长上下文中的稳定运行,更为后续功能迭代与性能优化预留了扩展空间,帮助技术人员深入理解模型的底层工作原理。
性能测试数据显示,Qwen3-Next-80B-A3B-Instruct版本在多项权威基准测试中达到了与Qwen3-235B-A22B-Instruct-2507相当的水平,尤其在需要深度上下文理解的任务中展现出显著优势。这一成果标志着大语言模型在"性能-效率"平衡上取得重要进展,为企业级应用部署提供了兼具算力经济性与任务适应性的新选择。随着该系列模型的持续迭代,预计将在多模态处理、领域知识增强等方向释放更大技术潜力。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







