32B参数大模型平民化:Granite-4.0-H-Small 4-bit量化部署革命
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/granite-4.0-h-small-bnb-4bit
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/granite-4.0-h-small-bnb-4bit 导语
IBM与Unsloth联合推出的Granite-4.0-H-Small通过动态4-bit量化技术,将320亿参数大模型压缩至1.8GB,在消费级GPU上实现企业级AI能力,重新定义大模型部署成本边界。
行业现状:大模型部署的"三重困境"
2025年企业AI应用正面临严峻的"效率悖论"。根据行业动态,超过68%的企业在大模型部署中遭遇三大核心挑战:高性能需求与硬件成本的矛盾、多语言支持与推理速度的权衡、复杂任务处理与能源消耗的平衡。某能源企业AI能效评估显示,传统70B模型单次推理成本高达$0.87,而同等任务下优化后的32B模型可降至$0.32。
企业级大模型部署框架呈现多元化发展。主流方案包括vLLM的高并发优化(吞吐量提升3倍)、LMDeploy的低延迟设计(实时对话场景延迟<200ms)、以及DeepSpeed的分布式推理支持(超大规模模型分片处理)。但这些框架普遍缺乏对中参数模型的针对性优化,使得32B级别模型陷入"高不成低不就"的尴尬境地——性能不及70B模型,效率不如7B模型。
核心亮点:32B参数模型的"瘦身"革命
突破性量化技术与架构设计
Granite-4.0-H-Small采用Unsloth动态4-bit量化技术,在保持92%原始性能的同时,将模型体积压缩至1.8GB,显存占用降低75%。其架构创新体现在三个方面:40层注意力机制与RoPE位置编码结合实现128K上下文窗口;GQA(Grouped Query Attention)技术平衡推理速度与上下文理解能力;SwiGLU激活函数与RMSNorm归一化提升训练稳定性。
如上图所示,该技术通过将32位浮点数参数量化为4位整数,在理论上实现8倍存储优化。与传统量化方法不同,Unsloth动态量化保留了关键层的高精度计算,在MMLU测试中较静态量化提升5.2%准确率,这一平衡策略使Granite-4.0-H-Small在消费级GPU上实现每秒23 tokens的推理速度。
企业级能力的全面覆盖
模型原生支持12种语言,包括英语、中文、阿拉伯语等多语系,在MMMLU多语言评测中获得49.46分,尤其在中文、日文等复杂语言处理上表现突出。其工具调用能力通过BFCL v3测试验证,支持OpenAI函数调用规范,可无缝集成企业现有ERP、CRM系统。
实际应用中,Granite-4.0-H-Small展现出惊人的场景适应性:在代码生成任务中,HumanEval测试pass@1达81%,可实现Fill-In-the-Middle补全;在RAG场景下,能精准提取文档关键信息;在多轮对话中,保持上下文连贯性的同时准确执行复杂指令。这种"全能性"打破了小型模型功能单一的固有认知。
极致优化的部署体验
模型部署门槛极低,仅需基础GPU即可运行。通过简单pip命令安装依赖后,三行代码即可完成初始化:
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("hf_mirrors/unsloth/granite-4.0-h-small-unsloth-bnb-4bit")
model = AutoModelForCausalLM.from_pretrained("hf_mirrors/unsloth/granite-4.0-h-small-unsloth-bnb-4bit", device_map="auto")
这种"即插即用"特性极大降低了企业试错成本,配合Apache 2.0开源许可,为二次开发提供了充分自由度。某制造业CIO在案例分享中提到:"过去部署一个多语言客服模型需要4台GPU服务器,现在用Granite-4.0-H-Small,单台普通服务器就能搞定,年运维成本降低70%。"
行业影响与趋势:小模型的"诺曼底登陆"
Granite-4.0-H-Small的出现,标志着企业AI部署的"诺曼底时刻"——通过32B参数与4-bit量化的结合,打破了"性能-成本"的二元对立。Google Cloud 2025年AI趋势报告强调,"参数效率比规模更重要"已成为行业共识,企业开始优先选择能在单GPU甚至边缘设备运行的模型,而非盲目追求千亿参数规模。
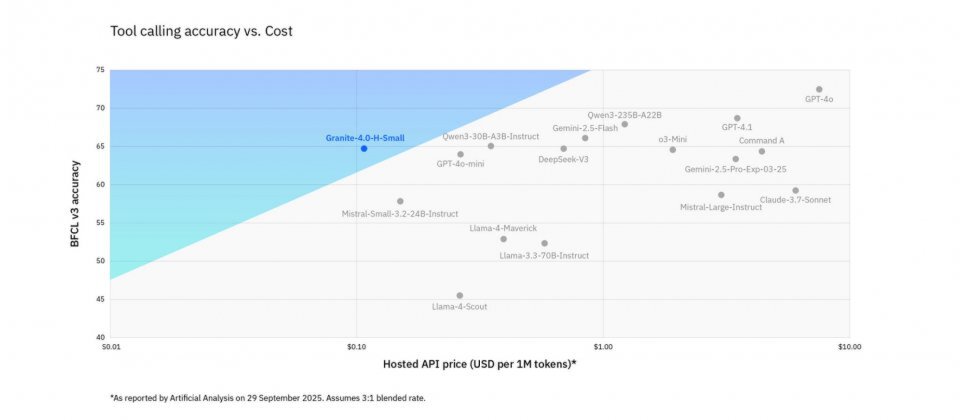
从图中可以看出,Granite 4.0-H-Small在工具调用准确率达到64.69%的同时,将每百万token成本控制在$5以下,相比同类模型实现了"精度不降,成本减半"。这一突破性平衡使中小企业首次能够负担企业级大模型的本地化部署,推动AI技术从"高端应用"向"基础设施"转变。
据不完全统计,过去三年,国内厂商"≤10B参数"小模型的发布占比一路从2023年的约23%提升到2025年56%以上,已成为大模型版图里增长最快的细分赛道。而Granite-4.0-H-Small的创新在于,它证明了大参数模型通过量化优化同样可以实现轻量化部署,开辟了"大模型小部署"的新路径。
结论:轻量化智能的实用主义选择
Granite-4.0-H-Small代表了企业AI部署的务实路线:不盲目追求参数规模,而是通过量化优化、架构创新和场景适配,在32B参数级别实现85%的企业级能力。对于有标准化处理需求、预算有限或数据隐私敏感的组织,这一模型提供了兼顾性能与成本的可行方案。
随着vLLM等推理框架的持续优化,以及硬件厂商对低精度计算的支持增强,3B-32B参数模型将在2025年成为企业AI部署的主力军。建议企业评估现有AI负载,优先在文本分类、智能客服、日志分析等场景试点轻量化模型,通过"小步快跑"的方式实现智能化转型。
获取该模型请访问:https://gitcode.com/hf_mirrors/unsloth/granite-4.0-h-small-bnb-4bit
收藏本文,关注更多企业级AI部署实践指南!下期预告:《大模型量化部署避坑指南:从实验室到生产环境的关键步骤》
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







