Gemma 3:开源多模态轻量级模型,架构优化助力多任务性能显著提升
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/gemma-3-270m-it-qat-GGUF
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/gemma-3-270m-it-qat-GGUF 全文摘要
本文聚焦于Gemma 3这一多模态轻量级开放模型系列的新成员,其参数规模涵盖10亿至270亿。该模型在多模态理解、长上下文支持(至少128K tokens)以及多语言覆盖方面实现了显著改进。为应对长上下文引发的KV缓存内存爆炸问题,Gemma 3通过调整架构,增加局部注意力层与全局注意力层的比例,并缩短局部注意力层作用范围。同时,采用知识蒸馏技术训练,后训练阶段运用新方法提升数学、对话、指令跟随和多语言能力。实验表明,Gemma 3 - 4B - IT在多项基准测试中超越Gemma 2 - 27B - IT,Gemma 3 - 27B - IT可与Gemini - 1.5 - Pro比肩,且所有Gemma 3模型均已开源。
论文方法
模型架构
Gemma 3基于Transformer的decoder - only架构,与Gemma 2类似但有诸多改进。在层次结构上,增加了本地到全局注意力层的比例,保持局部注意力短跨度,支持128K长度的长序列,通过巧妙设计减少内存需求。这种架构变化有效解决了长上下文带来的KV缓存内存爆炸问题,使得模型在处理长序列时更加高效。
训练方法
- 预训练:基于知识蒸馏,采用与Gemma 2相似的优化配方,包括数据混合和tokenizer等。通过知识蒸馏,模型能够从已有知识中学习,提升自身性能。
- 后训练:侧重于提升数学、推理、聊天等功能,并结合新添加的图像输入能力。后训练阶段的改进进一步增强了模型在特定领域的能力,使其更加全面和实用。
论文实验
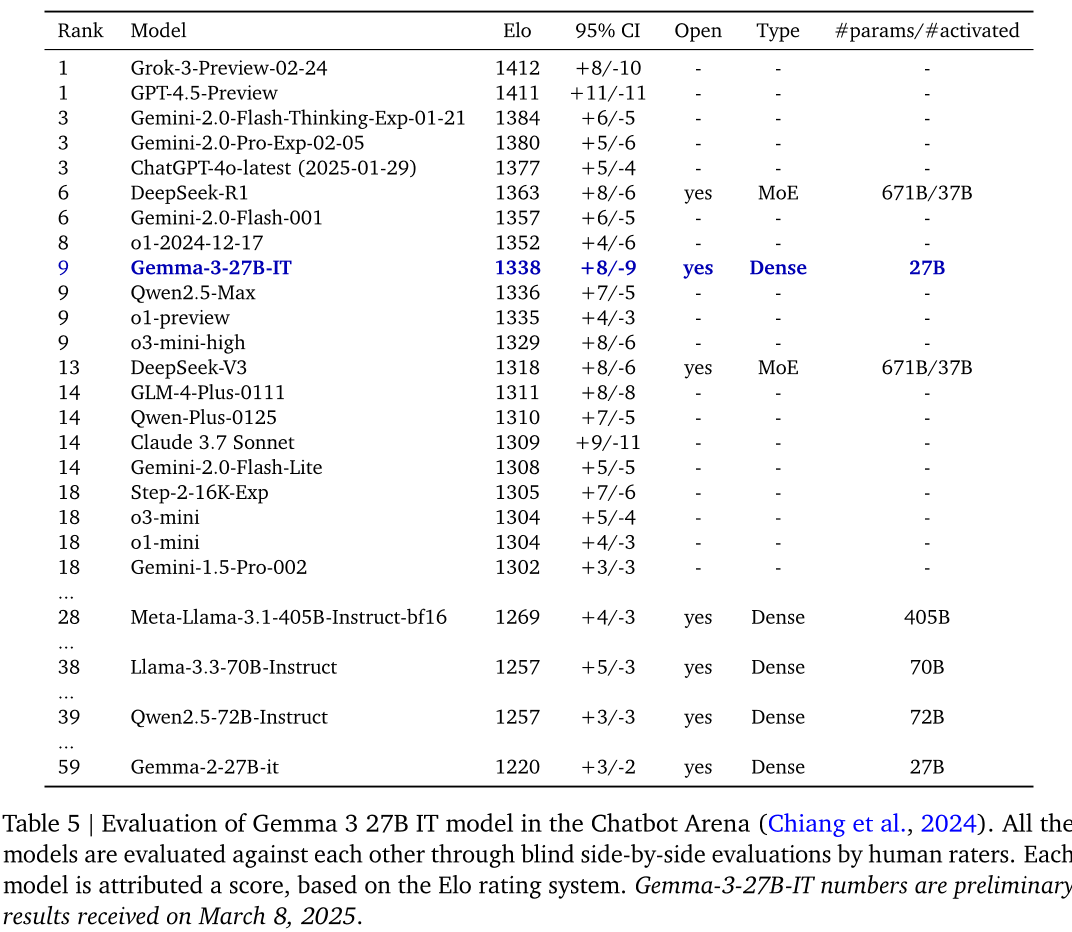
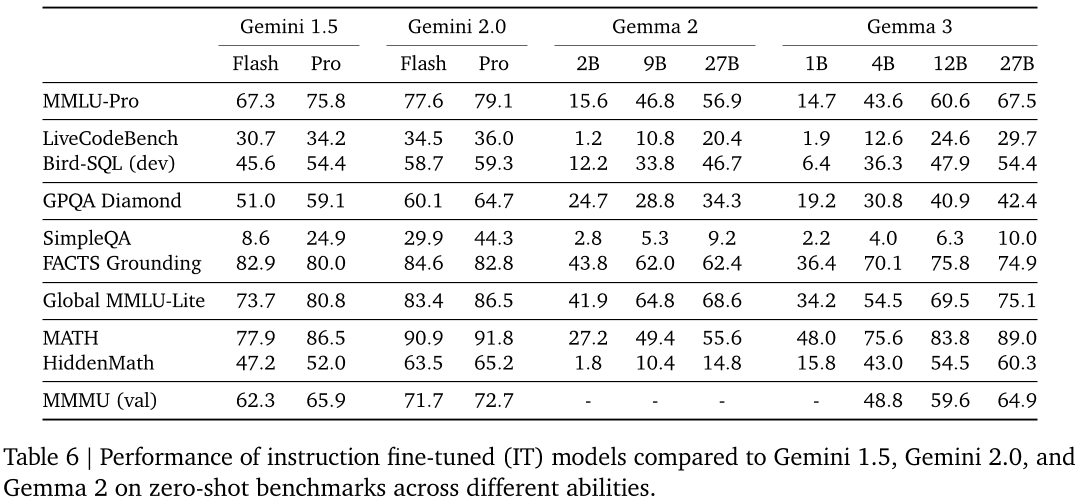
