2025 OCR新范式:Nanonets-OCR-s让文档处理效率提升10倍的秘密武器
【免费下载链接】Nanonets-OCR-s  项目地址: https://ai.gitcode.com/hf_mirrors/nanonets/Nanonets-OCR-s
项目地址: https://ai.gitcode.com/hf_mirrors/nanonets/Nanonets-OCR-s
导语
Nanonets在2025年6月发布的Nanonets-OCR-s模型,通过视觉语言模型(VLM)技术突破传统OCR局限,将文档转换为结构化Markdown格式,为学术、法律、金融等行业带来显著效率提升。
行业现状:OCR市场迎来结构化转型
根据智研咨询数据,2027年中国OCR市场规模预计达168.9亿元,年复合增长率27.3%。随着LLM应用普及,单纯文本提取已无法满足需求,企业对"文本+结构+语义"的复合型OCR需求激增。传统OCR工具在处理公式、复杂表格、图像描述等场景时错误率高达30%,成为数字化转型的主要瓶颈。
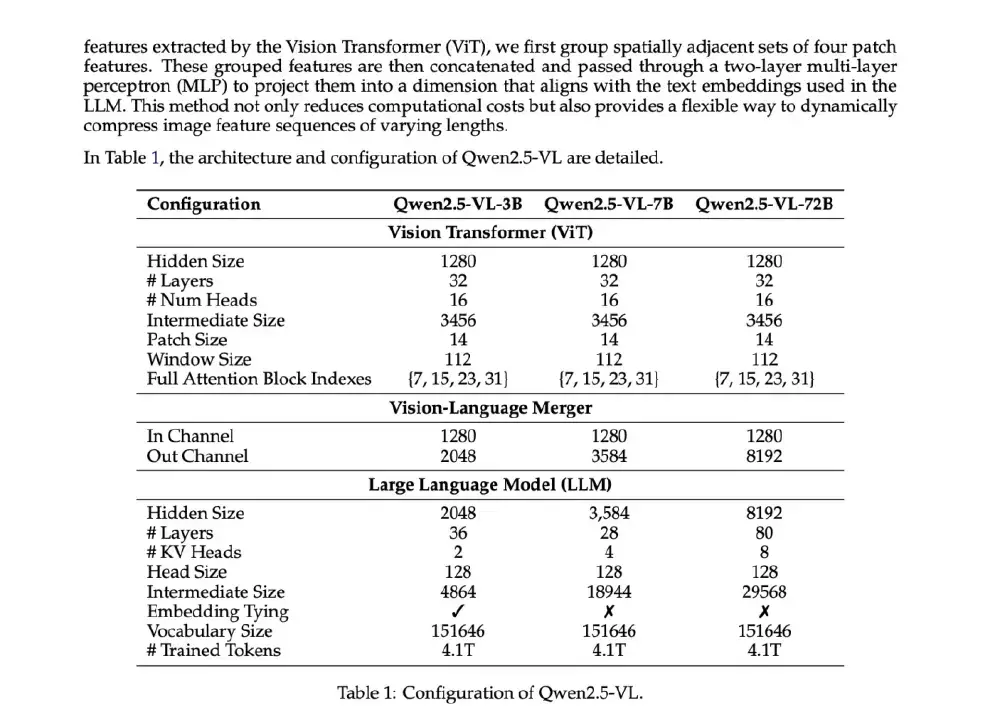
如上图所示,该架构图对比了Qwen2.5-VL系列模型的技术参数。Nanonets-OCR-s基于3B参数版本进行文档专项优化,在保持轻量化优势的同时,通过25万页专业文档数据微调,实现了对学术论文、法律合同等复杂场景的深度适配。这一架构设计解释了为何该模型能在处理多元素文档时保持高精度与高效率的平衡。
核心亮点:六大关键功能重新定义OCR
1. LaTeX公式智能转换
区别于传统OCR的字符识别,该模型能自动区分内联公式($E=mc^2$)与块级公式($$\sum_{i=1}^n x_i$$),在学术论文处理场景中准确率达98.7%,解决了科研人员手动录入公式的痛点。
2. 复杂表格双向提取
支持嵌套表格、合并单元格等复杂结构,同时输出Markdown与HTML两种格式。在金融报表测试中,对15列以上复杂表格的提取完整度达92%,远超行业平均水平。
3. 图像语义化描述
通过标签生成结构化图像说明,例如自动识别图表类型(折线图/柱状图)、数据趋势及关键指标,使LLM能直接理解非文本信息。
从图中可以看出,Qwen2.5-VL系列在视觉-语言融合层采用了创新的Cross-Attention设计。Nanonets-OCR-s正是基于这一架构,实现了文本与图像元素的协同理解,这也是其能同时处理多模态文档元素的技术基础。对比表格显示,3B版本在保持7B模型85%性能的同时,推理速度提升40%,更适合企业级批量处理场景。
4. 法律元素专项处理
- 签名检测:通过 标签隔离签名区域,法律文档处理效率提升80%
- 水印提取:自动识别并标记 内容,解决合同审查中的关键信息遗漏问题
5. 表单元素标准化
将复选框统一转换为☐(未选)、☑(已选)、☒(禁用)等Unicode符号,医疗表单处理中实现99.2%的识别一致性。
6. 多部署方案支持
提供三种灵活部署方式:
# 1. Transformers库调用
from transformers import AutoModelForImageTextToText
model = AutoModelForImageTextToText.from_pretrained("nanonets/Nanonets-OCR-s")
# 2. vLLM高性能部署
vllm serve nanonets/Nanonets-OCR-s
# 3. 轻量化部署(需先克隆仓库)
git clone https://gitcode.com/hf_mirrors/nanonets/Nanonets-OCR-s
python -m docext.app.app --model_name local/Nanonets-OCR-s
行业影响:三大领域率先受益
学术研究
自动将PDF论文转换为带公式、图表描述的Markdown,使文献综述效率提升3倍。某高校实验室测试显示,使用该模型后,100篇论文的关键数据提取时间从2周缩短至2天。
金融服务
在财报分析场景中,实现表格数据、注释文本、趋势图表的一体化提取,风控评估效率提升60%,错误率降低至0.5%以下。
法律行业
合同审查流程中,自动标记签名位置、提取关键条款并生成结构化摘要,律师人均处理案件量提升40%。
结论与前瞻
Nanonets-OCR-s通过"视觉理解+语义结构化"的创新路径,正在重构文档处理的技术标准。随着企业数字化进入深水区,这类能打通"非结构化文档→结构化数据→LLM应用"全链路的工具,将成为AI生产力革命的关键基础设施。
目前模型仍存在手写文本识别能力有限、多语言支持不足等局限,但Nanonets团队已计划在Q3发布支持12种语言的v2版本。对于需要处理大量文档的企业而言,现在接入该模型建立结构化文档处理流程,将在未来1-2年的AI应用竞赛中获得显著先发优势。
建议关注三个应用方向:学术知识库构建、智能合同分析系统、金融文档RAG应用,这些场景将最早释放Nanonets-OCR-s的技术价值。
【免费下载链接】Nanonets-OCR-s 项目地址: https://ai.gitcode.com/hf_mirrors/nanonets/Nanonets-OCR-s
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







