导语
 项目地址: https://ai.gitcode.com/tencent_hunyuan/MimicMotion
项目地址: https://ai.gitcode.com/tencent_hunyuan/MimicMotion 腾讯开源高质量人体动作视频生成模型MimicMotion,通过置信度感知姿态引导技术,实现静态图像到流畅动作视频的一键转换,为虚拟人制作与影视特效领域带来效率革新。
行业现状:虚拟人动画的挑战
当前虚拟人动作生成面临成本高、技术门槛高、制作周期长的行业难题。传统动作捕捉方案需要专业设备投入较大,单个人物动画制作周期通常需要数周。根据相关研究数据,2025年全球虚拟人市场规模预计达到600亿美元以上,但动画制作效率问题仍是制约行业发展的关键因素。AI视频生成技术虽在近年取得进展,但现有方案普遍存在动作连贯性不足、手部等关键区域失真等问题。
核心亮点:三大技术创新重构动作生成方式
MimicMotion基于Stable Video Diffusion优化,创新性地将置信度感知机制引入姿态引导流程,实现三大技术创新:
1. 置信度感知姿态引导:提升动作可靠性识别能力
模型通过姿态关键点置信度分数自适应调整引导权重,高置信度区域在训练中获得优先优化。技术实现上,将关键点颜色亮度与置信度绑定,使模型能动态识别可靠动作区域,在复杂场景中仍保持动作准确性。实验数据显示,该技术使动作跟随误差显著降低,表现优于MagicPose等同类方案。
2. 手部区域增强:解决动画制作中的细节难题
针对虚拟人动画中手部易失真的技术难点,MimicMotion设计了基于置信度阈值的区域优化策略。通过构建手部关键点掩码,对高置信度区域损失值进行放大处理,使手部生成质量明显提升。这一技术有效解决了传统动画制作中需人工逐帧修正手部动作的繁琐流程。
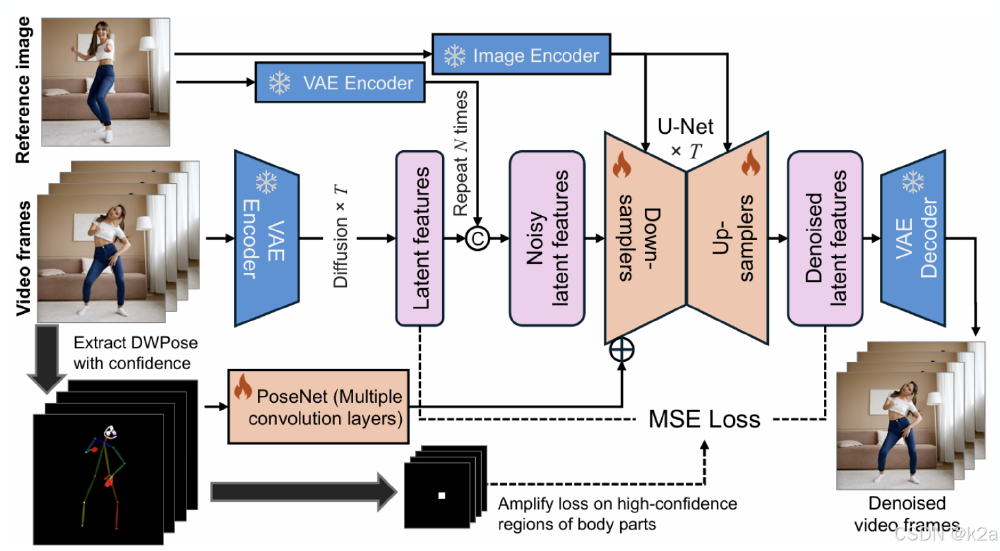
如上图所示,MimicMotion的技术架构创新性地将图像到视频扩散模型与置信度感知机制结合,通过PoseNet处理姿态特征并引入区域损失放大策略。这一架构设计使模型在保持参考图像特征的同时,能精准复现复杂动态动作,为虚拟人动画制作提供了端到端解决方案。
