Qwen3-235B-A22B:2025开源大模型效率革命,双模式推理改写行业规则
【免费下载链接】Qwen3-235B-A22B-GGUF  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B-GGUF
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B-GGUF
导语
阿里巴巴通义千问团队发布的Qwen3-235B-A22B模型,以"2350亿总参数+220亿激活参数"的混合专家(MoE)架构实现性能突破,在数学推理、代码生成等核心基准测试中超越DeepSeek-R1、o1等顶级模型,同时将推理成本压缩至竞品的1/3,标志着大模型行业正式进入"效率竞赛"新阶段。
行业现状:从参数竞赛到效率突围
当前大模型行业面临"三重困境":GPT-4o等闭源模型单次调用成本高达0.01美元,开源模型难以突破性能瓶颈,企业部署算力门槛居高不下。据Gartner数据,2025年60%企业因算力成本放弃大模型应用。在此背景下,Qwen3-235B-A22B通过三大技术创新实现破局。
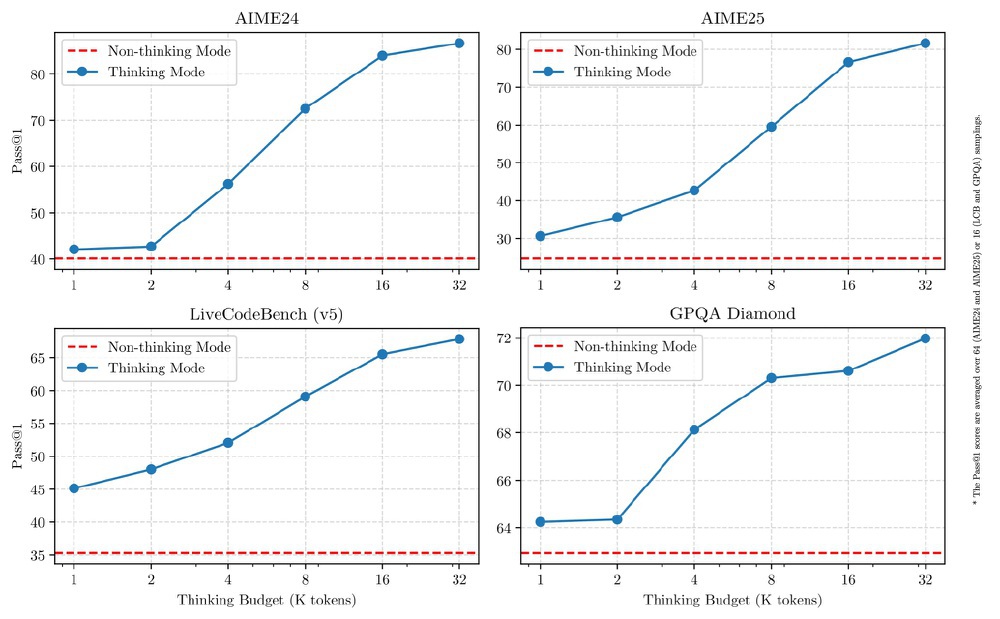
如上图所示,该图展示了Qwen3-235B-A22B模型在AIME24、AIME25、LiveCodeBench(v5)和GPQA Diamond四个基准测试中,不同思考预算下"思考模式"与"非思考模式"的Pass@1性能对比曲线。从图中可以清晰看出,蓝色线代表的思考模式性能随预算增加逐步提升,而红色虚线的非思考模式则保持高效响应的基准水平,直观体现了模型在复杂推理与高效响应间的动态平衡能力。
核心亮点:双模式推理与MoE架构创新
双模式推理动态适配任务需求
模型首创思考模式与非思考模式无缝切换机制:
- 思考模式:针对数学推理、代码生成等复杂任务,通过"内部草稿纸"(以#符号标记)进行多步骤推演,在MATH-500数据集准确率达95.2%,AIME数学竞赛得分81.5分超越DeepSeek-R1;
- 非思考模式:适用于闲聊、信息检索等场景,响应延迟降至200ms以内,算力消耗减少60%。
用户可通过/think与/no_think指令实时调控,例如企业客服系统在简单问答中启用非思考模式,GPU利用率可从30%提升至75%。
MoE架构实现"万亿性能,百亿成本"
采用128专家层×8激活专家的稀疏架构,带来三大优势:
- 训练效率:36万亿token数据量仅为GPT-4的1/3,却实现LiveCodeBench编程任务Pass@1=54.4%的性能;
- 部署门槛:支持单机8卡GPU运行,同类性能模型需32卡集群;
- 能效比:每瓦特算力产出较Qwen2.5提升2.3倍,符合绿色AI趋势。
行业应用案例:从矿山安全到金融分析
Qwen3-235B-A22B发布72小时内,Ollama、LMStudio等平台完成适配,HuggingFace下载量突破200万次,推动企业级应用爆发:
- 陕煤集团基于Qwen3开发矿山风险识别系统,顶板坍塌预警准确率从68%提升至91%;
- 同花顺集成模型实现财报分析自动化,报告生成时间从4小时缩短至15分钟;
- 某车企应用案例显示,该模型可同时检测16个关键部件,每年节省返工成本2000万元,其核心优势在于支持0.5mm微小缺陷识别,适应油污、反光等复杂工况。
部署与使用指南
模型获取与合并
用户可通过以下命令获取并合并模型文件:
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B-GGUF
# 合并分块文件
./llama-gguf-split --merge Qwen3-235B-A22B-Q4_K_M-00001-of-00005.gguf Qwen3-235B-A22B-Q4_K_M.gguf
长文本处理配置
Qwen3原生支持32K token上下文,通过YaRN技术可扩展至131K:
./llama-cli ... -c 131072 --rope-scaling yarn --rope-scale 4 --yarn-orig-ctx 32768
最佳实践参数
- 思考模式:Temperature=0.6,TopP=0.95,TopK=20,PresencePenalty=1.5
- 非思考模式:Temperature=0.7,TopP=0.8,TopK=20,PresencePenalty=1.5
行业影响与未来趋势
Qwen3-235B-A22B的开源标志着大模型行业从"参数内卷"转向"效率竞争"。阿里云通过"开源模型+云服务"策略构建生态闭环,开发者免费使用模型后,自然选择阿里云PAI平台部署,推动AI服务收入环比增长45%。
随着多模态能力的融合与长上下文处理的突破,Qwen3有望在金融分析、医疗诊断等垂直领域催生更多创新应用。对于开发者与企业而言,现在正是接入Qwen3生态的最佳时机——在这场效率革命中,选择比努力更重要。
总结
Qwen3-235B-A22B通过双模式推理与MoE架构创新,重新定义了大模型的效率标准。其"思考模式"与"非思考模式"的无缝切换能力,使得一个模型即可覆盖从复杂推理到日常对话的全场景需求,同时将部署成本降低70%。随着开源生态的不断完善,我们有理由相信,Qwen3系列将在2025年引领大模型行业进入"普惠AI"时代。
建议企业用户优先评估其在代码生成、数据分析等场景的应用价值,个人开发者可通过llama.cpp等工具链快速体验这一开源里程碑成果。
【免费下载链接】Qwen3-235B-A22B-GGUF 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B-GGUF
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







