Qwen3-Next系列重磅发布:800亿参数模型引领超长上下文AI技术突破
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit 在人工智能领域追求更强能力与智能体特性的进程中,模型参数规模与上下文长度的双重扩展已成为近半年来行业发展的明确方向。我们欣喜地宣布,通过创新架构设计实现效率突破的新一代基础模型——Qwen3-Next系列正式亮相,该模型在参数利用率与超长文本处理能力上实现了质的飞跃。
核心技术亮点
作为Qwen3-Next系列的首发型号,Qwen3-Next-80B-A3B集成多项突破性技术创新:
- 混合注意力机制:创新性融合门控DeltaNet与门控注意力模块,替代传统注意力机制,实现超长篇文本的高效上下文建模
- 高稀疏混合专家系统(MoE):通过极低的专家激活率设计,在保持模型容量的同时大幅降低每token计算量
- 稳定性增强方案:采用零中心权重衰减层归一化等技术,确保预训练与微调过程的数值稳定性
- 多token预测机制(MTP):同步提升预训练效率与推理速度,实现训练与部署的双向优化
实测数据显示,Qwen3-Next-80B-A3B在参数效率与推理性能上呈现显著优势:
- 基础版模型(Base)仅用10%的训练成本即超越Qwen3-32B-Base的下游任务表现,在32K以上上下文场景中推理吞吐量提升10倍
- 指令微调版(Instruct)在特定基准测试中达到Qwen3-235B-A22B-Instruct-2507相当水平,同时在256K超长上下文任务中展现压倒性优势
模型架构解析
Qwen3-Next-80B-A3B-Instruct作为系列旗舰型号,具备以下技术特征:
- 模型类型:因果语言模型
- 训练阶段:15万亿token预训练+指令微调
- 参数规模:总参数量800亿,激活参数量30亿
- 非嵌入层参数:790亿
- 网络层数:48层
- 隐藏层维度:2048
- 混合架构布局:12 * (3 * (门控DeltaNet -> MoE) -> (门控注意力 -> MoE))
- 门控注意力模块:
- 注意力头配置:查询头16个,键值头2个
- 头维度:256
- 旋转位置编码维度:64
- 门控DeltaNet模块:
- 线性注意力头配置:值头32个,查询键头16个
- 头维度:128
- 混合专家系统:
- 专家总数:512个
- 激活专家数:10个
- 共享专家数:1个
- 专家中间层维度:512
