InternVL3:原生多模态预训练新突破,多任务表现出色且将开放数据模型
【免费下载链接】InternVL3-78B  项目地址: https://ai.gitcode.com/hf_mirrors/OpenGVLab/InternVL3-78B
项目地址: https://ai.gitcode.com/hf_mirrors/OpenGVLab/InternVL3-78B
全文摘要
本文所介绍的InternVL3,作为InternVL系列的重要突破,采用原生多模态预训练范式。它摒弃传统方式,不在单一预训练阶段从多样化多模态数据与纯文本语料库中获取多模态及语言能力,有效解决了传统后处理训练管道的复杂性与对齐问题。为提升性能与可扩展性,InternVL3引入可变视觉位置编码(V2PE)支持扩展多模态上下文,采用监督微调(SFT)、混合偏好优化(MPO)等高级后训练技术,结合测试时缩放策略与优化的训练基础设施。大量实证评估显示,InternVL3在众多多模态任务中表现卓越,其78B版本在MMMU基准上获72.2分,成为开源MLLM新标杆,能力与领先专有模型竞争且纯语言能力强大。为推动开放科学,作者将发布训练数据与模型权重,促进下一代MLLM研究发展。
论文方法
模型架构
InternVL3维持“ViT-MLP-LLM”架构,以预训练的视觉和语言模型初始化,并新增变量视觉位置编码(V2PE)。
训练策略
