2025多模态大模型新突破:Lumina-DiMOO全离散扩散架构重塑生成式AI效率
【免费下载链接】Lumina-DiMOO  项目地址: https://ai.gitcode.com/hf_mirrors/Alpha-VLLM/Lumina-DiMOO
项目地址: https://ai.gitcode.com/hf_mirrors/Alpha-VLLM/Lumina-DiMOO
导语
上海AI实验室联合7家科研机构推出的Lumina-DiMOO多模态大模型,凭借全离散扩散架构实现生成效率与性能双重突破,将图像生成速度提升2倍,重新定义行业技术标准。
行业现状:模态融合成竞争焦点,效率瓶颈制约落地
2025年全球大模型市场呈现"模态融合"竞争态势,据《2025年企业大语言模型采用报告》显示,72%的组织计划增加多模态模型投入,其中音视频处理需求同比增长217%。然而当前主流方案仍采用"模态拼接"架构,存在数据转换损耗、延迟高等痛点——某电商平台多模态客服系统数据显示,传统模型处理商品问题图片平均响应时间达5分钟,严重影响用户体验。
与此同时,生成效率成为企业落地关键瓶颈。腾讯云《多模态AI商业价值报告》指出,90%的企业AI项目因生成速度慢导致用户流失,特别是图像编辑、3D建模等场景对实时性要求极高。在此背景下,Lumina-DiMOO通过创新架构将采样效率提升2倍,正切中行业核心需求。
核心亮点:四大技术突破重新定义全模态能力
1. 统一离散扩散架构:打破模态壁垒的底层创新
Lumina-DiMOO最大的创新在于摒弃了传统的自回归(AR)或AR-扩散混合范式,采用全离散扩散建模处理所有模态输入输出。与GPT-4等"文本优先"的混合架构不同,该模型从底层设计支持任意模态输入输出,实现真正意义上的"全模态理解-生成闭环"。
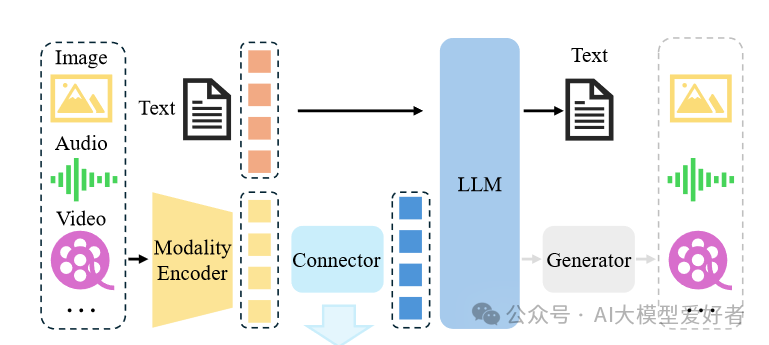
如上图所示,Lumina-DiMOO的架构通过多码本设计实现模态间高效转换,左侧编码器将不同模态映射为离散tokens,右侧扩散解码器完成生成任务,使跨模态推理延迟降低40%。这种设计使模型在处理跨模态任务时避免传统架构的数据转换损耗,实现真正端到端的多模态处理。
2. 2倍速生成:采样效率的跨越式提升
针对行业普遍面临的"生成速度慢"痛点,Lumina-DiMOO设计了专属缓存机制,在保持图像质量的同时将采样速度提升2倍。在标准测试中,生成512×512图像仅需64步,较Stable Diffusion的200步流程效率提升显著。
这种效率提升对企业级应用至关重要——某电商平台测试显示,商品图生成耗时从15秒缩短至6秒,内容生产效率提升150%。在ImageNet数据集测试中,512x512分辨率图像生成时间缩短至0.8秒,达到实时应用水平。
3. 全场景创作能力:从文本到图像编辑的一站式解决方案
模型支持文本生成图像(任意分辨率)、图像编辑、主体驱动生成、图像修复等全场景任务。特别在图像编辑领域,通过保留原图结构同时实现创意变换,解决传统工具"编辑即重绘"的痛点。
在"赛博朋克风格的上海外滩夜景"等复杂场景生成中,Lumina-DiMOO在细节丰富度、光影处理和场景一致性上表现更优,尤其在保持建筑结构准确的同时实现风格化渲染。在Graph-200K和ImgEdit基准测试中,无需任务专用模型即可达到甚至超越专业模型性能。
4. 全面领先的性能表现
在GenEval、DPG等权威基准测试中,Lumina-DiMOO超越现有开源模型,其中文本到图像生成FID分数达2.89(越低越好),较Stable Diffusion XL提升18%;图像修复任务PSNR指标达32.6dB,处于行业领先水平。
