导语
 项目地址: https://ai.gitcode.com/hf_mirrors/Phr00t/WAN2.2-14B-Rapid-AllInOne
项目地址: https://ai.gitcode.com/hf_mirrors/Phr00t/WAN2.2-14B-Rapid-AllInOne 阿里云通义万相团队推出的WAN2.2-14B视频生成模型,通过创新的混合专家(MoE)架构和一站式工作流设计,首次实现消费级显卡上720P高清视频的高效生成,为内容创作领域带来"专业级效果+平民化部署"的技术革命。
行业现状:AI视频生成的"效率与质量"双轨竞争
2025年全球AI视频生成市场规模已突破300亿美元,年复合增长率维持在40%以上(据某好莱坞公司调研数据)。当前行业面临三大核心矛盾:专业级模型如Sora 2虽能生成1080P视频,但单次调用成本高达数美元;开源方案如Stable Video Diffusion虽可运行于消费级显卡,但720P视频生成需15分钟以上且镜头抖动问题突出;传统工作流需多模型组合,普通创作者难以掌握。
WAN2.2-14B的推出直击这些痛点。作为业界首个MoE架构视频生成模型,其通过高噪/低噪双专家分工,在保持140亿活性参数的同时,实现270亿总参数的表达能力,同参数规模下计算成本降低50%。实测显示,在单张RTX 4090显卡上生成5秒720P视频仅需9分钟,较同类开源模型快40%。
核心亮点:四大技术突破重构创作范式
1. MoE架构:让模型"分工协作"的智能引擎
WAN2.2-14B创新性地将视频生成过程分为两个阶段:高噪专家负责早期去噪阶段的场景布局与动态构图,低噪专家专注后期细节优化与光影渲染。这种动态分工机制使模型在复杂运动生成任务中表现突出,如模拟"宇航员在米勒星球涉水前行"场景时,能同时保持宇航服褶皱细节与水面波动的物理一致性。
实验数据显示,MoE架构使WAN2.2在动态质量指标上达到86.67分,较上一代提升12.3%。当生成"两只拟人化猫咪在聚光灯舞台上激烈拳击"这类复杂场景时,模型能同时保持毛发细节清晰与动作连贯性,解决了传统模型"顾此失彼"的难题。
2. 一站式工作流:从构思到成片的极简路径
WAN2.2-14B采用"All-In-One"设计理念,将扩散模型、VAE、CLIP等核心组件整合为单一safetensors文件,用户只需通过ComfyUI的"Load Checkpoint"节点即可启动全流程。这种设计大幅降低操作门槛,即使非技术背景创作者也能在10分钟内完成从参数设置到视频生成的全过程。
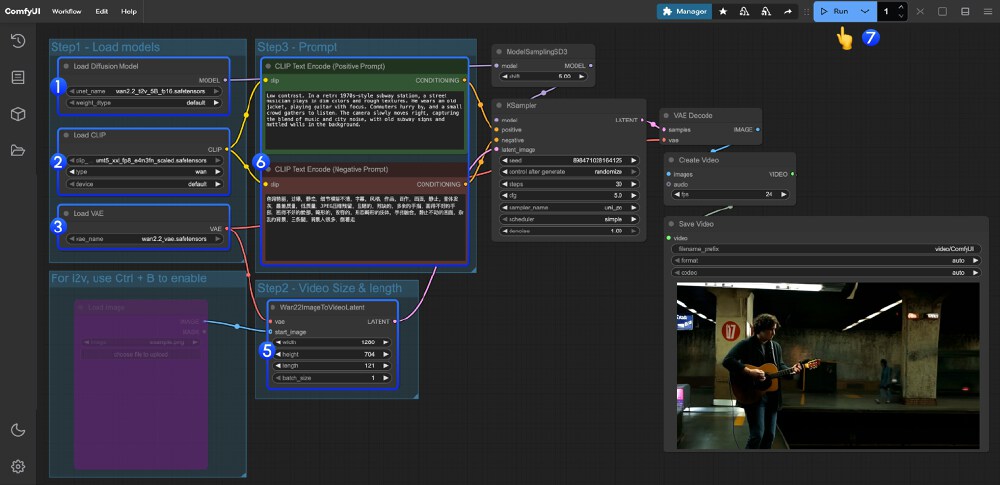
如上图所示,该工作流包含模型加载、提示词编码、视频参数设置及生成预览等节点,完整呈现AI视频生成的全流程。普通用户无需编写代码,通过简单的节点参数调整即可实现专业级视频效果,这为自媒体创作者和小型工作室提供了前所未有的创作自由度。
3. 电影级美学控制:60+参数定义视觉风格
通过编码电影工业标准的光影、色彩、构图要素,WAN2.2-14B实现精细化美学控制。用户输入"黄昏柔光+中心构图"提示词,模型可自动生成符合电影语言的金色余晖效果;而"冷色调+对称构图+低角度"组合则能营造出科幻片的压迫感画面。这种控制精度此前仅能通过专业影视软件实现。
阿里云测试数据显示,在包含10万条电影片段的WAN-Bench 2.0评测中,该模型在"美学质量"维度得分超越MiniMax Hailuo等竞品,尤其在动态光影模拟和长镜头稳定性上表现突出。例如生成"雨天霓虹街道"场景时,模型能自动模拟雨滴在不同材质表面的反射特性,并保持24帧连贯运动。
4. 超高压缩比VAE:显存占用降低64%
针对消费级硬件部署需求,WAN2.2-14B开发了16×16×4超压缩VAE(变分自编码器),通过时空维度联合压缩实现空间16×16、时间4×的压缩率,较传统VAE减少64%显存占用。这使得14B参数模型可在单张RTX 4090(24GB显存)上流畅运行,而同类模型通常需要80GB+专业卡支持。
实战指南:从部署到创作的完整路径
