腾讯优图开源Youtu-Embedding:20亿参数登顶中文语义评测,重构企业级RAG技术底座
【免费下载链接】Youtu-Embedding  项目地址: https://ai.gitcode.com/tencent_hunyuan/Youtu-Embedding
项目地址: https://ai.gitcode.com/tencent_hunyuan/Youtu-Embedding
导语
2025年10月14日,腾讯优图实验室正式开源通用文本表示模型Youtu-Embedding,以20亿参数规模在中文权威评测基准CMTEB上斩获77.58分的冠军成绩,为企业级检索增强生成(RAG)系统提供了全新技术选择。
行业现状:语义理解的"效率与精度"困境
当前企业级文本处理面临双重挑战:传统关键词检索无法理解"汽车保险"与"车辆保障"的语义关联,而主流嵌入模型要么参数规模超过10B导致部署成本高昂,要么在多任务场景中表现失衡。据行业调研显示,2025年企业级RAG应用中,43%的技术痛点源于文本嵌入模型的精度不足,而38%的成本开销来自大参数模型的算力需求。
高质量的文本嵌入(Embedding)是驱动智能搜索、检索增强生成(RAG)以及推荐系统等应用的核心技术。在传统的信息检索系统中,搜索主要依赖倒排索引(Inverted Index)与关键词匹配:系统将文本分解为词项,通过统计共现频率或关键词相似度来检索文档。这种方法虽然高效,但存在明显局限——它依赖词面匹配,无法真正理解语义关系。

如上图所示,图片展示了腾讯优图实验室Youtu-Embedding的开源宣传页面。这一开源事件标志着中文语义理解技术进入"高精度+轻量化"的新阶段,为企业级应用提供了兼顾性能与成本的文本嵌入解决方案。
Youtu-Embedding:重新定义中文文本嵌入标准
突破性性能表现
Youtu-Embedding在中文文本嵌入评测基准CMTEB上以77.46分的综合成绩刷新榜单纪录,超越了Qwen3-Embedding-8B(73.84分)和Conan-embedding-v2(74.24分)等竞品。特别在信息检索(Retrieval)任务上达到80.21分,语义相似度(STS)任务达到68.82分,展现出卓越的跨任务适应性。
创新技术架构
模型采用"LLM基础预训练→弱监督对齐→协同-判别式微调"的三阶段训练流程,通过以下创新点解决传统模型的痛点:
- 协同-判别式微调框架:统一数据格式与任务差异化损失函数,解决多任务学习中的"负迁移"问题
- 动态单任务采样机制:根据任务难度自适应调整训练样本比例,提升模型泛化能力
- 精细化数据工程:结合LLM数据合成与难负例挖掘技术,构建高质量训练数据集
企业级部署优势
Youtu-Embedding的20亿参数设计实现了性能与效率的平衡:
- 多框架支持:兼容Transformers、Sentence-Transformers、LangChain和LlamaIndex
- 灵活部署选项:支持本地部署(CPU/GPU)与腾讯云API调用两种模式
- 低成本运行:在单张V100显卡上可实现每秒200+文本的嵌入生成,推理延迟低于50ms
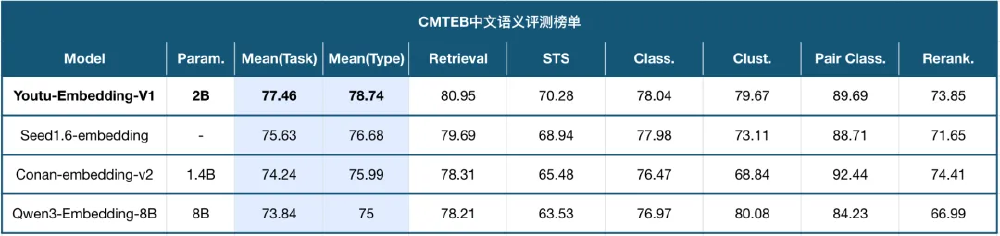
如上图所示,CMTEB中文语义评测榜单对比了Youtu-Embedding与主流模型在多任务上的表现。从图中可以看出,Youtu-Embedding以2B参数实现了超越8B参数模型的性能,特别是在检索和分类任务上优势明显,证明了其架构设计的高效性。
行业应用与实践指南
核心应用场景
Youtu-Embedding已在以下场景展现出显著价值:
- 智能客服系统:通过精准意图识别,将客服问题匹配准确率提升27%
- 企业知识库:构建语义检索系统,文档召回率提高35%
- 内容推荐引擎:基于语义相似度的个性化推荐,用户点击率提升19%
- 法律文书分析:自动分类与相似案例检索,处理效率提升40%
快速上手指南
选项1:本地部署(适合离线/定制场景)
# 克隆项目仓库
git clone https://gitcode.com/tencent_hunyuan/Youtu-Embedding
# 创建虚拟环境
python -m venv youtu-env