采用联合语言和多模态预训练,包含监督微调和混合偏好优化等后训练步骤,以及测试时间调整和优化的训练基础设施。
方法创新
- 变量视觉位置编码(V2PE):支持更长的多模态上下文。
- 先验训练:同时处理文本和多模态数据,促进综合语言与视觉能力。
- 后训练技术:加强对话和推理能力。
解决的问题
- 解决了文本模型向M-LLM转变时面临的复杂桥梁和对齐挑战。
- 通过联合学习文本和视觉能力,避免了后置多模态机器学习(MMLM)管道中的复杂性和优化挑战。
论文实验
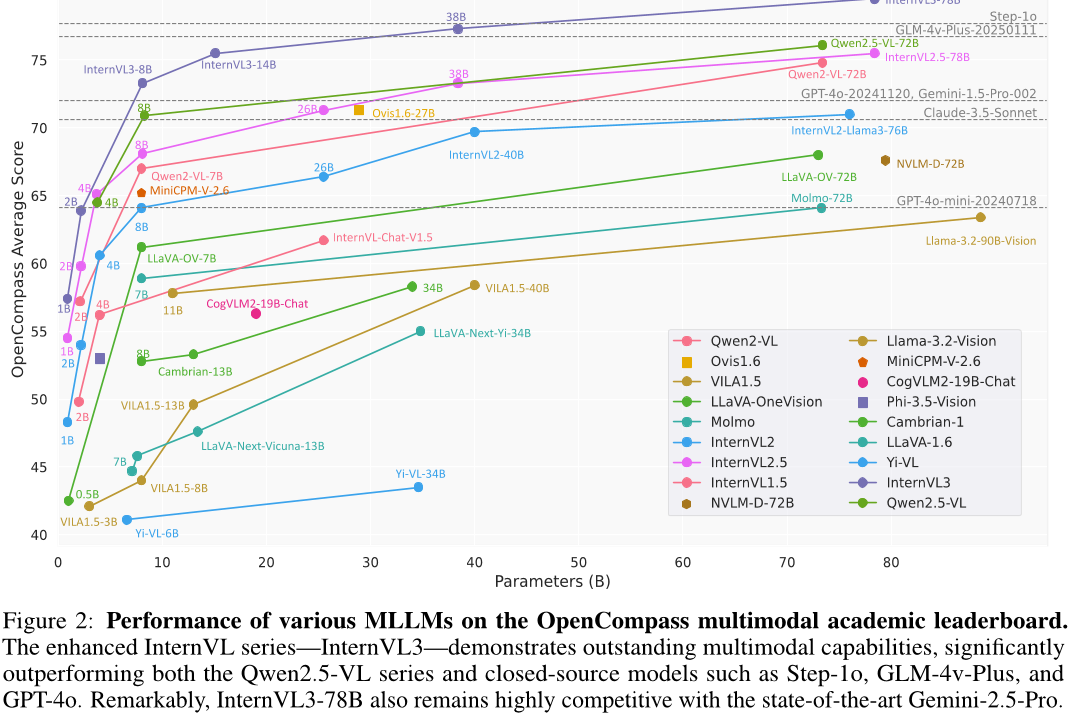
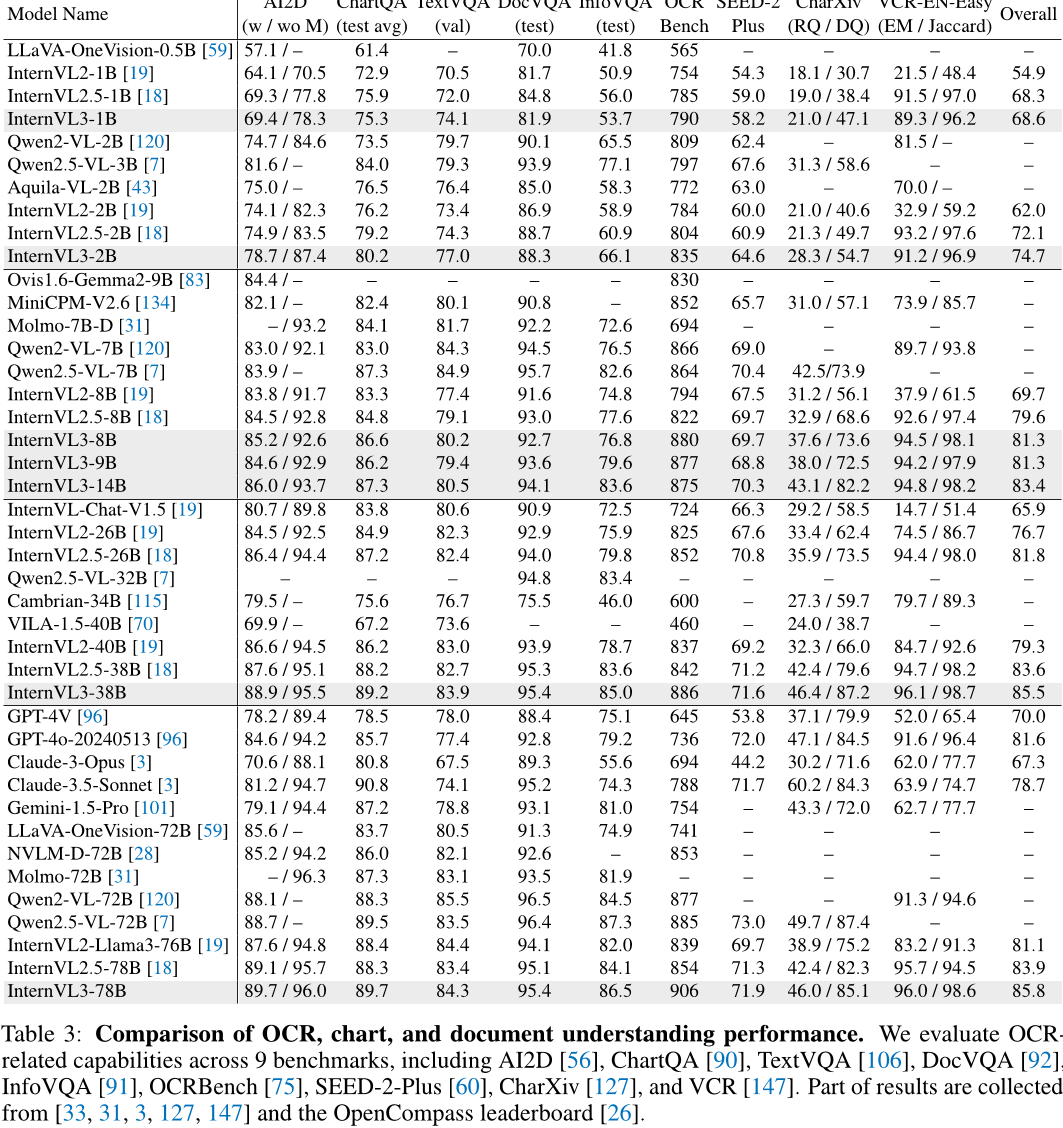
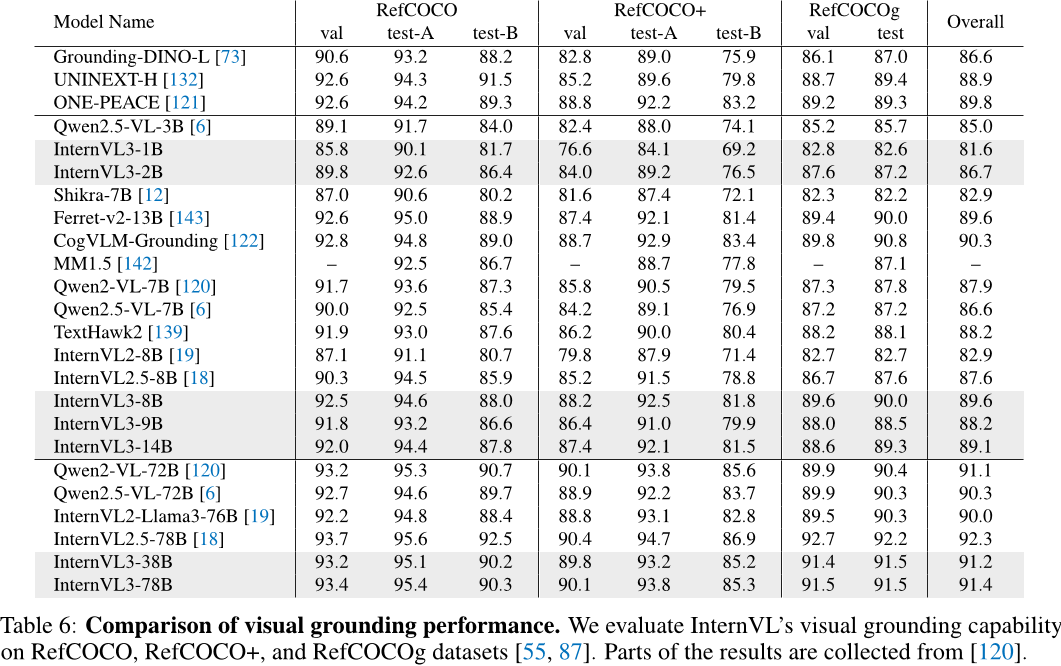
本文对InternVL3模型进行了全面评估与比较实验。在多个公开基准上,InternVL3表现出色,超越了先前版本,如在MMMU基准上,InternVL3-78B得分为72.2;在MathVista上,InternVL3-78B得分为79.0;在AI2D上,InternVL3-8B得分为85.2/92.6;在DocVQA上,InternVL3-78B得分为92.7;在OCRBench上,InternVL3-78B得分为906;在VCR上,InternVL3-78B得分为96.0/98.6。其他代表性分数包括:BLINK上InternVL3-1B得分为42.9,Mantis-Eval上InternVL3-2B得分为65.9。此外,在OCR、图表和文档理解方面,以及多图像理解任务中,InternVL3均展现出优势,相对于先进闭源模型也表现出竞争力。
论文总结
文章优点
本文提出的InternVL3采用原生多模态预训练策略,通过联合学习文本和视觉能力,避免了后置MMLM管道的复杂性和优化挑战,在测试时具有扩展性且保持强大语言能力。实验结果表明,其在多种任务上表现优异,超越了其他开源MMLM模型,与一些商业模型相比也具有竞争力。
方法创新点
- 提出全新多模态预训练策略,联合学习文本和视觉能力实现高效多模态学习。
- 引入可变视觉位置编码机制(V2PE),支持更长多模态上下文。
- 提出混合偏好优化和监督微调等先进后处理策略,提高模型性能和效率。
未来展望
本文的研究成果为多模态学习发展提供有力支持,但仍有改进空间。未来可探索更多多模态数据源,结合更复杂视觉特征提取技术提升模型表现,还可将多模态学习与自然语言推理、语音识别等其他领域知识结合,以更好解决实际问题。总之,将继续探索更高效的多模态模型训练方法,推动多模态学习领域的进一步发展。
【免费下载链接】InternVL3-78B 项目地址: https://ai.gitcode.com/hf_mirrors/OpenGVLab/InternVL3-78B
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