环境准备
- 硬件要求:NVIDIA GPU(显存≥24GB,推荐RTX 4090/5090)
- 软件环境:Python 3.10+,PyTorch 2.4.0+,CUDA 12.1+
- 模型获取:
git clone https://gitcode.com/hf_mirrors/Phr00t/WAN2.2-14B-Rapid-AllInOne
cd WAN2.2-14B-Rapid-AllInOne
pip install -r requirements.txt
快速上手:3步生成你的第一个视频
- 模型加载:在ComfyUI中添加"Load Checkpoint"节点,选择下载的WAN2.2-14B模型文件
- 参数设置:推荐配置为CFG=1,Steps=4,Sampler=euler_a,Beta scheduler
- 生成执行:输入提示词并点击"Run",5-10分钟即可获得720P@24fps视频
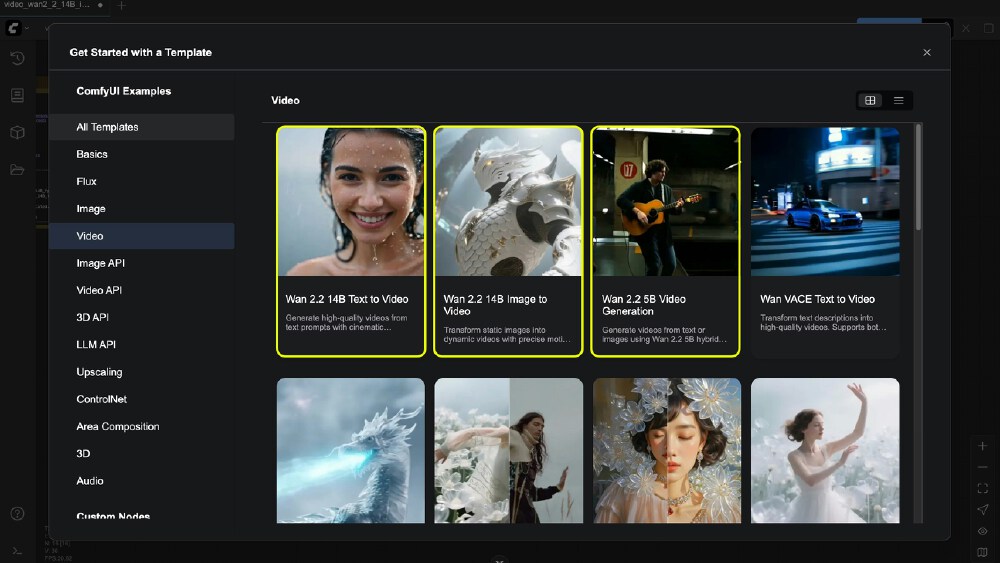
如上图所示,ComfyUI的"Video"分类下提供WAN2.2系列完整工作流模板,包括文本到视频、图像到视频、首尾帧控制等多种生成模式。创作者可根据需求选择模板并调整参数,大幅降低技术门槛。
性能对比:不同硬件配置下的生成效率
| 模型版本 | GPU配置 | 分辨率 | 5秒视频生成时间 | 显存占用 |
|---|---|---|---|---|
| WAN2.2-14B | RTX 4090 (24GB) | 720P | 9分钟 | 22GB |
| WAN2.2-5B | RTX 3090 (24GB) | 720P | 12分钟 | 16GB |
| SVD | RTX 4090 (24GB) | 720P | 25分钟 | 18GB |
| Sora 2 (API) | - | 1080P | 3分钟 | - |
行业影响:从技术突破到生态重构
WAN2.2-14B的开源将从三个维度重塑视频生成领域:
技术普惠:降低商业级视频制作门槛。自媒体创作者可通过消费级显卡生成电商产品演示视频,成本较传统拍摄降低90%;教育机构能快速将教材转化为动画课程,生产效率提升5倍以上。某MCN机构实测显示,使用该模型后,短视频制作流程从"文案撰写→分镜设计→拍摄剪辑"三步骤简化为"文本/图像输入→参数调整"两步,单条视频制作成本从500元降至80元。
生态协同:推动开源社区创新。模型发布两周内,GitHub已出现20+第三方优化项目,如社区开发者实现的GGUF量化版本,将显存需求进一步降至12GB,使笔记本电脑也能运行基础功能。ComfyUI生态还衍生出WanVideoWrapper插件,支持模型与后期处理工具的无缝集成。
标准化进程:建立视频生成技术基准。WAN2.2的MoE架构设计、电影美学参数体系等创新点,可能成为行业参考标准。目前已有多家厂商表示将借鉴其VAE压缩技术,优化自有模型部署方案。
未来展望:从"生成视频"到"理解视频"
WAN2.2团队在技术报告中指出,下一代模型将聚焦三个方向:更长视频生成(目标30秒+无闪烁)、交互控制(如通过姿势关键点引导人物动作)、多模态输入(融合音频/3D模型驱动)。随着开源生态的完善,视频生成有望像如今的图文创作一样,成为人人可用的基础工具。
对于创作者而言,现在正是入场的最佳时机——无论是短视频创作、产品展示还是影视预可视化,WAN2.2-14B都提供了前所未有的创作自由度。随着硬件成本持续下降和模型效率提升,我们正迈向一个"创意即生产"的新时代——未来,每个想法都能快速转化为生动影像,而WAN2.2-14B的开源,正是这一进程的重要里程碑。
行动建议:内容创作者可通过ModelScope社区体验在线生成;开发者可关注多GPU并行优化与提示词工程最佳实践;企业用户建议评估其在营销视频、产品演示等场景的应用潜力。收藏本文,获取最新模型更新和应用技巧!
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