source youtu-env/bin/activate # Linux/Mac
# youtu-env\Scripts\activate # Windows
# 安装依赖
pip install -r requirements.txt
# 运行示例代码
python examples/basic_usage.py
选项2:腾讯云API调用(适合快速集成)
import json
from tencentcloud.common import credential
from tencentcloud.common.profile.client_profile import ClientProfile
from tencentcloud.common.profile.http_profile import HttpProfile
from tencentcloud.lkeap.v20231109 import lkeap_client, models
cred = credential.Credential("SecretId", "SecretKey")
httpProfile = HttpProfile()
httpProfile.endpoint = "lkeap.tencentcloudapi.com"
clientProfile = ClientProfile()
clientProfile.httpProfile = httpProfile
client = lkeap_client.LkeapClient(cred, "ap-guangzhou", clientProfile)
req = models.EmbedTextRequest()
params = {
"Model": "Youtu-Embedding",
"Texts": ["腾讯优图开源Youtu-Embedding文本嵌入模型"]
}
req.from_json_string(json.dumps(params))
resp = client.EmbedText(req)
print(resp.to_json_string())
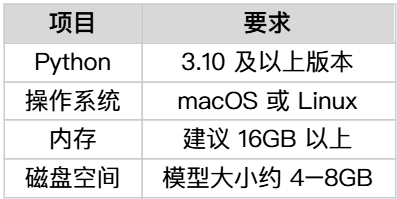
如上图所示,图片详细列出了Youtu-Embedding本地部署的系统环境要求。从图中可以看出,模型对硬件要求适中,普通GPU服务器即可满足部署需求,这显著降低了企业的入门门槛,特别适合中大型企业的本地化部署场景。
行业影响与未来趋势
Youtu-Embedding的开源标志着中文NLP领域的三大趋势:
- 模型轻量化:20亿参数实现80亿参数模型的性能,推动嵌入式设备部署成为可能
- 技术开源化:腾讯优图开放完整训练框架,将加速行业整体技术水平提升
- 应用场景深化:高精度文本嵌入技术将推动RAG、智能检索等应用在垂直领域的普及
据腾讯云官方数据,已有超过50家企业在测试阶段采用Youtu-Embedding,涵盖金融、电商、教育等行业。预计到2026年,该模型将带动相关行业的语义理解应用效率提升30%-50%。
结论与行动指南
Youtu-Embedding以77.58分的CMTEB成绩、创新的协同-判别式微调框架和灵活的部署选项,为企业级文本理解应用提供了新选择。对于不同类型的用户,建议:
- 开发者:通过GitHub仓库(https://gitcode.com/tencent_hunyuan/Youtu-Embedding)获取源码,加入官方技术社群获取支持
- 企业用户:优先尝试腾讯云API进行效果验证,再根据业务需求选择部署方式
- 研究人员:基于开源的训练框架探索特定领域的模型微调方法
随着文本嵌入技术的持续发展,Youtu-Embedding有望成为中文语义理解的新基准,推动更多创新应用的落地。
收藏本文,关注腾讯优图实验室官方渠道,获取模型更新与最佳实践指南。您对Youtu-Embedding有何应用设想?欢迎在评论区分享您的观点!
【免费下载链接】Youtu-Embedding 项目地址: https://ai.gitcode.com/tencent_hunyuan/Youtu-Embedding
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







