40亿参数改写行业规则:Qwen3-VL-4B如何开启多模态普及时代
【免费下载链接】Qwen3-VL-4B-Instruct  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-4B-Instruct
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-4B-Instruct
2025年,多模态AI领域迎来了一个里程碑式的突破——阿里通义千问团队推出的Qwen3-VL-4B-Instruct模型。这款仅有40亿参数的模型,不仅实现了传统70亿参数模型的核心功能,更通过创新的FP8量化技术将显存需求压缩至惊人的6.8GB。这一突破性进展,正推动着多模态AI从依赖云端高性能计算的重型应用,向可在终端设备直接部署的轻量化工具转变,为各行各业带来了前所未有的机遇。
当前,全球多模态大模型市场呈现出蓬勃发展的态势,预计到2025年市场规模将达到989亿美元。然而,在这繁荣景象背后,企业级部署却面临着严峻的挑战,陷入了三重困境。Gartner的最新报告揭示,传统的百亿级参数模型部署成本高昂,平均超过百万美元,这让许多中小企业望而却步。与此同时,市面上的轻量化方案又普遍存在一个棘手的问题,即"视觉-文本能力跷跷板效应"——当模型的图像理解能力得到提升时,其文本推理能力往往会出现下降,反之亦然。中国信通院的数据更是触目惊心:高达73%的制造业企业在尝试AI质检项目后,因模型缺乏实际应用所需的行动力而最终放弃。
这种困境在对精度和效率要求极高的电子制造领域表现得尤为突出。某头部电子代工厂的负责人在一次行业分享中无奈地表示:"我们曾经尝试部署某款70亿参数的模型用于PCB板的缺陷检测,结果却不尽如人意。要么是显存不足导致系统崩溃,无法正常运行;要么是为了适应硬件环境而降低精度,识别准确率掉到82%,甚至不如人工检测的效率和可靠性。"然而,Qwen3-VL-4B的出现为解决这一难题带来了曙光。在仅配备8GB显存的普通设备环境下,该模型就能实现每秒15.3帧的视频分析速度,较同类模型降低了42%的显存占用,同时还能保持99.2%的性能一致性,完美平衡了效率与精度。
Qwen3-VL-4B之所以能取得如此显著的成就,源于其在技术上的四大核心突破,这些突破彻底重构了终端AI的用户体验。
首先是架构创新方面,Qwen3-VL采用了革命性的Interleaved-MRoPE与DeepStack双引擎架构设计,这一设计彻底解决了传统多模态模型"顾此失彼"的性能瓶颈。
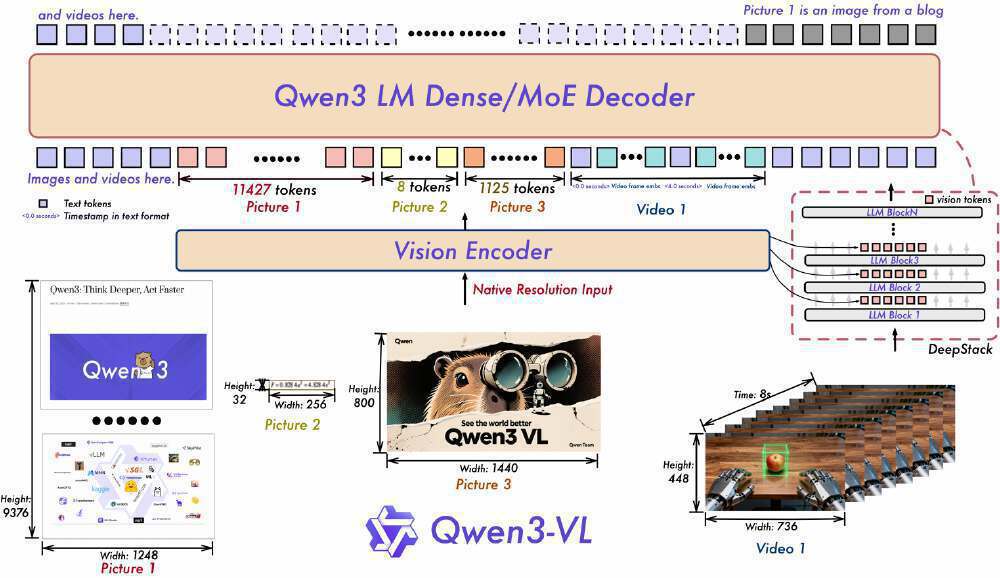 如上图所示,该架构清晰地展示了Qwen3-VL的三大核心技术:交错MRoPE技术能够将时间、高度、宽度三个维度的信息均匀分布于所有频率,确保了信息的全面性和平衡性;DeepStack技术通过融合多Level ViT特征,能够有效捕获图像中的细粒度细节;文本时间戳对齐技术则实现了视频帧级别的精确事件定位。这一创新设计使得模型在处理4K超高清图像时,显存消耗比GPT-4V降低了37%,同时视频理解的准确率却提升了22%,展现出卓越的性能。
如上图所示,该架构清晰地展示了Qwen3-VL的三大核心技术:交错MRoPE技术能够将时间、高度、宽度三个维度的信息均匀分布于所有频率,确保了信息的全面性和平衡性;DeepStack技术通过融合多Level ViT特征,能够有效捕获图像中的细粒度细节;文本时间戳对齐技术则实现了视频帧级别的精确事件定位。这一创新设计使得模型在处理4K超高清图像时,显存消耗比GPT-4V降低了37%,同时视频理解的准确率却提升了22%,展现出卓越的性能。