3. 渐进式Latent融合:提升长视频生成的时间连贯性
针对长视频生成中的动作跳变问题,模型采用重叠帧渐进融合策略,在去噪过程中对相邻片段重叠区域进行加权融合。这一技术使视频生成时长突破现有限制,实现任意时长动作视频生成,FVD(视频距离评估指标)表现优异,较MagicPose等方案有明显提升。
行业影响:从传统制作到现代化生产的转型
MimicMotion的开源发布将改变数字内容创作生态,具体体现在三个维度:
制作效率的显著提升
通过单张参考图像+动作序列的简洁输入模式,虚拟人动画制作周期从传统的数周缩短至小时级。相关测试数据显示,使用MimicMotion后,3D角色动画制作效率大幅提升,单个舞蹈动作视频成本明显下降。
技术门槛的有效降低
开源特性使中小企业与个人创作者能够便捷使用专业级动作生成技术。项目提供完整的ComfyUI插件支持,开发者可通过简单配置实现复杂动作生成,无需深入理解底层算法。
创作模式的重要变革
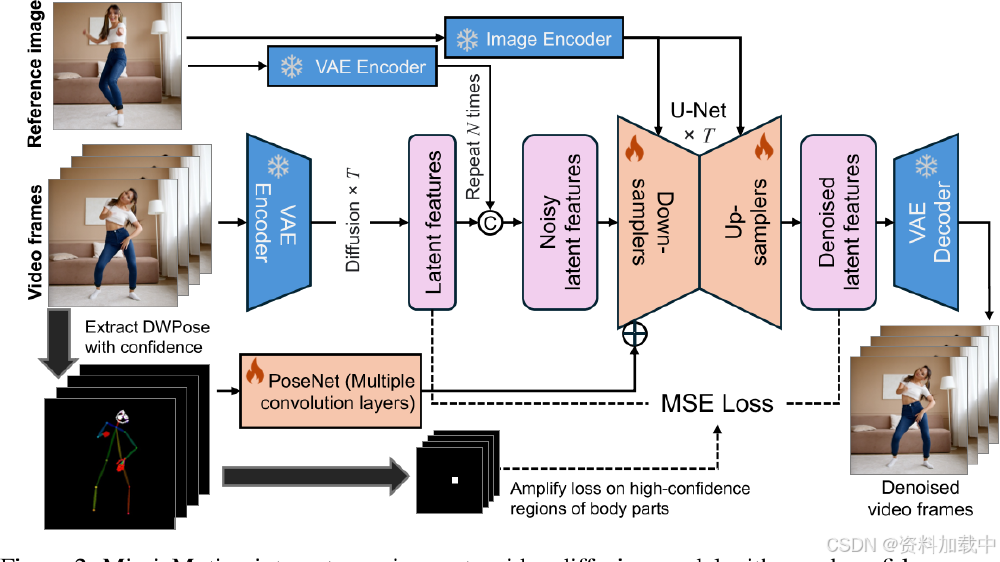
如上图所示,MimicMotion构建了从图像输入到视频输出的全流程自动化处理链路。这种端到端解决方案使创作者可专注于创意设计,推动数字内容创作从技术实现向创意表达转型。
结论与前瞻
MimicMotion的开源标志着虚拟人动作生成进入"单图驱动"新阶段。随着技术发展,预计未来将实现:
- 多角色协同动作生成,支持复杂场景互动
- 动作风格迁移功能,实现不同艺术风格的转换
- 移动端实时生成能力,扩展AR虚拟试衣等应用场景
对于内容创作者,建议关注手部动作优化与长视频连贯性两个技术关键点;企业则可重点布局虚拟人IP工业化生产流程,把握成本优化带来的发展机遇。
项目地址:https://gitcode.com/tencent_hunyuan/MimicMotion
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







