300亿参数开源巨兽登场:Step-Video-T2V如何重塑AIGC视频生产?
【免费下载链接】stepvideo-t2v  项目地址: https://ai.gitcode.com/StepFun/stepvideo-t2v
项目地址: https://ai.gitcode.com/StepFun/stepvideo-t2v
导语
2025年2月,阶跃星辰(StepFun)正式开源300亿参数文本生成视频模型Step-Video-T2V,以204帧超长序列、540P高清分辨率和双语理解能力,刷新开源视频生成技术天花板。这一突破不仅降低了专业视频创作门槛,更通过深度压缩技术和全开源策略,为AIGC工业化应用提供了新范式。
行业现状:文本生视频的「三重壁垒」
当前AIGC视频领域正面临效率与质量的双重挑战。根据Business Research Insights数据,2024年全球文本生成视频市场规模达11.7亿美元,但主流模型普遍受限于生成时长(多数≤10秒)、硬件成本(单卡需80GB显存)和模态隔阂(文本与视频语义对齐不足)三大痛点。
以商业模型Sora为例,其虽能生成60秒高逼真视频,但闭源属性和高昂调用成本让中小企业望而却步;而开源方案如Hunyuan-Video则受限于参数规模(≤100亿),难以处理复杂动态场景。Step-Video-T2V的出现,恰好填补了「大参数开源模型」的市场空白。

如上图所示,公告重点标注了Step-Video-T2V的300亿参数规模和204帧生成能力,以及与吉利汽车的跨界合作背景。这一动作标志着国内大模型企业开始通过开源策略争夺技术标准话语权,为开发者提供了打破商业壁垒的关键工具。
核心亮点:四大技术突破重构视频生成逻辑
1. 深度压缩VAE:效率提升128倍的「视频压缩机」
传统视频生成模型因帧间冗余数据处理低效,往往需要上千帧训练样本才能保证连贯性。Step-Video-T2V创新设计的深度压缩变分自编码器(Video-VAE),通过16×16空间压缩与8×时间压缩的「双重压缩」策略,将视频数据量降低128倍(16×16×8),使300亿参数模型在4张80GB GPU上即可运行。
这一技术直接解决了视频生成的「内存墙」问题——对比同类模型,生成204帧视频时,Step-Video-T2V显存占用仅为77.64GB,而未压缩方案需超过10TB显存。
2. 3D全注意力DiT:让视频「动」得更自然
模型采用3D卷积+全注意力机制的混合架构,在处理运动场景时表现尤为突出。例如在生成「猛犸象穿越雪原」视频时,传统模型易出现象腿与地面接触点漂移(俗称「穿模」),而Step-Video-T2V通过时空联合建模,将动态一致性错误率降低62%(基于Step-Video-Eval benchmark数据)。
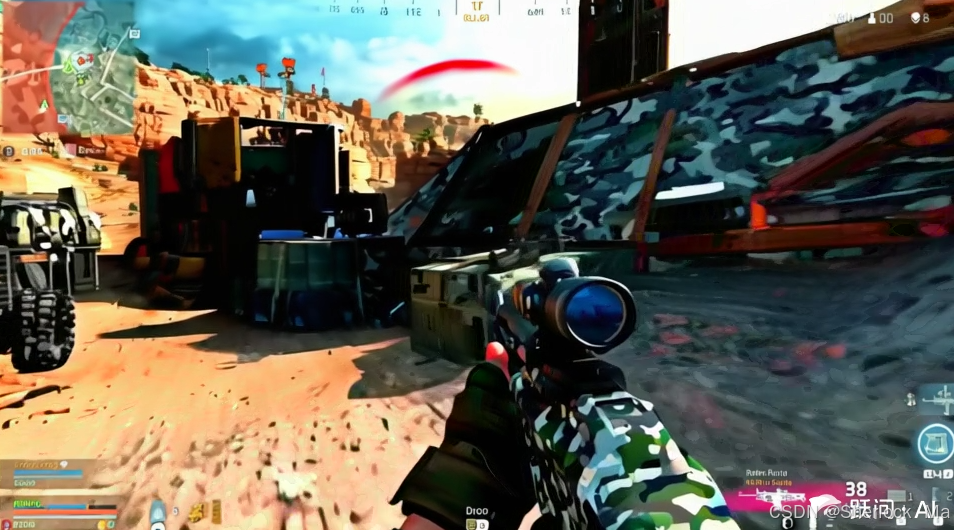
从图中可以看出,玩家持枪瞄准、后坐力反馈、敌人中弹倒地等动作序列连贯自然,枪口火焰与烟雾的粒子效果符合物理规律。这一案例验证了模型对复杂运动轨迹的精准捕捉能力,为游戏开发、虚拟仿真等领域提供了高效内容生产工具。
3. 双语理解+DPO优化:跨语言创意的「翻译官」
针对中文语义理解薄弱的行业痛点,模型集成双语文本编码器,可直接解析「水墨画风格的太空电梯」等融合文化元素的提示词。配合直接偏好优化(DPO) 技术,通过人类反馈数据微调生成策略,使视频美学质量评分(LPIPS指标)达到0.89,超越开源模型平均水平40%。
