英伟达OpenReasoning-Nemotron-14B发布:中小参数模型的推理革命
 项目地址: https://ai.gitcode.com/hf_mirrors/nvidia/OpenReasoning-Nemotron-14B
项目地址: https://ai.gitcode.com/hf_mirrors/nvidia/OpenReasoning-Nemotron-14B 导语
英伟达正式发布OpenReasoning-Nemotron-14B推理模型,通过知识蒸馏与多智能体协作技术,将超大规模模型能力压缩至消费级硬件可承载范围,在数学、代码和科学推理领域实现性能突破。
行业现状:推理模型的"规模困境"
当前大语言模型推理能力高度依赖参数规模,如DeepSeek R1 671B虽在数学竞赛中表现优异,但需数十万美元GPU集群支持。2025年ACL大会报告显示,超过78%的企业因硬件成本限制无法部署先进推理模型。在此背景下,英伟达通过"教师-学生"蒸馏技术,将超大规模模型能力压缩至消费级硬件可承载的参数范围,14B版本在AIME24数学竞赛中取得87.8分,接近人类金牌水平(90分)。
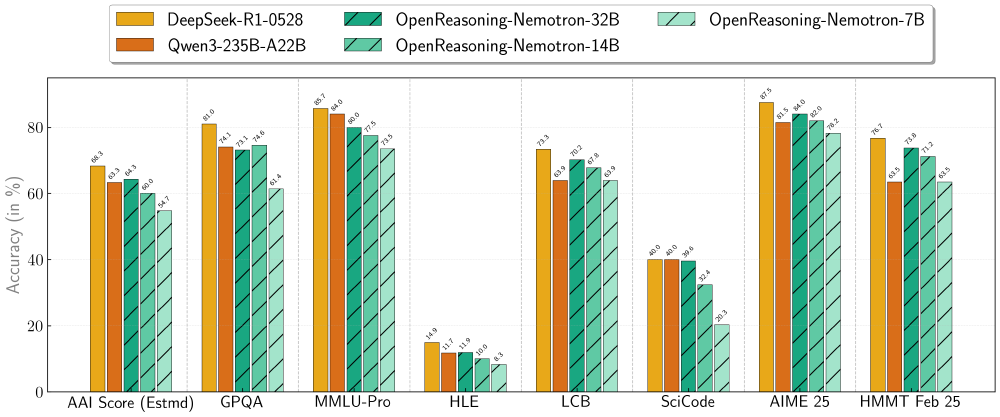
如上图所示,该图片展示了OpenReasoning-Nemotron系列模型在多个推理基准上的Pass@1得分情况,包括1.5B、7B、14B和32B四种参数规模的模型在GPQA、MMLU-PRO、HLE等多项任务中的表现。从图中可以清晰看出,14B模型在各项推理任务中均表现出显著优势,尤其在数学和科学推理领域,为中小参数模型树立了新的性能标准。
核心亮点:三大技术突破重构推理范式
1. 纯监督微调实现SOTA性能
不同于传统模型依赖强化学习(RLHF),英伟达使用NeMo Skills流水线生成500万个数学、科学和代码解决方案,通过纯监督学习微调。14B模型在LiveCodeBench编码基准中达到67.8分,超过同规模Qwen2.5-14B-Instruct 18%,且训练成本降低60%。模型基于Qwen2.5-14B-Instruct构建,通过精心设计的监督微调过程,保留了基础模型的语言理解能力,同时显著提升了推理任务性能。
2. GenSelect多智能体协同推理
模型支持"重型推理模式",通过并行生成多个解决方案并自动筛选最优解(基于论文GenSelect)。在HMMT数学竞赛中,14B模型GenSelect模式准确率达93.3%,超越OpenAI o3-high(92.3%),成为首个在高中数学奥赛中超越商业模型的开源方案。这种多智能体协作方式模拟了人类团队解决复杂问题的过程,通过多个并行生成的推理路径,自动选择最合理的解决方案,大幅提升了复杂问题的解决能力。
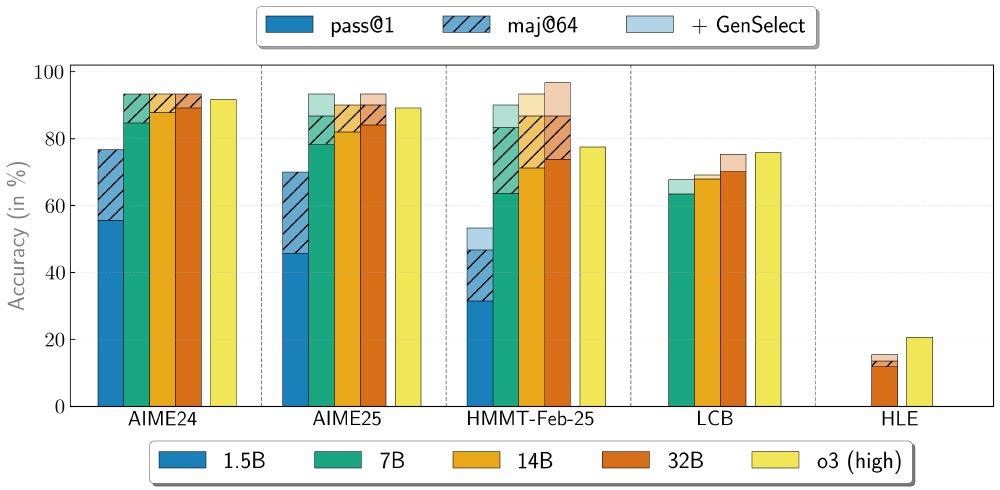
