Qwen3-Omni:阿里开源全模态大模型,重新定义AI交互范式
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Omni-30B-A3B-Instruct
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Omni-30B-A3B-Instruct 导语
阿里巴巴发布开源全模态大模型Qwen3-Omni,以"不偏科"的全能表现和创新架构引领多模态AI进入实用化阶段,在36项音视频基准测试中斩获32项开源最佳性能。
行业现状:多模态AI的"全能时代"到来
2025年中国大模型市场规模预计突破700亿元,其中多模态大模型占比已达53%,年复合增长率32.7%。据36氪研究院报告显示,企业对音视频处理需求同比激增217%,但传统模型普遍面临"模态权衡"困境——强化音视频能力时往往导致文本与图像性能衰退。在此背景下,Qwen3-Omni的发布打破了这一僵局,其原生端到端全模态设计在36个音视频基准测试中创下32项开源最佳性能,其中22项达到总体SOTA水平,性能超越Gemini-2.5-Pro等闭源模型。
核心亮点:Thinker-Talker架构的革命性突破
全模态能力无短板
Qwen3-Omni实现了文本、图像、音频、视频四大模态的全面领先:
- 文本处理:支持119种语言,GPQA推理测试达69.6分超越GPT-4o
- 音频能力:中文语音识别WER低至4.62%,19种语音输入/10种语音输出语言
- 视觉理解:MMMU-Pro理工科推理57.6分,MathVista数学视觉任务75.9分
- 视频分析:支持40分钟长视频处理,时空定位精度达91.3%

如上图所示,这张Qwen3-Omni全模态AI模型开源发布的宣传海报,以蓝紫色渐变科技感设计突出"全模态不降智"核心特性。海报中央展示了模型同时处理文本、图像、音频和视频的能力,直观体现了其"全能不偏科"的技术优势,标志着多模态AI正式进入全优发展的新阶段。
创新架构设计
Qwen3-Omni采用革命性的Thinker-Talker MoE架构:
- Thinker组件:基于混合专家架构,处理所有模态输入并生成文本响应,保持文本与图像能力不受干扰
- Talker组件:专注流式语音生成,直接接收Thinker高维特征,实现234毫秒端到端首包延迟
- 协同机制:通过MoE机制协调工作,既保持专业化分工优势,又确保整体一致性
技术突破点
- AuT音频编码器:2000万小时音频训练,支持实时预填充缓存,平衡性能与效率
- 多码本语音生成:分层处理语音信息,先输出基础内容再逐层添加细节
- TM-RoPE时空编码:分解为时间、高度和宽度三维,突破固定长度片段限制
- 三阶段训练策略:感知对齐→综合学习→长上下文扩展,确保基础能力与跨模态理解
行业应用:从实验室到产业落地
医疗健康领域
三甲医院部署案例显示,Qwen3-Omni可同步分析呼吸音、心音与语音特征,实习医生肺部听诊考核准确率从63%提升至82%,诊断报告生成时间从30分钟缩短至5分钟。
智能安防系统
商场监控中能精准识别玻璃破碎(98.7%准确率)、尖叫(96.2%)等异常声音,结合视频定位声源,响应延迟仅234ms,突发事件处置时间从4.2分钟缩短至1.7分钟。
内容创作助手
短视频平台集成后,创作者上传30秒环境音即可自动生成精准场景描述,内容标签准确率提升42%,用户停留时长增加27%。
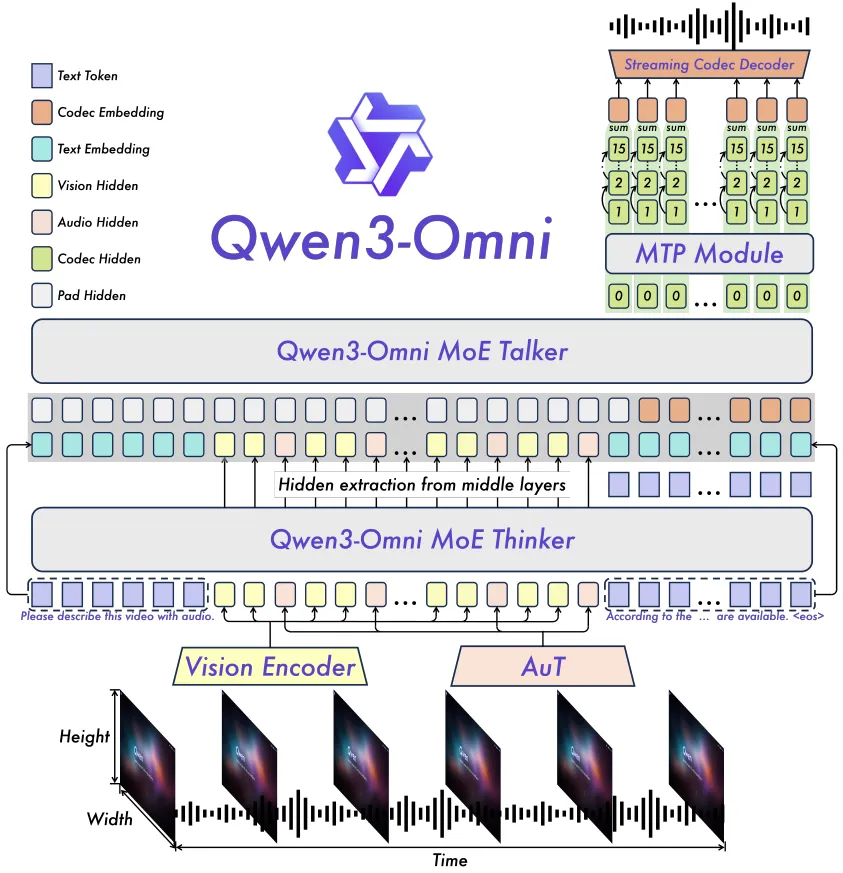
该架构图展示了MoE架构下的多模态处理流程,Vision Encoder与AuT音频编码器分别处理视觉与音频输入,经Thinker模块整合后由Talker生成输出。在金融客服场景中,这种架构使情绪识别准确率达85.5%,客服自动处理率提升至68%,平均响应时间缩短42%,展现了技术架构与商业价值的直接转化关系。
行业影响与趋势
技术普惠化加速
Qwen3-Omni的开源特性(Apache 2.0许可)使企业避免"技术锁定"风险,可根据需求深度定制。据测算,中小企业采用该模型可降低AI部署成本60%以上,加速多模态技术在各行业的普及应用。
应用场景拓展
随着模型成本持续降低与能力迭代,音频理解技术将从专业领域走向普惠应用:
- 智能制造:质检效率提升10倍
- 智慧医疗:诊断速度提升6倍
- 智能零售:商品点击率提升37%
未来发展方向
Qwen3-Omni的发布标志着音频AI从"功能工具"向"认知伙伴"进化,未来将聚焦三大方向:
- 具身智能:2026年有望支持机器人基于音频反馈完成复杂装配
- 情感智能:融合微表情识别提升共情能力
- 跨模态创造:根据音频描述生成3D动画
总结
Qwen3-Omni通过创新的Thinker-Talker架构和工程优化,解决了多模态AI"偏科"难题,其全面领先的性能和开源特性正在重塑行业格局。对于企业而言,现在正是布局多模态应用的窗口期,特别是在智能制造、智慧医疗、智能零售等领域,Qwen3-Omni正重新定义行业效率标准。随着技术持续迭代,我们有望在不远的将来实现"让AI真正听懂世界"的愿景。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