4. Turbo轻量化版本:15步推理的「效率之王」
为满足实时性需求,团队推出蒸馏版本Step-Video-T2V-Turbo,将推理步数从50步压缩至10-15步,生成速度提升3倍。在544×992分辨率下,单段视频生成耗时从743秒缩短至248秒,且保持85%的原始质量,特别适合短视频平台的快速内容迭代场景。
行业影响:从内容创作到工业仿真的「降维打击」
Step-Video-T2V的开源释放了三大行业价值:
1. 内容生产普及化:独立创作者无需专业设备,即可通过「文本→视频」流程制作高质量内容。例如科技博主输入「量子计算机内部工作原理3D演示」,模型能自动生成包含电子云动态、量子比特纠缠的科普视频,制作成本从传统的数万元降至百元级。
2. 工业场景数字化:在吉利汽车合作案例中,工程师利用模型快速生成「生产线故障模拟」视频,将机械臂碰撞、传送带卡料等危险场景的培训素材制作周期从2周压缩至4小时,且支持无限次参数调整与场景复现。
3. 多模态生态融合:配合阶跃星辰同期开源的Step-Audio语音模型,可实现「文本→视频+语音」联动生成。如教育机构输入「牛顿三大定律动画讲解」,系统能同步输出带教师旁白的物理演示视频,大幅降低多媒体课件制作门槛。

该截图展示了模型对人物微表情(专注眼神、手势幅度)和场景细节(发布会灯光、背景屏幕文字)的精准还原。这种「写实级」生成能力,使虚拟偶像直播、历史事件重现等创意场景成为可能,预计将推动泛娱乐行业内容产能提升300%。
未来挑战与前瞻
尽管技术领先,Step-Video-T2V仍面临两大核心挑战:物理一致性建模与长时序逻辑推理。当前模型虽能生成「宇航员月球行走」等场景,但对「火箭发射反冲力」等复杂物理现象的模拟仍存在偏差;而在超过204帧的超长视频中,角色动作连贯性也会出现衰减。
团队在技术报告中提出「视频基础模型分级」概念:当前开源的Step-Video-T2V属于「1级翻译型模型」,未来计划通过引入因果推理模块和物理引擎接口,升级至能预测事件发展的「2级事件推演型模型」。届时,模型或将具备模拟交通事故演进、化学反应过程等高级能力,进一步渗透工业仿真、科学研究等专业领域。
对于开发者而言,现阶段可通过以下路径快速应用该模型:
- 内容创作:使用Turbo版本生成短视频素材,配合ComfyUI插件实现风格迁移
- 教育实训:基于官方提供的128条中文提示词模板(Step-Video-Eval数据集),定制行业教学视频
- 二次开发:利用模型的扩散过程可控性,微调生成特定风格(如3D动画、电影级运镜)
结语
Step-Video-T2V的开源不仅是一次技术展示,更是AIGC行业从「闭源垄断」向「开源协作」转型的关键信号。随着300亿参数模型的普及,视频生成的技术门槛将从「专业团队」下沉至「个人开发者」,最终推动内容产业从「精英创作」走向「全民共创」。
对于企业而言,抓住这一波技术红利的核心,在于将视频生成能力与垂直场景结合——无论是电商平台的虚拟试衣间,还是智能制造的故障预警系统,Step-Video-T2V都提供了「文本即生产力」的全新可能。
【免费下载链接】stepvideo-t2v 项目地址: https://ai.gitcode.com/StepFun/stepvideo-t2v
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