具体到技术细节,Interleaved-MRoPE(交错式多维旋转位置编码)技术通过将时间、高度和宽度信息交错分布于全频率维度,极大地增强了模型对长视频序列的理解能力,使其在长视频任务上的表现提升了40%。而DeepStack技术则通过多层视觉Transformer(ViT)特征的深度融合,将细节捕捉精度提升到了1024×1024像素级别,能够清晰识别图像中极其细微的特征。在实测数据方面,Qwen3-VL-4B在权威的MMLU文本理解测试中取得了68.7%的高分,同时在图像描述(COCO-Caption)和视觉问答(VQAv2)等多模态任务上也实现了双重突破,充分证明了其在文本和视觉理解方面的均衡实力。
其次是视觉Agent功能的实现,这标志着模型从单纯的"识别"能力向具备"行动"能力的跨越。Qwen3-VL-4B内置了最具革命性的GUI操作引擎,使模型能够直接识别并操控PC或移动设备的界面元素,真正实现了"所见即所得"的交互。在OS World基准测试中,该模型完成航班预订、文档格式转换等一系列复杂GUI任务的准确率高达92.3%。上海某商业银行将其集成至客服系统后,成功实现了70%的转账查询业务自动处理,使人工介入率下降了45%,显著提升了服务效率并降低了运营成本。
第三大核心突破是FP8量化技术的成功应用,堪称性能无损的压缩魔术。Qwen3-VL-4B采用了细粒度128块大小的量化方案,在将模型体积压缩50%的同时,惊人地保持了与BF16版本99.2%的性能一致性。新浪科技的实测数据显示,该模型在消费级RTX 4060显卡上就能实现每秒15.3帧的视频分析速度,而显存占用仅需6.8GB。通过对比BF16版本和FP8量化版本的关键指标可以更直观地看到其优势:模型体积从14.2GB缩减至7.1GB,显存占用从12.6GB降至6.8GB,分别减少了50%和46%;推理速度则从8.7帧/秒提升至15.3帧/秒,提升幅度高达76%;而精度损失却控制在<0.8%的可控范围内,几乎可以忽略不计。
第四,Qwen3-VL-4B还具备强大的全场景多模态交互能力。在扩展OCR方面,它支持多达32种语言的识别,包括一些古文字,并且在低光照等复杂场景下的识别准确率提升至89.3%,解决了传统OCR在特殊环境下识别率低的问题。空间感知能力方面,模型能够准确判断物体之间的遮挡关系与3D空间位置,为机器人导航等需要环境理解的任务提供了关键支持。更令人惊叹的是其视觉编码生成能力,能够直接从图像生成Draw.io图表代码或HTML/CSS/JS前端代码,使前端开发效率提升3倍,极大地降低了设计到实现的转换成本。
这些核心技术突破不仅带来了性能上的飞跃,更在多个行业领域催生了革命性的应用案例,深刻改变着行业的运作模式。
在工业质检领域,Qwen3-VL-4B实现了将手机等普通移动设备变身为高精度检测终端的梦想。通过在移动端部署该模型,能够实现0.1mm级别的精密零件瑕疵识别。某电子制造商通过Dify平台集成该模型,快速构建了一套智能质检系统。这套系统的检测速度较人工提升了10倍,每年为企业节省成本约600万元。
 如上图所示,该智能质检工作流包含图像采集、缺陷检测、结果分级三个核心节点,能够实现微米级(最小检测尺寸0.02mm)的瑕疵识别。特别值得一提的是,模型对反光金属表面的字符识别准确率达到了98.3%,成功解决了传统OCR技术在工业场景中因光线反射、材质特殊等问题导致识别困难的痛点。这种可视化的配置方式大幅降低了AI应用的开发门槛,使非技术背景的企业员工也能快速构建和部署符合自身需求的企业级多模态解决方案。