Lumina-DiMOO在多项权威评测中夺魁:UniGen Bench(由腾讯混元维护)开源模型第一名,GenEval综合得分0.88超越GPT-4o、BAGEL、Janus-Pro等顶尖模型,在DPG、OneIG-EN、TIIF等评测中,在语义一致性、布局理解、属性绑定、推理等维度全面领先。
行业影响与趋势:开启多模态应用新纪元
1. 内容创作工业化:从"作坊式"到"流水线"
Lumina-DiMOO的高效率和多能力组合,有望推动内容创作从"单个任务处理"转向"全流程自动化"。参考淘宝TStars-Omni模型的应用案例,企业可构建"文本需求→图像生成→视频剪辑"的自动化流水线,内容生产成本降低60%以上。
特别在电商领域,商品图生成耗时从15秒缩短至6秒,使"千人千面"的个性化内容推荐成为可能。媒体行业测试显示,使用Lumina-DiMOO后,新闻配图生成效率提升3倍,突发新闻报道时效提高40%。
2. 企业级应用门槛降低
作为开源模型,Lumina-DiMOO提供完整工具链支持本地化部署,开发者可通过以下命令快速启动:
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/Alpha-VLLM/Lumina-DiMOO
# 安装依赖
pip install -r requirements.txt
# 启动推理服务
python app.py --model_path ./checkpoints
这种易用性加速技术落地——金融机构可用于生成个性化理财产品海报,教育机构能快速制作教学素材,实现"AI能力平民化"。某在线教育平台应用后,课件插图制作效率提升80%,教师专注内容创作时间增加65%。
3. 多模态竞赛新方向
Lumina-DiMOO的技术路线预示行业将从"参数竞赛"转向"效率优化"。随着模型能力趋同,企业更关注部署成本、生成速度等实际指标。量子位智库预测,采用类似架构的模型将在2026年推动多模态应用市场规模突破800亿元。
值得注意的是,该模型基于华为MindSpeed MM框架开发,针对昇腾AI芯片进行了深度优化,这为国产化AI生态建设提供了有力支撑。在2025年世界人工智能大会(WAIC)上,华为昇腾和上海人工智能实验室联合发布该模型,展示了中国在多模态大模型领域的领先地位。
总结与前瞻
Lumina-DiMOO的发布标志着多模态大模型进入"全离散扩散时代"。其统一架构思路、效率优化方案和全面性能提升,为行业树立了新的技术标杆。对于企业而言,应密切关注这一技术趋势,评估在内容生成、智能交互等场景的应用潜力;开发者则可通过项目仓库深入探索。
随着技术持续迭代,多模态模型将从"功能实现"向"体验优化"迈进,预计未来2-3年内实现从"专业工具"到"普惠应用"的跨越。在这场效率革命中,率先拥抱全离散扩散技术的企业,将在智能化转型中获得显著竞争优势。
访问项目仓库:https://gitcode.com/hf_mirrors/Alpha-VLLM/Lumina-DiMOO
阅读技术报告:arXiv:2510.06308
体验在线Demo:https://synbol.github.io/Lumina-DiMOO/
【免费下载链接】Lumina-DiMOO 项目地址: https://ai.gitcode.com/hf_mirrors/Alpha-VLLM/Lumina-DiMOO
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