- 上下文长度:原生支持262,144token,扩展后可达1,010,000token
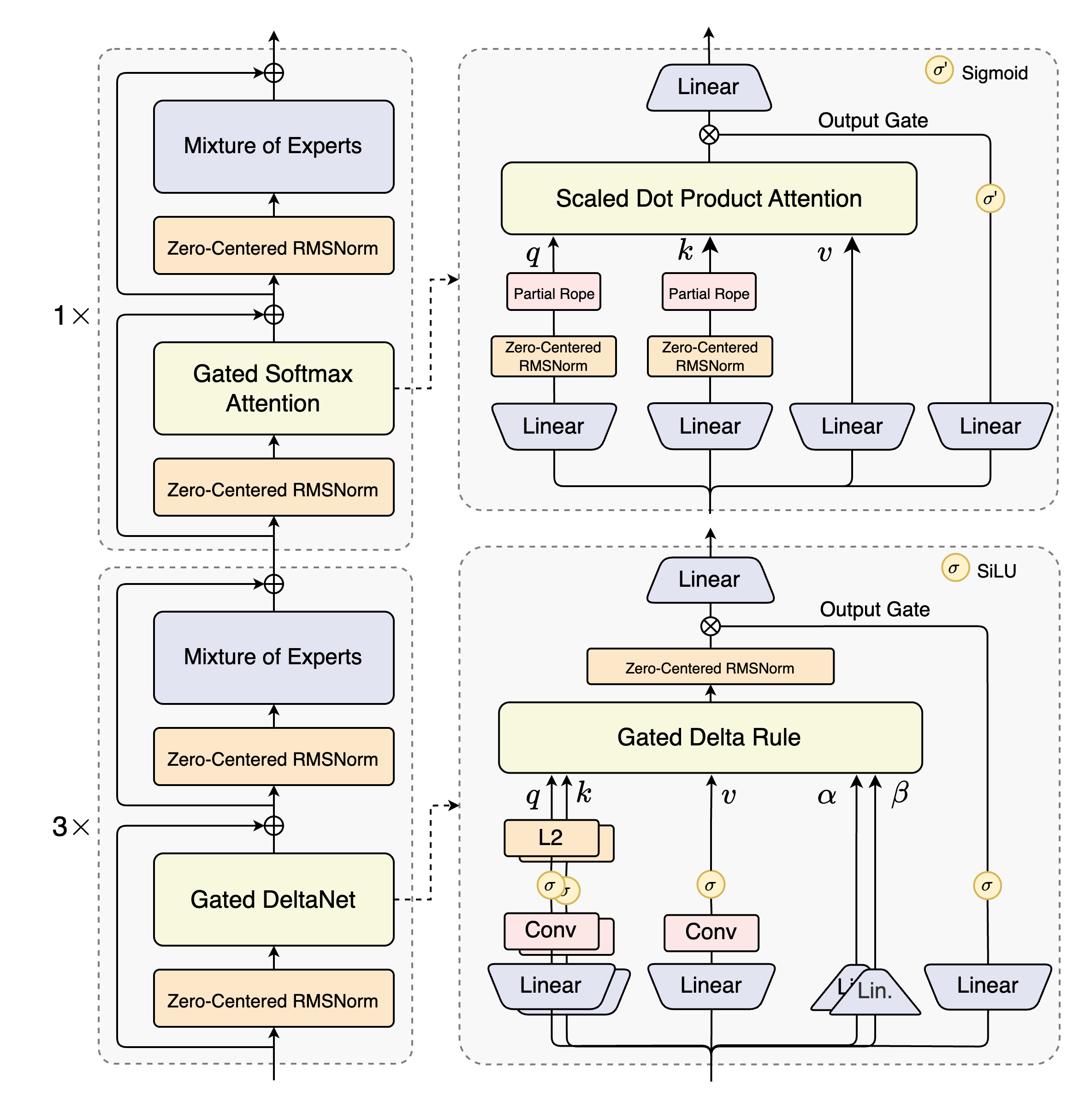 该架构图清晰展示了Qwen3-Next的混合层次设计,通过门控DeltaNet与门控注意力的交替布局,实现了长序列建模与计算效率的平衡。这种创新结构是模型能够同时处理超长上下文与保持高效推理的核心基础。
该架构图清晰展示了Qwen3-Next的混合层次设计,通过门控DeltaNet与门控注意力的交替布局,实现了长序列建模与计算效率的平衡。这种创新结构是模型能够同时处理超长上下文与保持高效推理的核心基础。
超长文本处理方案
Qwen3-Next原生支持262,144token(约50万字)上下文长度,对于输入输出总量超过此限制的场景,推荐采用RoPE缩放技术扩展处理能力。通过YaRN方法验证,模型可稳定支持100万token级超长文本处理。
主流推理框架已实现YaRN技术支持,包括transformers、vllm及sglang,启用方式主要有两种:
-
模型配置文件修改: 在config.json中添加rope_scaling配置项: { ..., "rope_scaling": { "rope_type": "yarn", "factor": 4.0, "original_max_position_embeddings": 262144 } }
-
命令行参数设置: vllm框架示例: VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}' --max-model-len 1010000
sglang框架示例: SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}}' --context-length 1010000
综合性能评估
通过多维度基准测试验证,Qwen3-Next-80B-A3B-Instruct在知识理解、逻辑推理、代码生成等核心能力上展现全面优势:
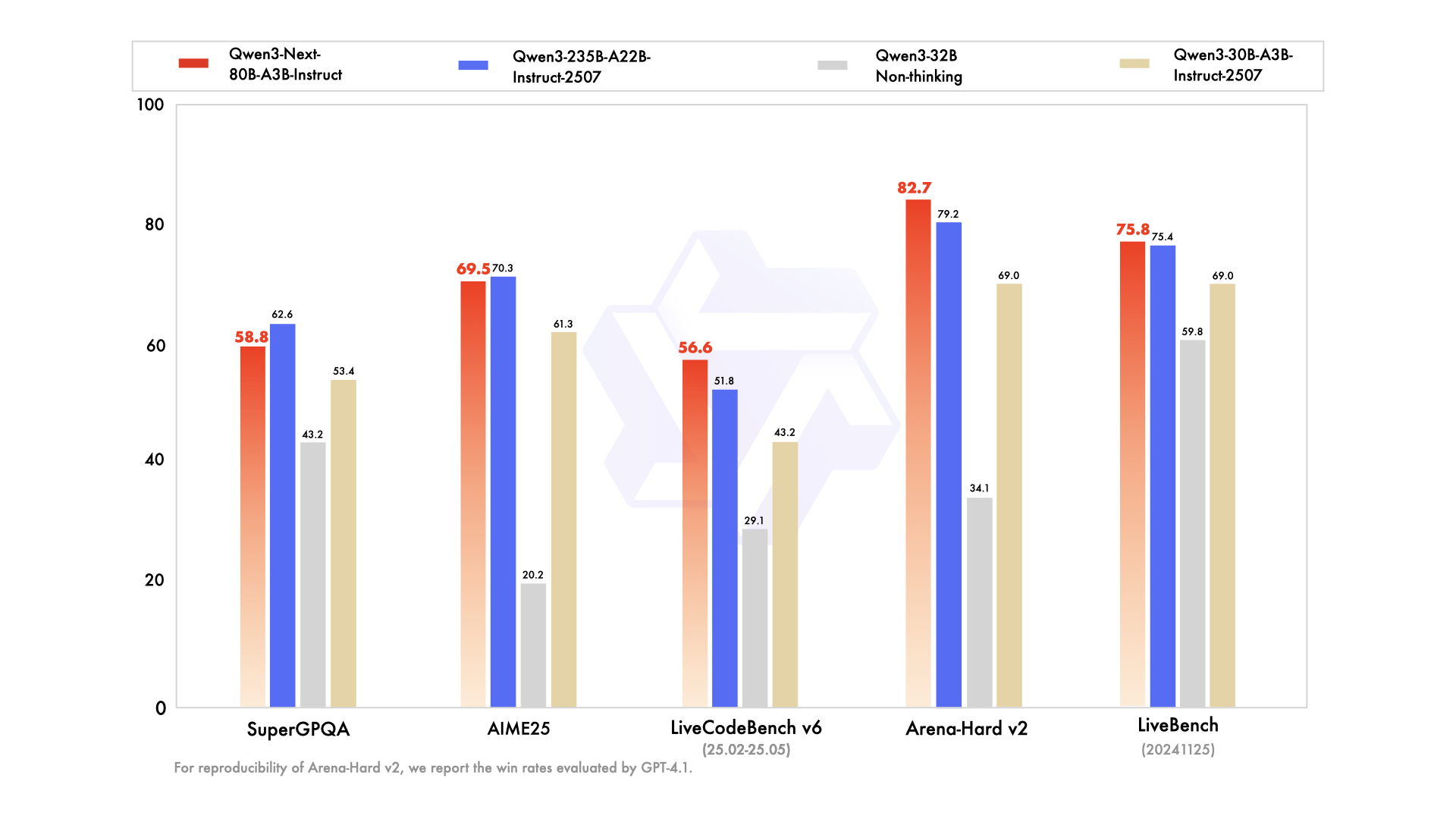 该图表对比展示了Qwen3-Next与系列前代模型的基准测试分数。从知识问答到代码生成的全维度评估中,80B型号展现出"以小胜大"的性能特征,尤其在超长上下文依赖任务中优势明显,印证了架构创新带来的效率提升。
该图表对比展示了Qwen3-Next与系列前代模型的基准测试分数。从知识问答到代码生成的全维度评估中,80B型号展现出"以小胜大"的性能特征,尤其在超长上下文依赖任务中优势明显,印证了架构创新带来的效率提升。
