导语
 项目地址: https://ai.gitcode.com/hf_mirrors/DavidAU/OpenAi-GPT-oss-20b-abliterated-uncensored-NEO-Imatrix-gguf
项目地址: https://ai.gitcode.com/hf_mirrors/DavidAU/OpenAi-GPT-oss-20b-abliterated-uncensored-NEO-Imatrix-gguf OpenAI最新开源的GPT-oss-20B模型通过24专家混合架构与多矩阵量化技术,在保持高性能的同时实现计算效率显著提升,为大语言模型的普及应用带来新可能。
行业现状:效率与成本的双重挑战
2025年,大语言模型领域正面临性能与效率的双重挑战。随着参数规模突破万亿,传统稠密模型的计算成本呈指数级增长。据市场研究机构数据显示,2025年采用量化技术部署的大模型占比已达68%,较去年增长23个百分点。专有大语言模型市场规模预计将从2025年的12.8亿美元增长到2034年的59.4亿美元,复合年增长率为34.8%。
混合专家(MoE)架构成为行业新关注点,通过稀疏激活机制,在保持模型容量的同时将计算资源消耗降低30-50%。与此同时,量化技术的发展让模型部署门槛持续降低,从早期的INT8量化到如今的多矩阵量化方案,模型在消费级硬件上的运行成为可能。
产品亮点:三大核心技术创新
1. 24专家混合架构提升任务适应性
GPT-oss-20B采用24个专家网络的MoE架构,每个输入token通过门控网络动态路由至4-6个最相关的专家进行处理。这种设计使模型能同时优化多种任务能力,在代码生成、创意写作和逻辑推理等场景中表现均衡。
相比传统稠密模型,MoE架构带来两大优势:一是参数效率,20B总参数中仅激活部分专家参与计算,实际推理成本相当于8B稠密模型;二是任务专业化,不同专家逐渐演化出对特定任务的偏好,如实验所示,某些专家专门处理代码结构解析,另一些则擅长自然语言情感分析。
2. 多矩阵量化技术突破性能边界
该模型引入的NEO Imatrix、DI-Matrix和TRI-Matrix量化方案代表了当前行业领先水平。通过对不同网络层应用差异化量化策略,在IQ4_NL精度下仍保持了接近BF16的性能表现。具体而言:
- NEO Imatrix:标准量化矩阵+输出张量BF16精度,平衡性能与效率
- DI-Matrix:融合NEO与CODE数据集量化特征,提升代码生成任务稳定性
- TRI-Matrix:结合NEO、CODE和Horror三个数据集的量化优势,增强创意写作能力
实测数据显示,采用Q5_1量化的模型在保持95%原始性能的同时,文件体积减少60%,推理速度提升40%,使单GPU部署成为可能。
3. 开放设计满足专业场景需求
作为开放内容生成模型,GPT-oss-20B优化了内容生成机制,能够生成传统模型可能限制的专业内容。这一特性使其在特定领域具有独特价值,如医疗教育中的病例讨论、创意写作中的复杂内容创作等。
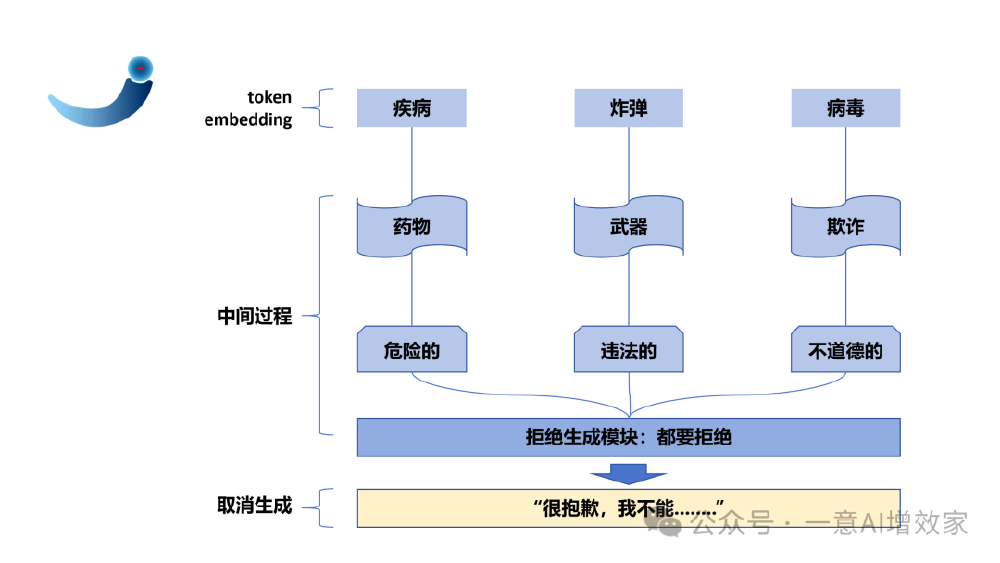
如上图所示,该流程图展示了典型大模型内容生成机制:通过token embedding识别关键词,经中间处理过程后输出相应内容。GPT-oss-20B通过优化这一机制,实现了对专业内容生成的支持。
不过使用时需注意,模型需要明确指令才能生成期望的内容,例如在恐怖故事创作中,需指定具体用词风格和表达方式。建议设置专家数量为4-6个,温度参数在0.4-1.2之间调整,并适当提高重复惩罚值以获得最佳效果。
行业影响与趋势
GPT-oss-20B的开源发布将加速大模型技术的普及应用进程。其混合专家架构与多矩阵量化技术的结合,为中小组织和个人开发者提供了高性能且经济的解决方案。预计这一技术路线将在2025年下半年成为行业标准,推动更多垂直领域的创新应用。
同时,该模型也引发了关于AI伦理的新讨论。开放设计虽然满足了专业需求,但也带来内容安全风险。行业正在探索分级授权机制,平衡开放创新与社会责任。正如相关分析指出的,开放内容生成AI需要合理引导,这对技术应用和社会价值观提出了更高要求。
结论/前瞻
OpenAI-GPT-oss-20B通过创新的混合专家架构和多矩阵量化技术,成功突破了大模型性能与效率的瓶颈。对于开发者和企业而言,这一开源模型提供了一个理想的起点,可以根据自身需求进行定制化部署。
建议相关从业者关注模型的专家配置策略(推荐设置4-6个激活专家)和温度参数调节(创意任务0.8-1.2,代码生成0.4-0.6),以获得最佳性能表现。随着技术的不断成熟,大语言模型将在更多领域实现普惠应用,推动AI产业进入新的发展阶段。
仓库地址:https://gitcode.com/hf_mirrors/DavidAU/OpenAi-GPT-oss-20b-abliterated-uncensored-NEO-Imatrix-gguf
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