本文对Gemma 3进行了全面的性能评估。在多种量化和质化基准上进行对比测试,结果显示其表现优于或接近竞争对手。例如,在LMSYS Chatbot Arena评价中,Gemma 3 27B IT模型使用Elo评分系统得分为1338分,高于DeepSeek - V3 (1318)、LLaMA 3 405B (1257) 和Qwen2.5 - 70B (1257)。在标准基准测试中,Gemma 3 27B在MMLU - Pro上得分为67.5%,LiveCodeBench上为29.7%,Bird - SQL (dev)上为54.4%。此外,还包括多领域标准基准测试,充分展示了Gemma 3在不同任务和领域中的优秀性能。
论文总结
文章优点
本文提出的Gemma 3是Gemma家族中用于文本、图像和代码理解的最新开放型多模态模型。其主要优点包括添加了图像理解支持,提升了多语种能力和STEM相关能力。作者依据标准硬件设计模型大小和架构,并针对该硬件进行了大部分架构优化,同时保持了高性能。此外,论文详细阐述了模型的架构、预训练和后训练配方,提供了广泛的定量和定性基准测试评估,还讨论了Gemma 3的安全部署方法及其局限性和优势的更广泛影响。
方法创新点
- 增加上下文大小至128K个标记且不降低性能。通过在每个全局层之间插入多个本地层,并为本地层分配仅1024个标记的小跨度,解决长上下文引起的KV缓存内存爆炸问题,使全局层与本地层比例为1:5。
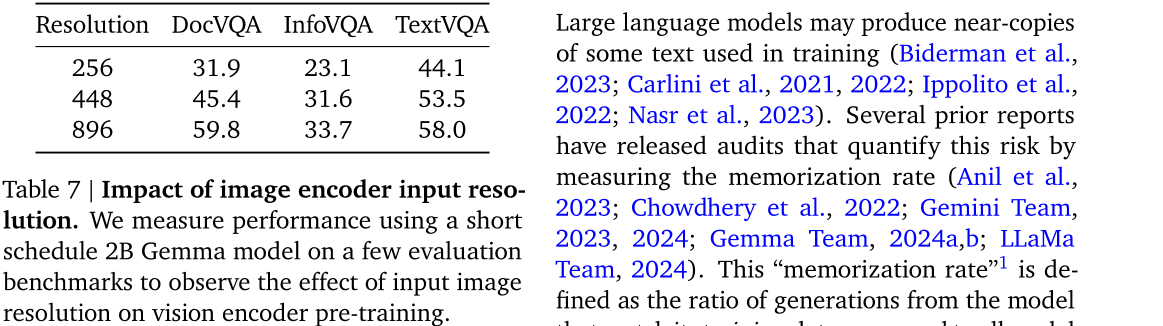
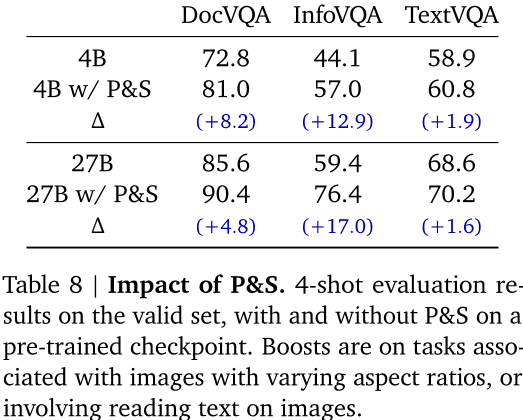
- 处理图像时使用定制版的SigLIP视觉编码器,将图像视为由SigLIP编码的软令牌序列,通过压缩视觉嵌入向量为固定大小的256维向量,减少图像处理的推断成本。
未来展望
Gemma 3的推出为自然语言处理领域带来巨大潜力,其强大的多模态能力和广泛适应性适用于多种任务,如数学推理、聊天机器人、指令遵循等。然而,该模型仍存在一些限制,如训练和推断需要大量计算资源和数据集。未来研究可探索解决这些问题的方法,进一步提升Gemma 3的性能和应用范围。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