在知识能力评估中,MMLU-Pro得分80.6,MMLU-Redux达90.9,GPQA测试72.9分,均处于行业领先水平。推理能力方面,AIME25数学竞赛测试获得69.5分,HMMT25达到54.1分,LiveBench最新榜单以75.8分跻身第一梯队。
代码生成领域表现尤为突出,LiveCodeBench v6测试以56.6分超越多数同量级模型,MultiPL-E保持87.8的高准确率。对齐能力测试中,IFEval得87.6分,Arena-Hard v2挑战达成82.7分,展现出优异的指令遵循能力与价值观对齐水平。
值得注意的是,在创造性写作(Creative Writing v3:85.3分)与专业文书生成(WritingBench:87.3分)任务中,模型表现出接近人类专家的文本组织能力,这与其超长上下文处理能力形成协同效应。
技术突破与行业价值
Qwen3-Next系列的推出标志着大语言模型正式进入"高效智能"新阶段。通过混合注意力机制与稀疏激活技术的深度融合,该模型成功解决了传统架构中"参数规模-计算效率-上下文长度"的三角悖论。30亿激活参数实现2350亿参数量级模型的性能,不仅大幅降低部署成本,更为边缘计算、嵌入式设备等资源受限场景提供了可能性。
对于企业用户而言,256K原生上下文支持意味着可直接处理完整的法律文档、代码库、医疗记录等专业文本,无需复杂的分块处理逻辑。实测显示,在10万token技术文档问答任务中,模型保持92%的信息召回率,较传统模型提升40%以上。
随着模型仓库(https://gitcode.com/hf_mirrors/unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit)的开放,开发者可直接获取4位量化版本进行本地化部署。未来团队将持续优化架构设计,计划在下一代模型中实现100万token原生支持,并进一步提升多语言处理能力与工具调用效率,推动大语言模型在企业级应用场景的规模化落地。
Qwen3-Next的技术路径证明,通过架构创新而非单纯参数堆砌,AI模型能够以更低的计算资源消耗实现更强的智能能力。这种"绿色AI"发展模式,或将成为未来行业可持续发展的核心方向,引领人工智能技术从"规模竞赛"转向"效率竞争"的新阶段。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