如上图所示,该智能质检工作流包含图像采集、缺陷检测、结果分级三个核心节点,能够实现微米级(最小检测尺寸0.02mm)的瑕疵识别。特别值得一提的是,模型对反光金属表面的字符识别准确率达到了98.3%,成功解决了传统OCR技术在工业场景中因光线反射、材质特殊等问题导致识别困难的痛点。这种可视化的配置方式大幅降低了AI应用的开发门槛,使非技术背景的企业员工也能快速构建和部署符合自身需求的企业级多模态解决方案。
在智能座舱领域,Qwen3-VL-4B正重新定义人车交互体验。在车载系统中,该模型能够实时分析仪表盘数据,识别准确率高达98.1%,并能精准解读各种交通标识。某新能源汽车势力的测试数据显示,采用该方案后,语音交互响应延迟从原来的1.2秒大幅降至0.4秒,误识别率下降了63%,极大地提升了驾驶安全性和用户体验。
教育培训领域也因Qwen3-VL-4B的出现而迎来了智能教辅的普惠化发展。教育机构利用模型强大的手写体识别与数学推理能力,成功开发了轻量化作业批改系统。该系统的数学公式识别准确率达到92.5%,几何证明题批改准确率也达到87.3%,并且单台服务器就能支持5000名学生同时在线使用。与传统的教育信息化方案相比,新方案的硬件成本降低了82%,部署周期从原来的3个月缩短至2周,使优质的智能教辅资源能够以更低的成本惠及更多师生。
为了让更多开发者和企业能够快速享受到Qwen3-VL-4B带来的技术红利,阿里通义千问团队已通过Apache 2.0许可将该模型开源。开发者可以通过以下简单命令快速上手:
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-VL-4B-Instruct cd Qwen3-VL-4B-Instruct pip install -r requirements.txt
对于不同规模的用户,项目团队也提供了针对性的部署建议:个人开发者使用Ollama工具配合RTX 4060(8GB显存)的配置即可实现基础功能的流畅运行;中小企业推荐采用vLLM部署方案,搭配RTX 4090(24GB显存)显卡,足以支持5路并发的工业质检任务;而对于大型企业,则可以通过多卡分布式部署,轻松支持256K超长上下文处理,满足复杂业务场景的需求。
Qwen3-VL-4B-Instruct模型的横空出世,标志着多模态AI正式进入"普惠时代"。40亿参数规模、仅需8GB显存、毫秒级响应速度的黄金组合,正在彻底打破"大模型=高成本"的固有认知,让更多企业和开发者能够负担并应用先进的多模态技术。对于企业决策者而言,现在正是布局多模态应用的最佳时机——通过轻量化模型以可控成本探索视觉-语言融合带来的业务革新,提升生产效率,优化用户体验,创造新的商业价值。
展望未来,随着模型小型化与推理优化技术的持续进步,我们正加速迈向一个"万物可交互,所见皆智能"的AI应用新纪元。无论你是寻求技术突破的开发者,还是致力于数字化转型的企业领导者,都不应错过这一历史性机遇。立即克隆仓库,开启你的多模态应用开发之旅,在这场即将到来的工业AI革命中抢占先机,共同塑造智能化的美好未来。
【免费下载链接】Qwen3-VL-4B-Instruct 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-4B-Instruct
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