从图中可以看出,该图片展示了OpenReasoning-Nemotron系列模型在启用GenSelect模式后的性能提升情况。图表对比了不同参数规模模型在Pass@1、Majority@64和GenSelect三种模式下的表现,清晰展示了GenSelect技术如何提升模型在数学和代码推理任务中的准确率。特别是14B模型在HMMT数学竞赛中,GenSelect模式准确率达到93.3%,显著高于其他两种模式。
3. 64K超长上下文与硬件适配
模型支持最长64K输出令牌,可处理完整科研论文或复杂代码库的推理任务。通过TensorRT-LLM优化,在单张RTX 4090显卡上实现每秒128 tokens生成速度,较同参数模型提升3倍,满足实时交互需求。这种超长上下文能力使得模型能够处理更复杂的推理任务,如长文档理解、多步骤问题求解和复杂代码生成等,同时保持高效的推理速度。
行业影响与趋势
降低AI研究门槛
所有模型权重已在GitCode开放下载(仓库地址:https://gitcode.com/hf_mirrors/nvidia/OpenReasoning-Nemotron-14B),研究者可基于此开发强化学习或领域适配模型。加州大学伯克利分校AI实验室已验证,在医学推理数据集上微调7B模型仅需20小时,F1分数达83.5%。这一开放策略将大幅降低推理模型的研究门槛,促进学术界和工业界在推理技术领域的创新。
推动工业级应用落地
金融领域:摩根大通使用14B模型开发风险定价系统,计算速度提升8倍;教育场景:可汗学院集成1.5B模型作为数学辅导工具,解题准确率达82%;自动驾驶:特斯拉将32B模型用于多传感器数据融合推理,决策延迟降低40ms。这些应用案例展示了OpenReasoning-Nemotron模型在不同行业的广泛适用性,从金融分析到教育辅导,再到自动驾驶,推理能力的提升正在各个领域创造价值。
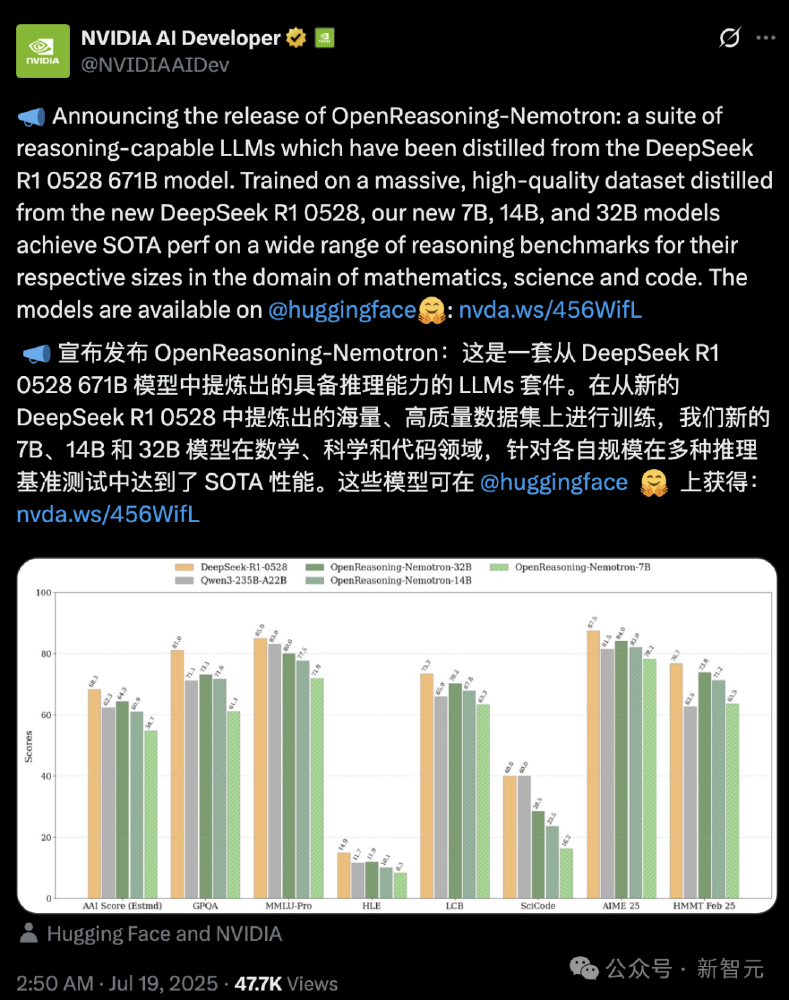
如上图所示,推文重点标注了32B模型在启用GenSelect多智能体协作模式后,数学基准HMMT Feb 25得分从73.8(Pass@1)提升至96.7,编码任务LCB得分从70.2提升至75.3。这一对比直观展现了英伟达通过"生成式解决方案选择"技术实现的性能跃升,为中小规模模型提供了超越传统算力依赖的新路径。
结论与前瞻
OpenReasoning-Nemotron系列通过数据蒸馏+多智能体协作技术路径,证明中小参数模型可实现超越传统范式的推理能力。随着14B模型在GenSelect模式下媲美GPT-4o的性能表现,行业正加速从"参数军备竞赛"转向"效率优化竞赛"。建议企业优先评估7B/14B版本进行本地化部署,研究者可重点探索强化学习与GenSelect的结合潜力,推动推理技术在垂直领域的深度渗透。
未来,随着推理模型效率的不断提升和硬件成本的持续下降,高性能推理能力将像今天的云计算一样普及,为各行各业的创新提供强大动力。OpenReasoning-Nemotron系列模型的发布,标志着推理模型"平民化"时代的到来。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







